 |

Database
Management System
(CS403)
VU
Lecture No.
42
Reading
Material
"Database
Systems Principles, Design
and Implementation" written by
Catherine Ricardo,
Maxwell
Macmillan.
"Database
Management System" by Jeffery A
Hoffer
Overview of
Lecture
Transaction
Management
o
The
Concept of a Transaction
o
Transactions
and Schedules
o
Concurrent
Execution of Transactions
o
Need
for Concurrency
Control
o
Serializability
o
Locking
o
Deadlock
o
A
transaction is defined as any
one execution of a user
program in a DBMS and
differs
from an execution of a program
outside the DBMS (e.g., a C
program
executing
on Unix) in important ways.
(Executing the same program
several times
will generate
several transactions.)
For
performance reasons, a DBMS
has to interleave the
actions of several
transactions.
However,
to give users a simple way
to understand the effect of
running their
programs,
the interleaving is done
carefully to ensure that the
result of a concurrent
execution
of transactions is nonetheless equivalent
(in its effect upon
the database) to
some
serial, or one-at-a-time, execution of
the same set of
transactions.
The
Concept of a Transaction
A user
writes data access/update
programs in terms of the high-level
query and up-
date
language supported by the
DBMS. To understand how the
DBMS handles such
requests,
with respect to concurrency
control and recovery, it is
convenient to regard
an
execution of a user program, or
transaction, as a series of reads
and writes of
database
objects:
293

Database
Management System
(CS403)
VU
�
To read a
database object, it is first
brought into main memory
(specifically,
some
frame in the buffer pool)
from disk, and then
its value is copied into
a
program
variable.
�
To write
a database object, an in-memory
copy of the object is first
modified
and
then written to disk.
Database
`objects' are the units in
which programs read or write
information. The
units
could be pages, records, and so
on, but this is dependent on
the DBMS and is
not
central
to the principles underlying
concurrency control or recovery. In
this chapter,
we will
consider a database to be a fixed
collection of independent
objects.
There
are four important
properties of transactions that a
DBMS must ensure to
maintain
data in the face of concurrent access
and system failures:
�
Users
should be able to regard the
execution of each transaction as
atomic:
either
all actions are carried
out or none are. Users
should not have to
worry
about
the effect of incomplete
transactions (say, when a system
crash occurs).
�
Each
transaction, run by itself
with no concurrent execution of
other
transactions, must
preserve the consistency of the
database. This property
is
called
consistency, and the DBMS
assumes that it holds for
each transaction.
Ensuring
this property of a transaction is
the responsibility of the
user.
�
Users
should be able to understand a
transaction without considering
the effect
of other
concurrently executing transactions,
even if the DBMS interleaves
the
actions
of several transactions for
performance reasons. This
property is
sometimes
referred to as isolation: Transactions
are isolated, or
protected,
from
the effects of concurrently
scheduling other transactions.
�
Once
the DBMS informs the
user that a transaction has
been successfully
completed,
its effects should persist
even if the system crashes
before all its
changes
are reflected on disk. This
property is called
durability.
The
acronym ACID is sometimes used to refer
to the four properties of
transactions
which
are presented here: atomicity,
consistency, isolation and
durability.
Transactions
and Schedules
294

Database
Management System
(CS403)
VU
A
transaction is seen by the
DBMS as a series, or list, of
actions. The actions that
can
be
executed by a transaction include
reads and writes of database
objects. A
transaction
can also be defined as a set of
actions that are partially
ordered. That is,
the
relative order of some of
the actions may not be
important. In order to
concentrate
on the
main issues, we will treat transactions
(and later, schedules) as a list of
actions.
Further,
to keep our notation simple,
we'll assume that an object
O is always read into
a program
variable that is also named O. We
can therefore denote the
action of a
transaction
T reading an object O as RT (O);
similarly, we can denote
writing as WT
(O).
When the transaction T is
clear from the context, we
will omit the
subscript.
A schedule is a
list of actions (reading,
writing, aborting, or committing)
from a set of
transactions,
and the order in which
two actions of a transaction T appear in
a
schedule must be
the same as the order in
which they appear in T. Intuitively,
a
schedule
represents an actual or potential
execution sequence. For
example, the
schedule in
Figure below shows an
execution order for actions
of two transactions T1
and
T2. We move forward in time
as we go down from one row
to the next. We
emphasize
that a schedule describes the
actions of transactions as seen by the
DBMS.
In
addition to these actions, a
transaction may carry out
other actions, such as
reading
or
writing from operating
system files, evaluating
arithmetic expressions, and so
on.
Concurrent
Execution of Transactions
The
DBMS interleaves the actions
of different transactions to improve
performance,
in terms
of increased throughput or improved
response times for short
transactions,
but
not all interleaving should
be allowed.
Ensuring
transaction isolation while
permitting such concurrent
execution is difficult
but is
necessary for performance
reasons. First, while one
transaction is waiting for
a
page to be read in
from disk, the CPU
can process another
transaction. This is
because
I/O
activity can be done in
parallel with CPU activity
in a computer. Overlapping
I/O
and
CPU activity reduces the
amount of time disks and
processors are idle,
and
increases
system throughput (the average
number of transactions completed in a
given
time).
Second, interleaved execution of a short
transaction with a long
transaction
usually
allows the short transaction
to complete quickly. In serial
execution, a short
295

Database
Management System
(CS403)
VU
transaction
could get stuck behind a
long transaction leading to
unpredictable delays
in
response time, or average
time taken to complete a
transaction.
Figure:
Transaction Scheduling
Serializability
To begin
with, we assume that the
database designer has
defined some notion of
a
consistent
database state. For example,
we can define a consistency
criterion for a
university
database to be that the sum
of employee salaries in each department
should
be less
than 80 percent of the
budget for that department.
We require that each
transaction
must preserve database consistency; it
follows that any serial
schedule that
is
complete will also preserve database consistency.
That is, when a complete
serial
schedule is
executed against a consistent database,
the result is also a
consistent
database.
A
serializable schedule over a set S of
committed transactions is a schedule whose
effect on
any consistent database instance is
guaranteed to be identical to that of
some
complete
serial schedule over S. That
is, the database instance
that results from
executing
the given schedule is identical to
the database instance that results
from
executing
the transactions in some serial
order. There are some
important points to
note in
this definition:
�
Executing
the transactions serially in
different orders may produce
different
results,
but all are presumed to be acceptable;
the DBMS makes no
guarantees
about
which of them will be the
outcome of an interleaved
execution.
�
The
above definition of a serializable
schedule does not cover the
case of
schedules
containing aborted transactions
If a
transaction computes a value and
prints it to the screen,
this is an `effect'
�
that is
not directly captured in the
state of the database. We will
assume that
all
such values are also
written into the database,
for simplicity.
296

Database
Management System
(CS403)
VU
Lock-Based
Concurrency Control
A DBMS
must be able to ensure that
only serializable, recoverable
schedules are
allowed,
and that no actions of
committed transactions are lost
while undoing aborted
transactions. A
DBMS typically uses a
locking protocol to achieve
this. A locking
protocol
is a set of rules to be followed by
each transaction (and
enforced by the
DBMS), in
order to ensure that even
though actions of several
transactions might be
interleaved,
the net effect is identical
to executing all transactions in some
serial order.
Strict
Two-Phase Locking (Strict
2PL)
The most
widely used locking
protocol, called Strict
Two-Phase Locking, or
Strict
2PL,
has two rules.
The
first rule is
If a
transaction T wants to read
(respectively, modify) an object, it
first requests a
shared
(respectively, exclusive) lock on
the object. Of course, a
transaction that has
an
exclusive
lock can also read the
object; an additional shared
lock is not required.
A
transaction
that requests a lock is
suspended until the DBMS is
able to grant it the
requested
lock. The DBMS keeps
track of the locks it has
granted and ensures that if
a
transaction
holds an exclusive lock on an
object, no other transaction
holds a shared
or
exclusive lock on the same
object. The second rule in
Strict 2PL is:
All locks
held by a transaction are released
when the transaction is
completed.
Requests
to acquire and release locks
can be automatically inserted
into transactions
by the
DBMS; users need not worry
about these details. In
effect the locking
protocol
allows
only `safe' interleaving of transactions.
If two transactions access
completely
independent
parts of the database, they will be
able to concurrently obtain
the locks
that
they need and proceed
merrily on their ways. On
the other hand, if
two
transactions
access the same object,
and one of them wants to
modify it, their
actions
are
effectively ordered serially
all actions of one of these
transactions (the one
that
gets
the lock on the common
object first) are completed
before (this lock is
released
and)
the other transaction can
proceed.
We denote
the action of a transaction T
requesting a shared (respectively,
exclusive)
lock on
object O as ST (O) (respectively, XT
(O)), and omit the
subscript denoting
the
transaction
when it is clear from the
context. As an example, consider
the schedule
shown in
Figure below.
297

Database
Management System
(CS403)
VU
Figure
reading uncommitted
Data
This
interleaving could result in a
state that cannot result
from any serial execution
of
the
three transactions. For instance, T1
could change A from 10 to 20,
then T2 (which
reads
the value 20 for A) could
change B from 100 to 200,
and then T1 would
read
the
value 200 for B. If run
serially, either T1 orT2
would execute first, and
read the
values 10
for A and 100 for B:
Clearly, the interleaved
execution is not equivalent
to
either
serial execution. If the
Strict 2PL protocol is used,
the above interleaving
is
disallowed.
Let us see why. Assuming
that the transactions proceed at the
same
relative
speed as before, T1 would
obtain an exclusive lock on A
first and then read
and
write A (figure below) Then,
T2 would request a lock on A. However,
this
request
cannot be granted until T1
releases its exclusive lock
on A, and the DBMS
therefore
suspends T2. T1 now proceeds
to obtain an exclusive lock on B,
reads and
writes B,
then finally commits, at
which time its locks
are released. T2's lock
request
is now
granted, and it proceeds. In this
example the locking protocol
results in a serial
execution
of the two transactions. In
general, however, the
actions of different
transactions
could be interleaved. As an example,
consider the interleaving of
two
transactions
shown in Figure below, which
is permitted by the Strict
2PL protocol.
Figure:
Schedule illustrating strict
2PL.
298
Database
Management System
(CS403)
VU
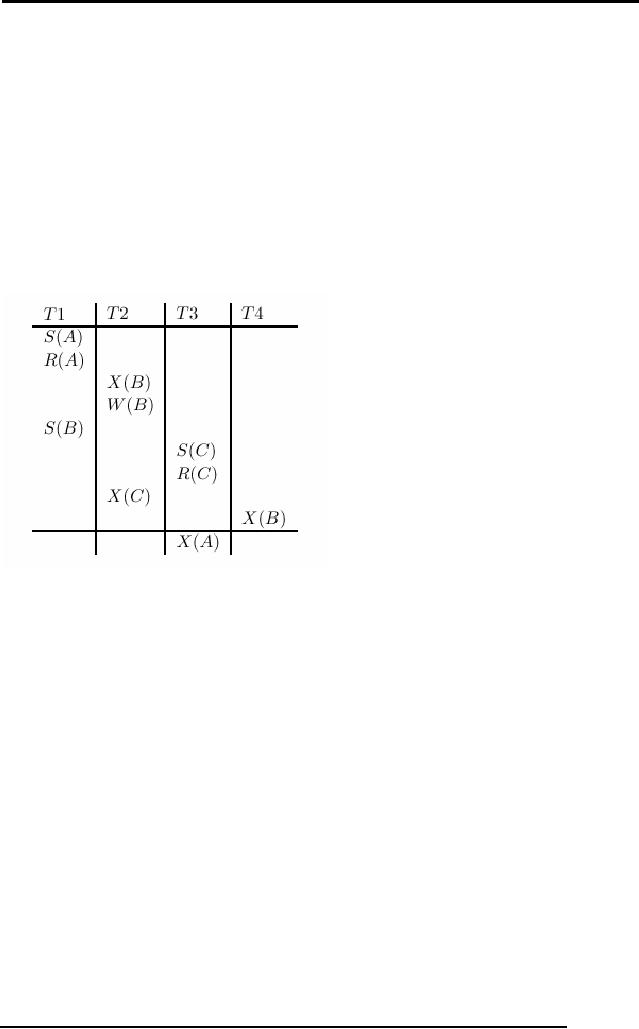
Deadlocks
Consider
the following example:
transaction T1 gets an exclusive
lock on object A,
T2 gets
an exclusive lock on B, T1 requests an
exclusive lock on B and is
queued, and
T2
requests an exclusive lock on A
and is queued. Now, T1 is
waiting for T2 to
release
its lock and T2 is waiting
for T1 to release its lock!
Such a cycle of
transactions
waiting for locks to be released is
called a deadlock. Clearly,
these two
transactions will
make no further progress. Worse,
they hold locks that
may be
required
by other transactions. The
DBMS must either prevent or detect
(and resolve)
such
deadlock situations.
Figure
:Schedule Illustrating
Deadlock
Deadlock
Prevention
We can
prevent deadlocks by giving
each transaction a priority
and ensuring that
lower
priority transactions are
not allowed to wait for
higher priority transactions
(or
vice
versa). One way to assign
priorities is to give each
transaction a timestamp
when
it starts
up. The lower the
timestamp, the higher the
transaction's priority, that is,
the
oldest
transaction has the highest
priority.
If a
transaction Ti requests a lock
and transaction Tj holds a
conflicting lock, the
lock
manager
can use one of the
following two
policies:
�
Wait-die:
If Ti has higher priority, it is
allowed to wait; otherwise it is
aborted.
�
Wound-wait:
If Ti has higher priority,
abort Tj; otherwise Ti
waits.
In the
wait-die scheme, lower
priority transactions can never
wait for higher
priority
transactions. In
the wound-wait scheme,
higher priority transactions
never wait for
lower
priority transactions. In either
case no deadlock cycle can
develop.
299

Database
Management System
(CS403)
VU
A subtle
point is that we must also
ensure that no transaction is
perennially aborted
because
it never has a sufficiently
high priority. (Note that in
both schemes, the
higher
priority
transaction is never aborted.)
When a transaction is aborted
and restarted, it
should be
given the same timestamp
that it had originally.
Reissuing timestamps in
this
way ensures that each
transaction will eventually become the
oldest transaction,
and
thus the one with
the highest priority, and
will get all the
locks that it
requires.
The
wait-die scheme is non-preemptive;
only a transaction requesting a
lock can be
aborted.
As a transaction grows older
(and its priority
increases), it tends to wait
for
more
and more young transactions.
A younger transaction that
conflicts with an
older
transaction
may be repeatedly aborted (a
disadvantage with respect to
wound wait),
but on
the other hand, a
transaction that has all
the locks it needs will
never be aborted
for
deadlock reasons (an
advantage with respect to
wound-wait, which is
preemptive).
Deadlock
Detection
Deadlocks
tend to be rare and typically
involve very few
transactions. This
observation
suggests that rather than
taking measures to prevent
deadlocks, it may be
better to
detect and resolve deadlocks as
they arise. In the detection
approach, the
DBMS must
periodically check for
deadlocks. When a transaction Ti is
suspended
because a
lock that it requests cannot
be granted, it must wait until
all transactions Tj
that
currently hold conflicting
locks release them.
The
lock manager maintains a structure
called a waits-for graph to
detect deadlock
cycles.
The nodes correspond to
active transactions, and there is an
arc from Ti to Tj
if (and
only if) Ti is waiting for
Tj to release a lock. The
lock manager adds edges
to
this
graph when it queues lock
requests and removes edges
when it grants lock
requests.
Detection
versus Prevention
In
prevention-based schemes, the
abort mechanism is used preemptively in
order to
avoid
deadlocks. On the other
hand, in detection-based schemes,
the transactions in a
deadlock
cycle hold locks that
prevent other transactions from
making progress.
System
throughput is reduced because
many transactions may be blocked,
waiting to
obtain
locks currently held by
deadlocked transactions.
This is
the fundamental trade-off
between these prevention and
detection approaches
to
deadlocks: loss of work due
to preemptive aborts versus loss of
work due to
300

Database
Management System
(CS403)
VU
blocked
transactions in a deadlock cycle. We can
increase the frequency with
which
we check
for deadlock cycles, and
thereby reduce the amount of
work lost due to
blocked
transactions, but this
entails a corresponding increase in the
cost of the
deadlock
detection mechanism.
A variant
of 2PL called Conservative
2PL can also prevent
deadlocks. Under
Conservative
2PL, a transaction obtains
all the locks that it will
ever need when it
begins,
or blocks waiting for these
locks to become available. This
scheme ensures
that
there will not be any
deadlocks, and, perhaps more
importantly, that a
transaction
that
already holds some locks
will not block waiting for
other locks. The trade-o_
is
that a
transaction acquires locks earlier. If
lock contention is low,
locks are held
longer
under Conservative 2PL. If
lock contention is heavy, on
the other hand,
Conservative
2PL can reduce the time
that locks are held on
average, because
transactions
that hold locks are
never blocked.
301
Table of Contents:
- Introduction to Databases and Traditional File Processing Systems
- Advantages, Cost, Importance, Levels, Users of Database Systems
- Database Architecture: Level, Schema, Model, Conceptual or Logical View:
- Internal or Physical View of Schema, Data Independence, Funct ions of DBMS
- Database Development Process, Tools, Data Flow Diagrams, Types of DFD
- Data Flow Diagram, Data Dictionary, Database Design, Data Model
- Entity-Relationship Data Model, Classification of entity types, Attributes
- Attributes, The Keys
- Relationships:Types of Relationships in databases
- Dependencies, Enhancements in E-R Data Model. Super-type and Subtypes
- Inheritance Is, Super types and Subtypes, Constraints, Completeness Constraint, Disjointness Constraint, Subtype Discriminator
- Steps in the Study of system
- Conceptual, Logical Database Design, Relationships and Cardinalities in between Entities
- Relational Data Model, Mathematical Relations, Database Relations
- Database and Math Relations, Degree of a Relation
- Mapping Relationships, Binary, Unary Relationship, Data Manipulation Languages, Relational Algebra
- The Project Operator
- Types of Joins: Theta Join, Equi–Join, Natural Join, Outer Join, Semi Join
- Functional Dependency, Inference Rules, Normal Forms
- Second, Third Normal Form, Boyce - Codd Normal Form, Higher Normal Forms
- Normalization Summary, Example, Physical Database Design
- Physical Database Design: DESIGNING FIELDS, CODING AND COMPRESSION TECHNIQUES
- Physical Record and De-normalization, Partitioning
- Vertical Partitioning, Replication, MS SQL Server
- Rules of SQL Format, Data Types in SQL Server
- Categories of SQL Commands,
- Alter Table Statement
- Select Statement, Attribute Allias
- Data Manipulation Language
- ORDER BY Clause, Functions in SQL, GROUP BY Clause, HAVING Clause, Cartesian Product
- Inner Join, Outer Join, Semi Join, Self Join, Subquery,
- Application Programs, User Interface, Forms, Tips for User Friendly Interface
- Designing Input Form, Arranging Form, Adding Command Buttons
- Data Storage Concepts, Physical Storage Media, Memory Hierarchy
- File Organizations: Hashing Algorithm, Collision Handling
- Hashing, Hash Functions, Hashed Access Characteristics, Mapping functions, Open addressing
- Index Classification
- Ordered, Dense, Sparse, Multi-Level Indices, Clustered, Non-clustered Indexes
- Views, Data Independence, Security, Vertical and Horizontal Subset of a Table
- Materialized View, Simple Views, Complex View, Dynamic Views
- Updating Multiple Tables, Transaction Management
- Transactions and Schedules, Concurrent Execution, Serializability, Lock-Based Concurrency Control, Deadlocks
- Incremental Log with Deferred, Immediate Updates, Concurrency Control
- Serial Execution, Serializability, Locking, Inconsistent Analysis
- Locking Idea, DeadLock Handling, Deadlock Resolution, Timestamping rules