 |
The Basic Concept of Data Warehousing |
| << Why a DWH, Warehousing |
| Classical SDLC and DWH SDLC, CLDS, Online Transaction Processing >> |
Lecture
Handout
Data
Warehousing
Lecture
No. 03
It is a
blend of many technologies,
the basic concept
being:
�
Take
all data from different
operational systems.
�
If necessary,
add relevant data from
industry.
�
Transform
all data and bring
into a uniform
format.
�
Integrate all
data as a single entity.
�
Store
data in a format supporting easy
access for decision
support.
�
Create
performance enhancing indices.
�
Implement performance
enhancement joins.
�
Run
ad-hoc queries with low
selectivity.
A Data
Warehouse is not something shrink-wrapped
i.e. you take a set of
CDs and install into
a
box and
soon you have a Data Warehouse up
and running. A Data Warehouse
evolves over time,
you don't buy
it. Basically it is about taking/collecting
data from different
heterogeneous sources.
Heterogeneous
means not only the operating
system is different but so is the
underlying file
format,
different databases, and
even with same database
systems different representations
for the
same entity.
This could be anything from
different columns names to
different data types for
the
same
entity.
Companies
collect and record their own operational
data, but at the same time
they also use
reference data
obtained from external sources such as
codes, prices etc. This is
not the only
external
data, but customer lists
with their contact information
are also obtained from
external
sources.
Therefore, all this external
data is also added to the
data warehouse.
As mentioned
earlier, even the data collected
and obtained from within
the company is not
standard
for a host of different
reasons. For example,
different operational systems being used
in
the
company were developed by different vendors
over a period of time, and
there is no or
minimal
evenness in data representation
etc. When that is the
state of affairs (and is
normal)
within a
company, then there is no
control on the quality of
data obtained from external
sources.
Hence
all the data has to be
transformed into a uniform format,
standardized and integrated
before
it c an go into
the data warehouse.
In a decision
support environment, the end
user i.e. the decision
maker is interested in the
big
picture. Typical
DSS queries do not involve
using a primary key or
asking questions about
a
12
particular
customer or account. DSS
queries deal with number of variables
spanning across
number of tables
(i.e. join operations) and
looking at lots of historical data. As a
result large
number of
records are processed and
retrieved. For such a case,
specialized or different
database
architectures/topologies
are required, such as the
star schema. We will cover
this in detail in the
relevant
lecture.
Recall
that a B-Tree is a data structure
that supports dictionary operations. In
the context of a
database, a
B-Tree is used as an index that provides
access to records without
actually scanning
the entire
table. However, for very
large databases the corresponding B Trees
becomes very
-
large. Typically
the node of a B-Tree is stored in a
memory block, and traversing a
B-Tree
involves
O(log n) page faults. This is
highly undesirable, because by
default the height of the B
-
Tree
would be very large for very
large data bases. Therefore,
new and unique
indexing
techniques
are required in the DWH or
DSS environment, such as bitmapped
indexes or cluster
index etc. In
some cases the designers
want such powerful indexing
techniques, that the
queries
are
satisfied from the indexes
without going to the fact
tables.
In typical OLTP
environments, the size of tables
are relatively small, and
the rows of interes t
are
also
very small, as the queries
are confined to specifics.
Hence traditional joins such as
nested -
loop
join of quadratic time complexity does
not hurt the performance i.e. time to
get the answer.
However,
for very large databases
when the table sizes are in
millions and the rows of
interest are
also in
hundreds of thousands, nested-loop
join becomes a bottle neck
and is hardly used.
Therefore,
new and unique forms of joins
are required such as sort
-merge join or hash based
join
etc.
Run
Ad-Hoc queries with low
Selectivity
Have
already explained what is meant by ad
-hoc queries. A little bit
about selectivity is in order.
Selectivity is
the ratio between the number
of unique values in a column divided by the
total
number of values in
that column. For example the
selectivity of the gender column is
50%,
assuming
gender of all customers is known. If
there are N records in a
table, then the
selectivity
of the
primary key column is 1/N. Note
that a query consists of retrieving
records based on a a
combination of
different columns, hence the
choice of columns determine the
selectivity of the
query i.e.
the number of records retrieved
divided by the total number of records
present in the
table.
In an OLTP
(On-Line Transaction Processing) or
MIS (Management Information
System)
environment,
the queries are typically
Primary Key (PK) based,
hence the number of
records
retrieved is not
more than a hundred rows. Hence the
selectivity is very high. For a
Data
Warehouse
(DWH) environment, we are interested in
the big picture and have
queries that are not
very
specific in nature and hardly
use a PK. As a result
hundreds of thousands of records
(or
rows)
are retrieved from very
large tables. Thus the ratio of
records retrieved to the total
number
of records
present is high, and hence
the selectivity is low.
How is it
different?
Decision
making is Ad-Hoc
13
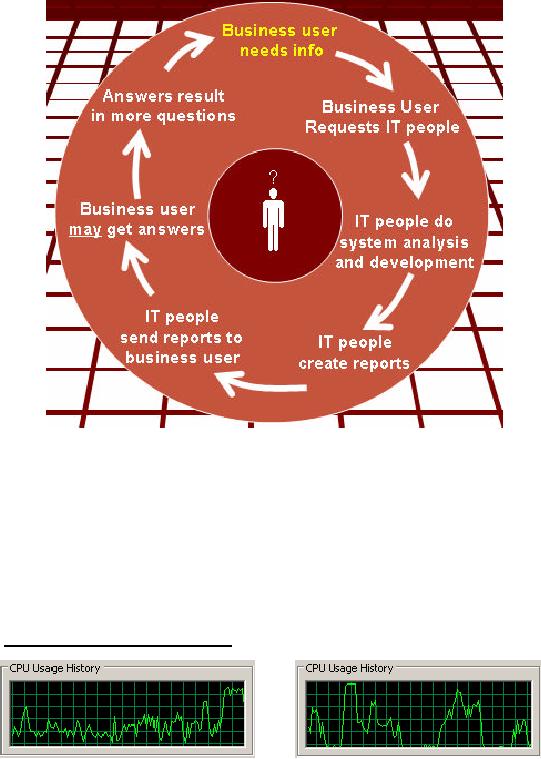
Figure-3.1:
Running in circles
Consider a
decision maker or a business
user who wants some of
his questions to be
answered.
He/she
sets a meeting with the IT
people, and explains the
requirements. The IT people go
over
the
cycle of system analysis and
design, that takes anywhere
from couple of weeks to
couple of
months
and they finally design
and develop the system.
Happy and proud with their
achievement
the IT
people go to the business
user with the reporting
system or MIS system. After
a learning
curve
the business users spends
some time with the brand new
system, and may get
some answers
to the required
questions. But then those
answers results in more questions.
The business user
has
no choice to
meet the IT people with a
new set of requirements. The
business user is frustrated
that
his questions are not getting
answered, while the IT
people are frustrated that
the business
user
always changes the
requirements. Both are
correct in their frustration.
Different
patterns of hardware utilization
100%
0%
Operational
DWH
14
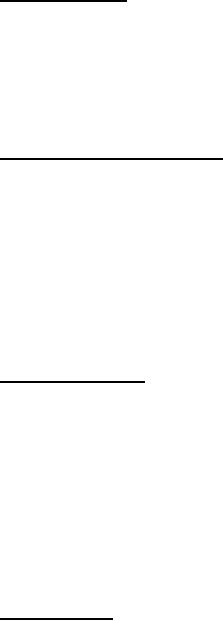
Figure-3.2:
Different patterns of CPU
Usage
Although
there are peaks and valleys
in the operational processing, but
ultimately there is
relativ ely
static pattern of utilization. There is
an essentially different pattern of
hardware
utilization in
the data warehouse
environment i.e. a binary
pattern of utilization, either
the
hardware is
utilized fully or not at all. Calculating
a mean utilization for a DWH
is not a
meaningful
activity. Therefore, trying to
mix the two environments is a
recipe for disaster.
You
can optimize
the machine for the
performance of one type of
application, not for
both.
Bus vs.
Train Analogy
Consider the
analogy of a bus and train. I
believe you can find dozens
of buses operating between
Lahore
and Rawalpindi almost every
30 minutes. As a consequence, literally
there are buses
moving
between Lahore and
Rawalpindi almost continuously through out
the day. But how
many
times a
dedicated train moves
between the two cities?
Only twice a day and carries
a bulk of
passengers
and cargo. Binary operation
i.e. either traveling or not.
The train can NOT
be
optimized for
every 30-min travel, it will
never fill to capacity and
run into loss. A bus
can not be
optimized to
travel only twice, it will
stand idle and passengers
would take vans etc. Bottom
line:
Two
modes of transportation, can
not be interchanged.
Combines
historical & Operational Data
�
Don't do
data entry into a DWH,
OLTP or ERP are the
source systems.
�
OLTP
systems don't keep history,
cant get balance statement
more than a year old.
�
DWH
keep historical data, even of
bygone customers.
Why?
�
In the
context of bank, want to know
why the customer
left?
�
What were
the events that led to
his/her leaving? Why?
�
Customer
retention.
Why
keep historical data?
The
data warehouse is different
because, again it's not a
database you do data entry.
You are
actually collecting
data from the operational
systems and loading into
the DWH. So the
transactional
processing systems like the
ERP system are the
source systems for the
data
warehouse.
You feed the data into
the data warehouse. And
the data warehouse typically
collects
data
over a period of time. So if you
look at your transactional
processing OLTP
systems,
normally
such systems don't keep
very much history. Normally
if a customer leaves or
expired,
the
OLTP systems typically purge
the data associated with
that customer and all
the transactions
off
the database after some amo
unt of time. So normally once a
year most business will
purge the
database of
all the old customers
and old transactions. In the
data warehouse we save
the
historical data.
Because you don't need historical
data to do business today, but you do
need the
historical data
to understand patterns of business
usage to do business tomorrow,
such why a
customer
left?
How
much History?
�
Depends
on:
15

�
Industry.
�
Cost of storing
historical data.
�
Economic
value of historical data.
�
Industries
and history
� Telecomm
calls
are much much more as
compared to bank transactions -
18
months of
historical data.
�
Retailers
interested in
analyzing yearly seasonal patterns - 65
weeks of historical
data.
�
Insurance
companies want
to do actuary analysis, use
the historical data in
order
to predict risk-
7 years of historical
data.
Hence, a
DWH NOT a complete
repository of data
How
back do you look historically? It really
depends a lot on the industry.
Typically it's an
economic
equation. How far back
depends on how much dose it
cost to store that extra
years
work of
data and what is it's
economic value? So for example in
financial organizations,
they
typically
store at least 3 years of
data going backward. Again
it's typical. It's not a hard and
fast
rule.
In a
telecommunications company, for
example, typically around 18 months of
data is stored.
Because
there are a lot more call
details records then there
are deposits and withdrawals
from a
bank
account so the storage
period is less, as one can
not afford to store as much of it
typica lly.
Another important
point is, the further
back in history you store the
data, the less value it
has
normally. Most
of the times, most of the
access into the data is
within that last 3 months to
6
months.
That's the most predictive
data.
In retail
business, retailers typically store at
least 65 weeks of data. Why do
they do that? Because
they
want to be able to look at
this season's selling history to
last season's selling history.
For
example, if it
is Eid buying season, I want
to look at the transit-buying this
Eid and compare it
with
the year ago. Which means I
need 65 weeks in order to
get year going back,
actually more
then a
year. It's a year and a
season. So 13 weeks are
additionally added to do the
analysis. So it
really
depends a lot on the
industry. But normally you expect at
least 13 months.
Economic
value of data
Vs.
Storage
cost
Data
Warehouse a
complete
repository of data?
16
This
raises an interesting question, do we
decide about storage of historical
data using only
time,
or consider
space also, or both?
Usually (but not
always) periodic or batch updates
rather than
real-time.
�
The
boundary is blurring for active
data warehousing.
�
For an
ATM, if update not in
real-time, then lot of real
trouble.
�
DWH is
for strategic decision making
based on historical data. Wont hurt if
transactions
of last
one hour/day are
absent.
�
Rate of
update depends on:
� Volume of
data,
� Nature of
business,
� Cost of
keeping historical data,
� Benefit of
keeping historical data.
It's
also true that in the
traditional data warehouse
the data acquisition is done on
periodic or
batch
based, rather then in real time. So think
again about ATM system, when
I put my ATM
card
and make a withdrawal, the
transactions are happening in real
time, because if they don't
the
bank
can get into trouble.
Someone can withdraw more
money then they had in
their account!
Obviously
that is not acceptable. So in an
online transaction processing
(OLTP) system, the
records
are updated, deleted and
inserted in real-time as the
business events take place,
as the data
entry takes
place, as the point of sales
system at a super market
captures the sales data
and inserts
into
the database.
In a traditional
data warehouse that is not
true. Because the
traditional data warehouse is
for
strategic
decision-making not for
running day to day business.
And for strategic decision
making,
I don't
need to know the last
hours worth of ATM deposits.
Because strategic decisions
take the
long
term perspective. For this
reason, and for efficiency
reasons normally what happens is
that in
the
data warehouse you update on
some predefined schedule
basis. May be it's once a
month,
maybe
it's once a weak, maybe
it's even once every night.
It depends on the volume of
data you
are
working with, and how
important the timings of the data
are and so on.
Deviation
from the PURIST
approach
Let me
first explain what/who a purist is. A
purist is an idealist or traditionalist
who wants
everything to be
done by the book or the old
arcane ways (only he/she
knows), in short he/she is
not pragmatic or
realist. Because the purist
wants everything perfect, so he/she
has good excuses
of doing
nothing, as it is not a perfect world. When
automobiles were first invented, it was
the
purists
who said that the
automobiles will fa il, as
they scare the horses. As
Iqbal very rightly
said
"Aina no sa
durna Tarzay Kuhan Pay
Arna..."
As data
warehouses become mainstream
and the corresponding
technology also
becomes
mainstream
technology, some traditional
attributes are being deviated in order to
meet the
increasing
demands of the user's. We have
already discussed and
reconciled with the fact
that a
data
warehouse is NOT the
complete repository of data. The
other most noticeable
deviations
being time variance
and nonvolatility.
17
Deviation
from Time Variance and
Nonvolatility
As the
size of data warehouse grows
over time (e.g., in terabytes),
reloading and appending
data
can
become a very tedious and
time consuming task. Furthermore, as
business users get the
"hang
of it"
they start demanding that
more up -to-date data be available in
the data warehouse.
Therefore,
instead of sticking to the traditional
data warehouse characteristic of keeping
the data
nonvolatile
and time variant, new data
is being added to the data
warehouse on a daily basis,
if
not on a real
-time basis and at the
same time historical data removed to
make room for the
"fresh"
data.
Thus, new approaches are
being made to tackle this
task. Two possible methods
are as
follows:
�
Perform
hourly/daily batch updates
from shadow tab les or
log files. Transformation rules
are
executed during the loading
process. Thus, when the data
reaches the target
data
warehouse
database, it is already transformed,
cleansed and
summarized.
Perform
real-time updates from
shadow tables or log files.
Again, transformation rules
are
executed
during the loading process.
Instead of batch updates,
this takes place on a
per
transaction
basis that meets certain
business selection criteria.
18
Table of Contents:
- Need of Data Warehousing
- Why a DWH, Warehousing
- The Basic Concept of Data Warehousing
- Classical SDLC and DWH SDLC, CLDS, Online Transaction Processing
- Types of Data Warehouses: Financial, Telecommunication, Insurance, Human Resource
- Normalization: Anomalies, 1NF, 2NF, INSERT, UPDATE, DELETE
- De-Normalization: Balance between Normalization and De-Normalization
- DeNormalization Techniques: Splitting Tables, Horizontal splitting, Vertical Splitting, Pre-Joining Tables, Adding Redundant Columns, Derived Attributes
- Issues of De-Normalization: Storage, Performance, Maintenance, Ease-of-use
- Online Analytical Processing OLAP: DWH and OLAP, OLTP
- OLAP Implementations: MOLAP, ROLAP, HOLAP, DOLAP
- ROLAP: Relational Database, ROLAP cube, Issues
- Dimensional Modeling DM: ER modeling, The Paradox, ER vs. DM,
- Process of Dimensional Modeling: Four Step: Choose Business Process, Grain, Facts, Dimensions
- Issues of Dimensional Modeling: Additive vs Non-Additive facts, Classification of Aggregation Functions
- Extract Transform Load ETL: ETL Cycle, Processing, Data Extraction, Data Transformation
- Issues of ETL: Diversity in source systems and platforms
- Issues of ETL: legacy data, Web scrapping, data quality, ETL vs ELT
- ETL Detail: Data Cleansing: data scrubbing, Dirty Data, Lexical Errors, Irregularities, Integrity Constraint Violation, Duplication
- Data Duplication Elimination and BSN Method: Record linkage, Merge, purge, Entity reconciliation, List washing and data cleansing
- Introduction to Data Quality Management: Intrinsic, Realistic, Orr’s Laws of Data Quality, TQM
- DQM: Quantifying Data Quality: Free-of-error, Completeness, Consistency, Ratios
- Total DQM: TDQM in a DWH, Data Quality Management Process
- Need for Speed: Parallelism: Scalability, Terminology, Parallelization OLTP Vs DSS
- Need for Speed: Hardware Techniques: Data Parallelism Concept
- Conventional Indexing Techniques: Concept, Goals, Dense Index, Sparse Index
- Special Indexing Techniques: Inverted, Bit map, Cluster, Join indexes
- Join Techniques: Nested loop, Sort Merge, Hash based join
- Data mining (DM): Knowledge Discovery in Databases KDD
- Data Mining: CLASSIFICATION, ESTIMATION, PREDICTION, CLUSTERING,
- Data Structures, types of Data Mining, Min-Max Distance, One-way, K-Means Clustering
- DWH Lifecycle: Data-Driven, Goal-Driven, User-Driven Methodologies
- DWH Implementation: Goal Driven Approach
- DWH Implementation: Goal Driven Approach
- DWH Life Cycle: Pitfalls, Mistakes, Tips
- Course Project
- Contents of Project Reports
- Case Study: Agri-Data Warehouse
- Web Warehousing: Drawbacks of traditional web sear ches, web search, Web traffic record: Log files
- Web Warehousing: Issues, Time-contiguous Log Entries, Transient Cookies, SSL, session ID Ping-pong, Persistent Cookies
- Data Transfer Service (DTS)
- Lab Data Set: Multi -Campus University
- Extracting Data Using Wizard
- Data Profiling