 |
Physical Database Design: DESIGNING FIELDS, CODING AND COMPRESSION TECHNIQUES |
| << Normalization Summary, Example, Physical Database Design |
| Physical Record and De-normalization, Partitioning >> |

Database
Management System
(CS403)
VU
Lecture No.
22
Overview of
Lecture
Data
Volume and Usage
Analysis
o
Designing
Fields
o
Choosing
Data Type
o
Coding
Techniques
o
Coding
Example
o
Controlling
Data Integrity
o
The
Physical Database Design
Considerations and
Implementation
The
physical design of the
database is one of the most
important phases in
the
computerization
of any organization. There are a
number of important steps
involved
in the
physical design of the
database. Steps are carried
out in sequence and need
to
be
performed precisely so that
the result of the first
step is properly used as
input to
the
next step.
Before
moving onto the Physical
database design the design
of the database
should
have
undergone the following
steps,
Normalization
of relations
Volume
estimate
Definition
of each attribute
Description
of where and when data is
used (with
frequencies)
Expectation
or requirements of response time
and data security.
Description
of the technologies.
For
the physical database design
we need to check the usage of
the data in term of
its
size
and the frequency. This
critical decision is to be made to ensure
that proper
structures
are used and the
database is optimized for
maximum performance
and
efficiency.
The
following steps are
necessary once we have the
prerequisite complete:
Select
the appropriate attribute
and a corresponding data
type for the
attribute.
The
process of selecting the
attribute to be placed in a specific
relation in the
physical
design.
Need considerable care as it is
one of the most important
and basic aspects for
the
creation of the
database.
Grouping
of attributes in the logical
order so that the relation
is created in such a way
that no
information is missing from
the relation and also no
redundant or unnecessary
information
is placed in the
relation.
Looking
at the logical design at the
time of transformation into
physical design there
may be
stages when the information
combined logically in the
logical design looks
odd
when transforming the design
into a physical one.
Arrangement
of Similar records into the
secondary memory (hard
disk)
183

Database
Management System
(CS403)
VU
The
scheme of storage on hard disk is
important as it leads to the efficiency
and
management of
the data on disk. Different
types of data access mechanism
are
available
and are useful for
rapid access, storage, and
modification of data.
Different
types of database structures can be
used for placement of data
on disks,
management of
data in the forms of indexes
and different database
architecture is vital
and leads
to better retrieval and
recovery of records.
Preparing
queries and handling strategies
for the proper usage of
the database, so that
any
type of input or output
operation performed on the
database is executed in an
optimized
and efficient way.
DESIGNING
FIELDS
Field is
the smallest unit of application data
recognized by system software,
such as a
programming
language or any database management
system.
Designing
fields in the databases' physical
design as discussed earlier is a
major issue
and
needs to be dealt with great
care and accuracy. Data
types are the
structure
defined
for placing data in the
attributes. Each data type is
appropriate for use
with
certain
type of data.
4 major
objectives for using data
types when specifying
attributes in a database
are
given as
under:
Minimized
usage of storage space
Represent
all possible values
Improve
data integrity
Support
all data manipulation
The
correct data type selection
and decision for proper
domain of the attribute is
very
necessary
as it provides a number of
benefits.
Most
common data types used in
the available DBMS of the
day have the
following
set of
common attributes.
Max
Size:
Data
type
Description
PL/SQL
Variable
length character string having
maximum
32767
bytes
VARCHAR2(size)
length
bytes.
size
minimum
is 1
You
must specify size
Now
deprecated - VARCHAR is a synonym
for
VARCHAR
VARCHAR2
but this usage may change in
future
versions.
32767
bytes
Fixed length
character data of length size
bytes.
Default
and
CHAR(size)
This
should be used for fixed length
data. Such as
minimum
size is 1
codes
A100, B102...
byte.
Magnitude
1E-130
..
10E125
maximum precision of
126 binary digits, which is
roughly equivalent to
38
decimal
digits
NUMBER(p,s)
The
scale
s
can
range
from
-84
to
127.
For
floating
point
don't
specify
p,s
REAL
has a maximum precision of 63 binary digits,
which is roughly
equivalent
to 18 decimal digits
184
Database
Management System
(CS403)
VU
32760
bytes
Note
this is smaller
Character
data of variable length (A
bigger
LONG
than
the maximum
version
the VARCHAR2 data
type)
width
of a LONG
column
from
January 1, 4712
BC to
December 31,
DATE
Valid
date range
AD.
9999
(in
Oracle7 = 4712
AD)
Raw
binary data of length
size bytes.
RAW(size)
32767
bytes
You
must specify size for a RAW
value.
32760
bytes
Note
this is smaller
Raw
binary data of variable length.
(not
LONG
RAW
than
the maximum
interpreted by
PL/SQL)
width
of a LONG
RAW
column
BLOB
Binary
Large Object
4Gigabytes
CODING
AND COMPRESSION TECHNIQUES:
There a
re some attributes which
have some sparse set of
values, these values
when
they
are represented in any data
type are hard to express,
for this purpose some
codes
are
used. As the codes defined
by the database administrator or
the programmer
consume
less space so they are
better for use in situations
where we have large
number of
records and wastage of small amount of
space in each record can
lead to
loss of
huge amount of data storage
space. Thus causing lowered
database efficiency.
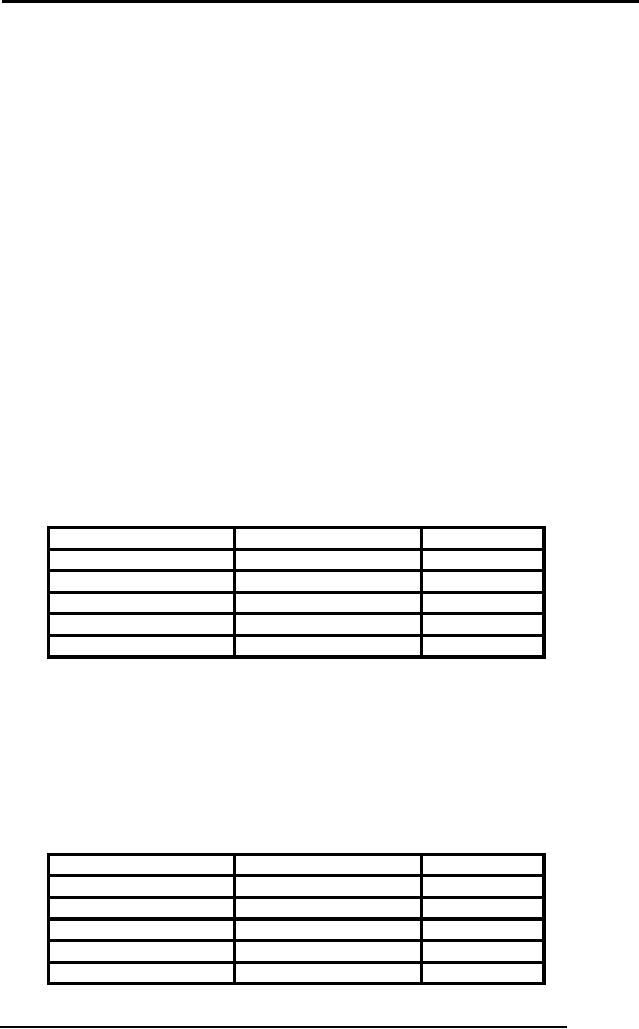
STID
STNAME
HOBBY
S1020
Sohail
Dar
Reading
S1038
Shoaib
Ali
Gardening
S1015
Tahira
Ejaz
Reading
S1015
Tahira
Ejaz
Movie
S1018
Arif
Zia
Reading
Coding
techniques are also useful
for compression of data values appearing
the data,
by
replacing those data values with
the smaller sized codes we
can further reduce
the
space
needed by the data for storage in
the database.
Following
tables give the use of
codes and their utilization
in the database
environment
Coding
Example:
Student
STID
STNAME
HOBBY
S1020
Sohail
Dar
R
S1038
Shoaib
Ali
G
S1015
Tahira
Ejaz
R
S1015
Tahira
Ejaz
M
S1018
Arif
Zia
R
185

Database
Management System
(CS403)
VU
Hobby
Table
CODE
HOBBY
R
Reading
G
Gardening
M
Movies
In the
above example we have seen
the implementation of the
codes as replacement to
the data
in the actual table, here we
actually allocated codes to
different hobbies and
then
replace the codes instead of
writing the codes in the
table.
We get a
number of benefits by the
use of data types and
the benefit can be in
a
number of
dimensions.
Default
value
Default
values are the values which
are associated with a
specific attribute
and
can
help us to reduce the chances of
inserting incorrect values in
the attribute
space.
And also it can help us
preventing the attribute
value be left empty.
Range
Control
Range
control implemented over the
data can be very easily
achieved by using
any
data type. As the data
type enforces the entry of data in
the field according
to the
limitations of the data
type.
Null
Value Control
As we
already know that a null
value is an empty value and
is distinct from
zero and
spaces, Databases can
implement the null value
control by using the
different
data types or their build in
mechanisms.
Referential
Integrity
Referential
Integrity means to keep the
input values for a specific
attribute in
specific
limits in comparison to any
other attribute of the same
or any other
relation.
186
Table of Contents:
- Introduction to Databases and Traditional File Processing Systems
- Advantages, Cost, Importance, Levels, Users of Database Systems
- Database Architecture: Level, Schema, Model, Conceptual or Logical View:
- Internal or Physical View of Schema, Data Independence, Funct ions of DBMS
- Database Development Process, Tools, Data Flow Diagrams, Types of DFD
- Data Flow Diagram, Data Dictionary, Database Design, Data Model
- Entity-Relationship Data Model, Classification of entity types, Attributes
- Attributes, The Keys
- Relationships:Types of Relationships in databases
- Dependencies, Enhancements in E-R Data Model. Super-type and Subtypes
- Inheritance Is, Super types and Subtypes, Constraints, Completeness Constraint, Disjointness Constraint, Subtype Discriminator
- Steps in the Study of system
- Conceptual, Logical Database Design, Relationships and Cardinalities in between Entities
- Relational Data Model, Mathematical Relations, Database Relations
- Database and Math Relations, Degree of a Relation
- Mapping Relationships, Binary, Unary Relationship, Data Manipulation Languages, Relational Algebra
- The Project Operator
- Types of Joins: Theta Join, EquiJoin, Natural Join, Outer Join, Semi Join
- Functional Dependency, Inference Rules, Normal Forms
- Second, Third Normal Form, Boyce - Codd Normal Form, Higher Normal Forms
- Normalization Summary, Example, Physical Database Design
- Physical Database Design: DESIGNING FIELDS, CODING AND COMPRESSION TECHNIQUES
- Physical Record and De-normalization, Partitioning
- Vertical Partitioning, Replication, MS SQL Server
- Rules of SQL Format, Data Types in SQL Server
- Categories of SQL Commands,
- Alter Table Statement
- Select Statement, Attribute Allias
- Data Manipulation Language
- ORDER BY Clause, Functions in SQL, GROUP BY Clause, HAVING Clause, Cartesian Product
- Inner Join, Outer Join, Semi Join, Self Join, Subquery,
- Application Programs, User Interface, Forms, Tips for User Friendly Interface
- Designing Input Form, Arranging Form, Adding Command Buttons
- Data Storage Concepts, Physical Storage Media, Memory Hierarchy
- File Organizations: Hashing Algorithm, Collision Handling
- Hashing, Hash Functions, Hashed Access Characteristics, Mapping functions, Open addressing
- Index Classification
- Ordered, Dense, Sparse, Multi-Level Indices, Clustered, Non-clustered Indexes
- Views, Data Independence, Security, Vertical and Horizontal Subset of a Table
- Materialized View, Simple Views, Complex View, Dynamic Views
- Updating Multiple Tables, Transaction Management
- Transactions and Schedules, Concurrent Execution, Serializability, Lock-Based Concurrency Control, Deadlocks
- Incremental Log with Deferred, Immediate Updates, Concurrency Control
- Serial Execution, Serializability, Locking, Inconsistent Analysis
- Locking Idea, DeadLock Handling, Deadlock Resolution, Timestamping rules