 |
Ordered, Dense, Sparse, Multi-Level Indices, Clustered, Non-clustered Indexes |
| << Index Classification |
| Views, Data Independence, Security, Vertical and Horizontal Subset of a Table >> |

Database
Management System
(CS403)
VU
Lecture No.
38
Reading
Material
"Database
Systems Principles, Design
and Implementation" written by
Catherine Ricardo,
Maxwell
Macmillan.
"Database
Management System" by Jeffery A
Hoffer
Overview of
Lecture
Indexes
Clustered
Versus Un-clustered
Indexes
Dense
Verses Sparse Indexes
Primary
and Secondary Indexes
Indexes
Using Composite Search
Keys
In the
previous lecture we studied
about what the indexes
are and what is the need
for
creating
an index. There exist a
number of index types which are
important and are
helpful
for the file organization in
database environments for
the storage of files on
disks.
Ordered
Indices
In order
to allow fast random
access,
an index structure may be
used.
A file
may have several indices on
different search
keys.
If the
file containing the records is
sequentially ordered, the
index whose search
key
specifies
the sequential order of the
file is the primary
index, or clustering
index.
Note:
The search key of a primary
index is usually the primary
key, but it is not
necessarily
so.
Indices
whose search key specifies an
order different from the
sequential order of
the
file
are called the secondary
indices, or nonclustering
indices.
Clustered
Indexes
A clustered
index determines
the storage order of data in a table. A
clustered index is
analogous
to a telephone directory, which arranges
data by last name. Because
the
clustered
index dictates the physical
storage order of the data in the
table, a table can
contain
only one clustered index.
However, the index can
comprise multiple
columns
(a
composite index), like the
way a telephone directory is
organized by last name
and
first
name.
A
clustered index is particularly
efficient on columns often
searched for ranges
of
values.
Once the row with the
first value is found using
the clustered index, rows
with
subsequent
indexed values are
guaranteed to be physically adjacent.
For example, if
an
application frequently executes a query
to retrieve records between a range of
dates,
a
clustered index can quickly
locate the row containing
the beginning date, and
then
retrieve
all adjacent rows in the
table until the last date is
reached. This can
help
increase
the performance of this type
of query. Also, if there is a
column(s) which is
used
frequently to sort the data
retrieved from a table, it
can be advantageous to
275

Database
Management System
(CS403)
VU
cluster
(physically sort) the table
on that column(s) to save
the cost of a sort each
time
the
column(s) is queried.
Clustered
indexes are also efficient
for finding a specific row
when the indexed
value
is
unique. For example, the
fastest way to find a
particular employee using
the unique
employee
ID column emp_id
would be
to create a clustered index or
PRIMARY
KEY
constraint on the emp_id
column.
Note
PRIMARY
KEY constraints create clustered
indexes automatically if no
clustered
index already exists on the
table and a nonclustered
index is not
specified
when
you create the PRIMARY KEY
constraint.
Alternatively,
a clustered index could be created on
lname,
fname (last
name, first
name),
because employee records are often
grouped and queried that
way rather than
by
employee ID.
Non-clustered
Indexes
Nonclustered
indexes have the same
B-tree structure as clustered
indexes, with two
significant
differences:
The data
rows are not sorted
and stored in order based on
their nonclustered
keys.
The
leaf layer of a nonclustered
index does not consist of
the data pages.
Instead,
the leaf nodes contain
index rows. Each index row
contains the
nonclustered
key
value and one or more
row locators that point to
the data row (or rows if
the index
is not
unique) having the key
value.
Nonclustered
indexes can be defined on
either a table with a
clustered index or a heap.
In
Microsoft® SQL ServerTM
version 7.0, the row
locators in nonclustered index
rows
have
two forms:
If the
table is a heap (does not have a
clustered index), the row
locator is a pointer to
the
row. The pointer is built
from the file ID, page
number, and number of the
row on
the page.
The entire pointer is known
as a Row ID.
If the
table does have a clustered
index, the row locator is
the clustered index key
for
the
row. If the clustered index
is not a unique index, SQL
Server 7.0 adds an
internal
value to
duplicate keys to make them
unique. This value is not
visible to users; it is
used to
make the key unique
for use in nonclustered
indexes. SQL Server
retrieves the
data row
by searching the clustered
index using the clustered
index key stored in
the
leaf
row of the nonclustered
index.
Because
nonclustered indexes store clustered
index keys as their row
locators, it is
important
to keep clustered index keys
as small as possible. Do not
choose large
columns
as the keys to clustered
indexes if a table also has
nonclustered indexes.
Dense and
Sparse Indices
There
are Two types of ordered
indices:
Dense
Index:
An index
record appears for every
search key value in
file.
This
record contains search key
value and a pointer to the
actual record.
Sparse
Index:
Index
records are created only for
some of the records.
To locate
a record, we find the index
record with the largest
search key value less
than
or equal
to the search key value we
are looking for.
We start at
that record pointed to by
the index record, and
proceed along the
pointers
in the
file (that is, sequentially)
until we find the desired
record.
Dense
indices are faster in general,
but sparse indices require
less space and
impose
less
maintenance for insertions
and deletions.
We can
have a good compromise by
having a sparse index with
one entry per block.
It
has
several advantages.
276
Database
Management System
(CS403)
VU
Biggest
cost is in bringing a block
into main memory.
We are
guaranteed to have the
correct block with this
method, unless record is on
an
overflow
block (actually could be
several blocks).
Index
size still small.
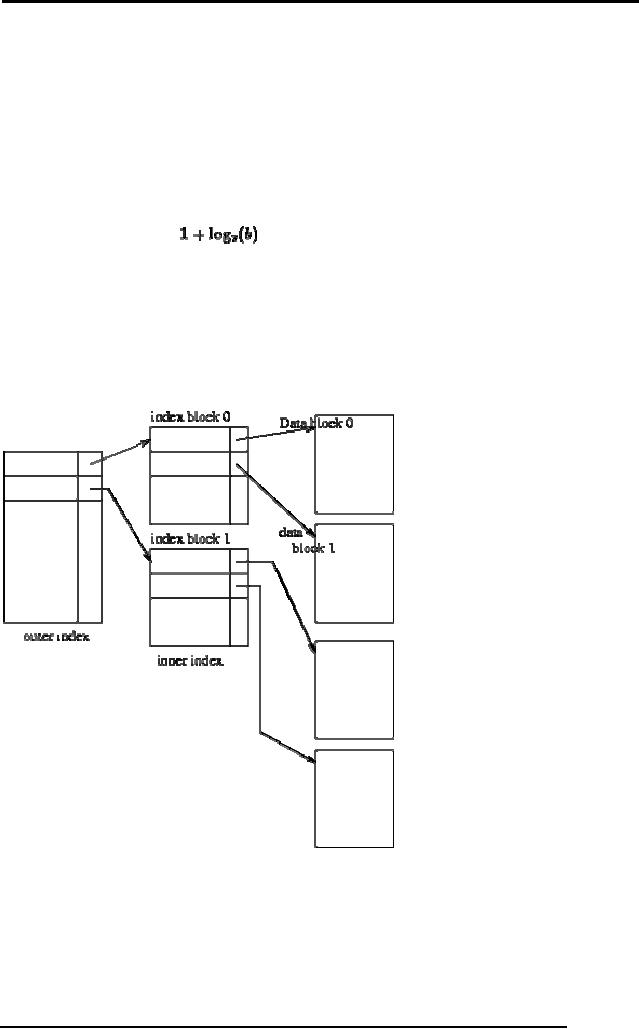
Multi-Level
Indices
Even
with a sparse index, index
size may still grow
too large. For 100,000
records, 10
per
block, at one index record
per block, that's 10,000
index records! Even if we
can
fit
100 index records per block,
this is 100 blocks.
If index
is too large to be kept in
main memory, a search results in
several disk reads.
If there
are no overflow blocks in
the index, we can use
binary search.
This will
read as many as
blocks
(as many as 7 for our
100 blocks).
If index
has overflow blocks, then
sequential search typically
used, reading all
b
index
blocks.
Use
binary search on outer
index. Scan index block
found until correct index
record
found.
Use index record as before -
scan block pointed to for
desired record.
For
very large files, additional
levels of indexing may be
required.
Indices
must be updated at all levels
when insertions or deletions
require it.
Frequently,
each level of index corresponds to a
unit of physical storage (e.g.
indices
at the
level of track, cylinder and
disk).
Two-level
sparse index.
Index
Update
Regardless of
what form of index is used,
every index must be updated
whenever a
record is
either inserted into or
deleted from the
file.
Deletion:
Find
(look up) the
record
If the
last record with a
particular search key value,
delete that search key
value from
index.
277
Database
Management System
(CS403)
VU
For
dense indices, this is like
deleting a record in a
file.
For
sparse indices, delete a key
value by replacing key
value's entry in index by
next
search
key value. If that value
already has an index entry,
delete the entry.
Insertion:
Find
place to insert.
Dense
index: insert search key
value if not present.
Sparse
index: no change unless new
block is created. (In this
case, the first search
key
value
appearing in the new block
is inserted into the
index).
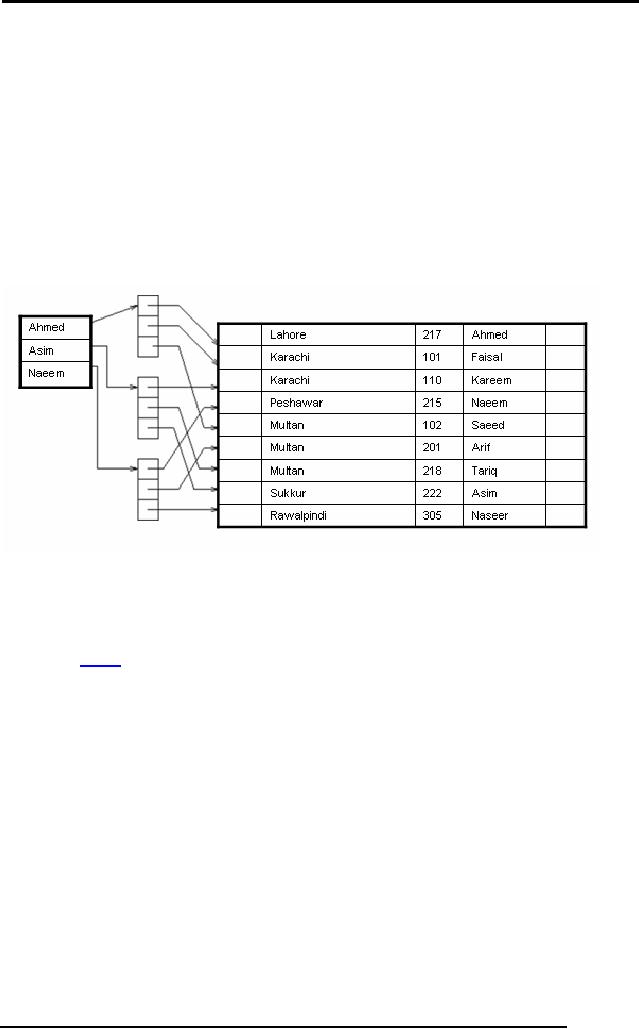
Secondary
Indices
If the
search key of a secondary
index is not a candidate
key, it is not enough to
point
to just
the first record with
each search-key value
because the remaining records
with
the
same search-key value could
be anywhere in the file.
Therefore, a secondary
index
must
contain pointers to all the
records.
Sparse
secondary index on sname.
We can
use an extra-level of indirection to
implement secondary indices on
search
keys
that are not candidate
keys. A pointer does not
point directly to the file
but to a
bucket
that contains pointers to
the file.
See
Figure above
on
secondary key sname.
To
perform a lookup on Peterson, we must read
all three records pointed to by
entries
in bucket
2.
Only
one entry points to a Peterson
record, but three records need to be
read.
As file
is not ordered physically by cname, this
may take 3 block
accesses.
Secondary
indices must be dense, with an
index entry for every
search-key value, and
a pointer
to every record in the
file.
Secondary
indices improve the
performance of queries on non-primary
keys.
They also
impose serious overhead on database
modification: whenever a file
is
updated,
every index must be
updated.
Designer
must decide whether to use
secondary indices or
not.
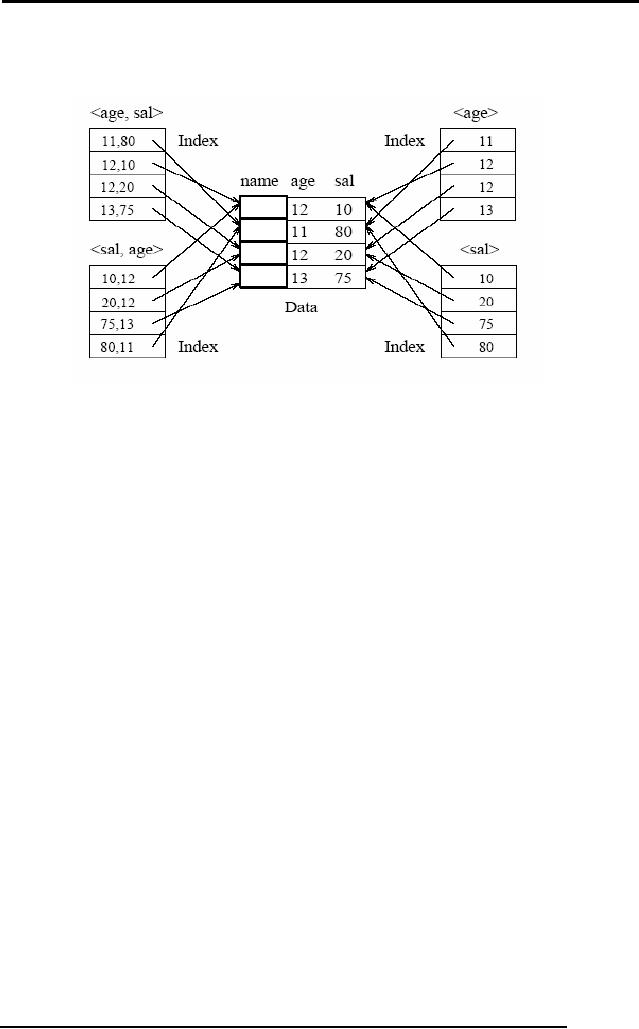
Indexes
Using Composite Search
Keys
The
search key for an index
can contain several fields;
such keys are called
composite
search
keys or concatenated
keys. As an
example, consider a collection of
employee
records,
with fields name,
age, and
sal, stored in sorted
order by name. Figure
below
illustrates
the difference between a
composite index with key
(age,
sal) and a
278
Database
Management System
(CS403)
VU
composite
index with key (sal,
age), an
index with key age, and an
index with key sal.
All
indexes which are shown in
the figure use Alternative
(2) for data
entries.
Amir
Qazi
Saif
Nasar
If the
search key is composite, an
equality query is one in
which each field in
the
search
key is bound to a constant. For
example, we can ask to
retrieve all data
entries
with
age = 20 and sal = 10. The
hashed file organization supports
only equality
queries,
since a hash function identifies
the bucket containing
desired records only if a
value is
specified for each field in
the search key. A range
query is one in which
not
all
fields in the search key
are bound to constants. For
example, we can ask to
retrieve
all data
entries with age = 20;
this query implies that
any value is acceptable for
the
sal
field. As another example of a
range query, we can ask to
retrieve all data
entries
with
age < 30 and sal >
40.
279
Table of Contents:
- Introduction to Databases and Traditional File Processing Systems
- Advantages, Cost, Importance, Levels, Users of Database Systems
- Database Architecture: Level, Schema, Model, Conceptual or Logical View:
- Internal or Physical View of Schema, Data Independence, Funct ions of DBMS
- Database Development Process, Tools, Data Flow Diagrams, Types of DFD
- Data Flow Diagram, Data Dictionary, Database Design, Data Model
- Entity-Relationship Data Model, Classification of entity types, Attributes
- Attributes, The Keys
- Relationships:Types of Relationships in databases
- Dependencies, Enhancements in E-R Data Model. Super-type and Subtypes
- Inheritance Is, Super types and Subtypes, Constraints, Completeness Constraint, Disjointness Constraint, Subtype Discriminator
- Steps in the Study of system
- Conceptual, Logical Database Design, Relationships and Cardinalities in between Entities
- Relational Data Model, Mathematical Relations, Database Relations
- Database and Math Relations, Degree of a Relation
- Mapping Relationships, Binary, Unary Relationship, Data Manipulation Languages, Relational Algebra
- The Project Operator
- Types of Joins: Theta Join, EquiJoin, Natural Join, Outer Join, Semi Join
- Functional Dependency, Inference Rules, Normal Forms
- Second, Third Normal Form, Boyce - Codd Normal Form, Higher Normal Forms
- Normalization Summary, Example, Physical Database Design
- Physical Database Design: DESIGNING FIELDS, CODING AND COMPRESSION TECHNIQUES
- Physical Record and De-normalization, Partitioning
- Vertical Partitioning, Replication, MS SQL Server
- Rules of SQL Format, Data Types in SQL Server
- Categories of SQL Commands,
- Alter Table Statement
- Select Statement, Attribute Allias
- Data Manipulation Language
- ORDER BY Clause, Functions in SQL, GROUP BY Clause, HAVING Clause, Cartesian Product
- Inner Join, Outer Join, Semi Join, Self Join, Subquery,
- Application Programs, User Interface, Forms, Tips for User Friendly Interface
- Designing Input Form, Arranging Form, Adding Command Buttons
- Data Storage Concepts, Physical Storage Media, Memory Hierarchy
- File Organizations: Hashing Algorithm, Collision Handling
- Hashing, Hash Functions, Hashed Access Characteristics, Mapping functions, Open addressing
- Index Classification
- Ordered, Dense, Sparse, Multi-Level Indices, Clustered, Non-clustered Indexes
- Views, Data Independence, Security, Vertical and Horizontal Subset of a Table
- Materialized View, Simple Views, Complex View, Dynamic Views
- Updating Multiple Tables, Transaction Management
- Transactions and Schedules, Concurrent Execution, Serializability, Lock-Based Concurrency Control, Deadlocks
- Incremental Log with Deferred, Immediate Updates, Concurrency Control
- Serial Execution, Serializability, Locking, Inconsistent Analysis
- Locking Idea, DeadLock Handling, Deadlock Resolution, Timestamping rules