 |

Database
Management System
(CS403)
VU
Lecture No.
21
Reading
Material
"Database
Systems Principles, Design
and Implementation"
Page
238
written
by Catherine Ricardo, Maxwell
Macmillan.
"Modern
Database Management", Fred
McFadden, Jeffrey
Chapter
6
Hoffer,
Benjamin/Cummings
Overview of Lecture:
o Summary
of normalization
o A
normalization example
o Introduction
to physical DB design
phase
Normalization
Summary
Normalization
is a step by step process to
make DB design more
efficient and
accurate. A
normalized database helps
the DBA to maintain the
consistency of the
database.
However, the normalization
process is not a must, rather it is a
strongly
recommended
activity performed after the
logical DB design phase. Not
a must means,
that
the consistency of the
database can be maintained
even with an
un-normalized
database
design, however, it will make it
difficult for the designer.
Un-normalized
relations
are more prone to errors or
inconsistencies.
The
normalization is based on the
FDs. The FDs are not created
by the designer,
rather
they exist in the system
being developed and the
designer identifies
them.
Normalization
forms exist up to 6NF
starting from 1NF, however,
for most of the
situations
3NF is sufficient.
Normalization
is performed through Analysis
or
Synthesis
process. The input to the
process is the logical
database design and the
FDs
that
exist in the system. Each
individual table is checked for
the normalization
considering
the relevant FDs; if any
normalization requirement for a
particular normal
form is
being violated, then it is sorted
out generally by splitting
the table. The
176

Database
Management System
(CS403)
VU
process
is applied on all the tables of
the design hence the
database is called to be in a
particular
normal form.
Normalization
Example
In the
following an example of normalization
process has been discussed.
This
example
is taken from Ricardo book,
page 238. The example
comprehensively
explains
the stages of the
normalization process. The
approach adopted for
the
normalization
is analysis approach, whereby a
singe large table is assumed
involving
all
the attributes required in
the system. Later, the
table is decomposed into
smaller
tables by
considering the FDs existing in
the system. As has been discussed
before,
the FDs
have to be identified by the
designer they are not
described as regular from
b
y the
users. So the example also
explains the transforming of
real-world scenarios
into
FDs.
An
example table is given
containing all the
attributes that are used in
different
applications
in the system under study.
The table named WORK
consists of the
attributes:
WORK
(projName, projMgr, empId,
hours, empName, budget,
startDate, salary,
empMgr,
empDept, rating)
The
purpose of most of the attributes is
clear from the name,
however, they are
explained
in the following facts about
the system. The facts
mentioned in the book
are
italicized
and numbered followed by the
explanation.
1- Each
project has a unique name,
but names of employees and
managers are not
unique.
This
fact simply illustrates that
values in the projName
attribute will be unique so
this
attribute
can be used as identifier if
required however the
attributes empName,
empMgr
and projMgr are not
unique so they cannot be
used as identifiers
2- Each
project has one manager,
whose name is stored in
projMgr
177

Database
Management System
(CS403)
VU
The
projMgr is not unique as
mentioned in 1, however, since there is
only one
manager
for a project and project
name is unique, so we can say
that if we know the
project
name we can determine a
single project manager, hence
the FD
projName
projMgr
3- Many
employees may be assigned to work on each
project, and an employee
may
be assigned to
more than one project.
The attribute `hours' tells
the number of
hours
per week that a particular
employee is assigned to work on a
particular
project.
Since
there are many employees
working on each project so
the projName
attribute
cannot
determine the employee
working on a project, same is
the case with empId
that
it cannot
determine the particular
project an employee is working since
one employee
is
working on many projects.
However, if we combine both
the empId and
projName
then we
can determine the number of
hours that an employee
worked on a particular
project
within a week, so the
FD
empId,
projName
hours
4- Budget
stores the budget allocated
for a project and startDate
stores the starting
date of a
project
Since
the project name is unique,
so if we know the project
name we can determine
the
budget allocated for it and
also the starting date of
the project
projName
budget,
startDate
5- Salary
gives the annual salary of
the employee
empId
salary,
empName
Although
empId has not been mentioned
as unique, however, it is generally
assumed
that
attribute describing Id of something are
unique, so we can define the
above FD.
6- empMgr
gives the name of the
employee's manager, who is
not the same as
project
manager.
178

Database
Management System
(CS403)
VU
Project
name is determined by project name,
however one employee may
work on
many
projects, so we can not
determine the project manager of an
employee thourgh
the Id of
employee. However, empMgr is
the manager of employee and
can be known
from
employee Id, so FD in 5 can be
extended
empId
salary,
empName, empMgr
7-
empDept give the employee's
department. Department names
are unique. The
employee's
manager is the manager of
the employee's
department.
empDept
empMgr
Because
empDept is unique and there
is one manager for each
department. At the
same
time, because each employee
works in one department, we
can also say that
empId
empDept
so the FD
in 6 is further extended
empId
salary,
empName, empMgr,
empDept
8- Rating
give the employee's rating
for a particular project.
The project manager
assigns
the rating at the end of
employee's work on that
project
Like
`hours' attribute, the
attribute `rating' is also
determined by two attributes,
the
projName
and empId, because many
employees work on one
project and one
employee
may work on many projects.
So to know the rating of an
employee on a
particular
project we need to know the
both, so the FD
projName,
empId
rating
In all we
have the following four
FDs:
1)
empId
salary,
empName, empMgr,
empDept
2)
projName, empId
rating,
hours
3)
projName
projMgr,
budget, startDate
4)
empDept
empMgr
Normalization
So we
identified the FDs in our
example scenario, now to perform
the normalization
process.
For this we have to apply
the conditions of the normal
forms on our tables.
Since we
have got just one
table to begin with so we start
our process on this
table:
179
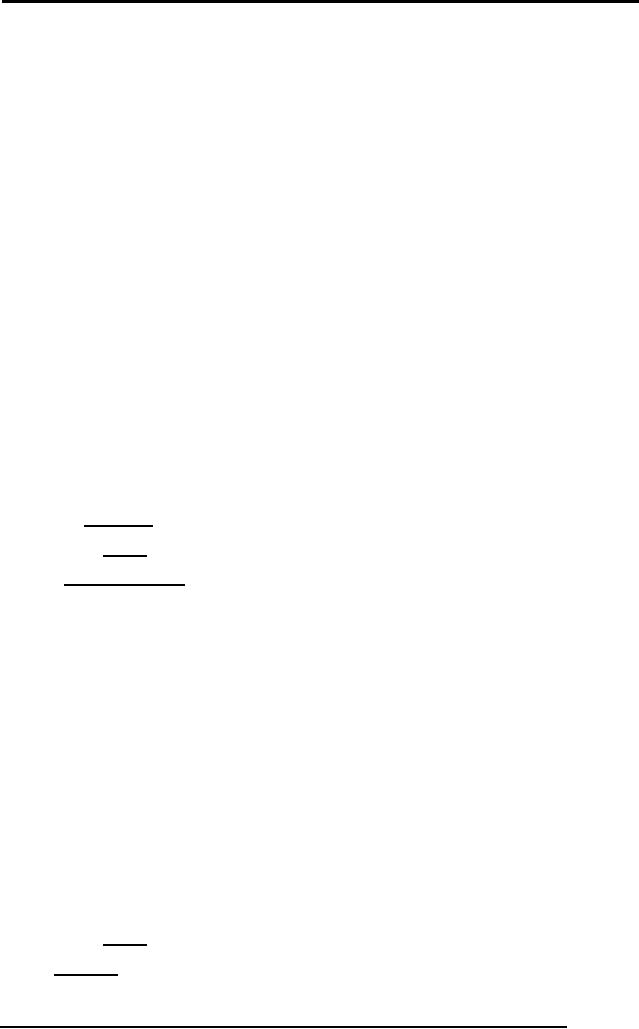
Database
Management System
(CS403)
VU
WORK(projName,
projMgr, empId, hours,
empName, budget, startDate,
salary,
empMgr,
empDept, rating)
First
Normal Form:
Seeing
the data in the example in
the book or assuming otherwise
that all attributes
contain
the atomic value, we find
out the table is in the
1NF.
Second
Normal Form:
Seeing
the FDs, we find out
that the PK for the
table is a composite one
comprising of
empId,
projName. We did not include
the determinant of fourth
FD, that is,
the
empDept,
in the PK because empDept is
dependent on empId and empID
is included
in our
proposed PK. However, with
this PK (empID, projName) we
have got partial
dependencies in
the table through FDs 1 and
3 where we see that some
attributes are
being
determined by subset of our PK
which is the violation of
the requirement for
the
2NF. So
we split our table based on
the FDs 1 and 3 as
follows:
PROJECT
(projName, projMgr,
startDate)
EMPLOYEE
(empId, empName, salary,
empMgr, empDept)
WORK
(projName, empId, hours,
rating)
All the
above three tables are in
2NF since they are in 1NF
and there is no
partial
dependency
in them.
Third
Normal Form
Seeing
the four FDs, we find
out that the tables
are in 2NF and there is no
transitive
dependency
in PROJECT and WORK tables,
so these two tables are in
3NF. However,
there is
a transitive dependency in EMNPLOYEE
table since FD 1 say
empId
empDept
and FD 4 say empDept
empMgr.
To remove this transitive
dependency
we
further split the EMPLOYEE
table into following
two:
EMPLOYEE
(empId, empName, salary,
empDept)
DEPT
(empDept, empMgr)
Hence
finally we got four
tables
180

Database
Management System
(CS403)
VU
PROJECT
(projName, projMgr,
startDate)
EMPLOYEE
(empId, empName, salary,
empDept)
WORK
(projName, empId, hours,
rating)
DEPT
(empDept, empMgr)
These
four tables are in 3NF based
on the given FD, hence
the database has been
normalized
up to 3NF.
Physical
Database Design
After
completing the logical
database design and then
normalizing it, we have
to
establish
the physical database
design. Throughout the
processes of conceptual
and
logical
database designs and the
normalization, the primary
objective has been
the
storage
efficiency and the
consistency of the database. So we
have been following
good
design principles. In the
physical database design,
however, the focus
shifts
from
storage efficiency to the efficiency in
execution. So we deliberately violate
some
of the
rules that we studied
earlier, however, this shift
in focus should never ever
lead
to
incorrect state of the
database. The correctness of
the database we have to
maintain
in any
case. When we do not follow
the good design principles
then it makes it
difficult
to maintain the consistency or
correctness of the database.
Since the violation
is
deliberate, that is, we are
aware of the dangers due to violations
and we know the
reasons
for these violations so we
have to take care of the
possible threats and
adopt
appropriate
measures. Finally, there are
different possibilities and we as
designers
have to
adopt particular ones based
on certain reasons or objectives. We
have to be
clear
about our objectives.
The
physical DB design
involves:
·
Transforms
logical DB design into
technical specifications for
storing and
retrieving
data
·
Does
not include practically
implementing the design
however tool specific
decisions
are involved
It
requires the following
input:
·
Normalized
relations (the process
performed just
before)
181

Database
Management System
(CS403)
VU
·
Definitions
of each attribute (means the
purpose or objective of the
attributes.
Normally
stored in some form of data dictionary or
a case tool or may be
on
paper)
·
Descriptions
of data usage (how and by
whom data will be
used)
·
Requirements
for response time, data
security, backup etc.
·
Tool to
be used
Decisions
that are made during this
process are:
·
Choosing
data types (precise data types
depend on the tool to be
used)
·
Grouping
attributes (although
normalized)
·
Deciding
file organizations
·
Selecting
structures
·
Preparing
strategies for efficient
access
That is
all about today's lecture,
the discussion continues in
the next lecture.
Summary
In
today's lecture we summarized
the normalization process
and also saw an
example
to
practically implement the
process. We have introduced
our next topic that is
the
physical
DB design. We will discuss this
topic in the lectures to be
followed.
182
Table of Contents:
- Introduction to Databases and Traditional File Processing Systems
- Advantages, Cost, Importance, Levels, Users of Database Systems
- Database Architecture: Level, Schema, Model, Conceptual or Logical View:
- Internal or Physical View of Schema, Data Independence, Funct ions of DBMS
- Database Development Process, Tools, Data Flow Diagrams, Types of DFD
- Data Flow Diagram, Data Dictionary, Database Design, Data Model
- Entity-Relationship Data Model, Classification of entity types, Attributes
- Attributes, The Keys
- Relationships:Types of Relationships in databases
- Dependencies, Enhancements in E-R Data Model. Super-type and Subtypes
- Inheritance Is, Super types and Subtypes, Constraints, Completeness Constraint, Disjointness Constraint, Subtype Discriminator
- Steps in the Study of system
- Conceptual, Logical Database Design, Relationships and Cardinalities in between Entities
- Relational Data Model, Mathematical Relations, Database Relations
- Database and Math Relations, Degree of a Relation
- Mapping Relationships, Binary, Unary Relationship, Data Manipulation Languages, Relational Algebra
- The Project Operator
- Types of Joins: Theta Join, EquiJoin, Natural Join, Outer Join, Semi Join
- Functional Dependency, Inference Rules, Normal Forms
- Second, Third Normal Form, Boyce - Codd Normal Form, Higher Normal Forms
- Normalization Summary, Example, Physical Database Design
- Physical Database Design: DESIGNING FIELDS, CODING AND COMPRESSION TECHNIQUES
- Physical Record and De-normalization, Partitioning
- Vertical Partitioning, Replication, MS SQL Server
- Rules of SQL Format, Data Types in SQL Server
- Categories of SQL Commands,
- Alter Table Statement
- Select Statement, Attribute Allias
- Data Manipulation Language
- ORDER BY Clause, Functions in SQL, GROUP BY Clause, HAVING Clause, Cartesian Product
- Inner Join, Outer Join, Semi Join, Self Join, Subquery,
- Application Programs, User Interface, Forms, Tips for User Friendly Interface
- Designing Input Form, Arranging Form, Adding Command Buttons
- Data Storage Concepts, Physical Storage Media, Memory Hierarchy
- File Organizations: Hashing Algorithm, Collision Handling
- Hashing, Hash Functions, Hashed Access Characteristics, Mapping functions, Open addressing
- Index Classification
- Ordered, Dense, Sparse, Multi-Level Indices, Clustered, Non-clustered Indexes
- Views, Data Independence, Security, Vertical and Horizontal Subset of a Table
- Materialized View, Simple Views, Complex View, Dynamic Views
- Updating Multiple Tables, Transaction Management
- Transactions and Schedules, Concurrent Execution, Serializability, Lock-Based Concurrency Control, Deadlocks
- Incremental Log with Deferred, Immediate Updates, Concurrency Control
- Serial Execution, Serializability, Locking, Inconsistent Analysis
- Locking Idea, DeadLock Handling, Deadlock Resolution, Timestamping rules