 |
Locking Idea, DeadLock Handling, Deadlock Resolution, Timestamping rules |
| << Serial Execution, Serializability, Locking, Inconsistent Analysis |

Database
Management System
(CS403)
VU
Lecture No.
45
Reading
Material
"Database
Systems Principles, Design
and Implementation" written by
Catherine Ricardo,
Maxwell
Macmillan.
Overview of Lecture:
o Deadlock
Handling
o Two
Phase Locking
o Levels of
Locking
o Timestamping
This is
the last lecture of our
course; we had started with transaction
management. We
were
discussing the problems in transaction in
which we discussed the
locking
mechanism. A
transaction may be thought of as an
interaction with the
system,
resulting
in a change to the system state.
While the interaction is in
the process of
changing
system state, any number of
events can interrupt the
interaction, leaving
the
state
change incomplete and the
system state in an inconsistent,
undesirable form.
Any change to
system state within a
transaction boundary, therefore,
has to ensure
that
the change leaves the system in a
stable and consistent
state.
318

Database
Management System
(CS403)
VU
Locking
Idea
Traditionally,
transaction isolation levels
are achieved by taking locks
on the data that
they
access until the transaction
completes. There are two primary
modes for taking
locks:
optimistic and pessimistic.
These two modes are
necessitated by the fact
that
when a
transaction accesses data, its
intention to change (or not change)
the data may
not be
readily apparent.
Some
systems take a pessimistic
approach and lock the data
so that other transactions
may read
but not update the data
accessed by the first
transaction until the
first
transaction
completes. Pessimistic locking guarantees that
the first transaction
can
always
apply a change to the data it first
accessed.
In an
optimistic locking mode, the
first transaction accesses data
but does not take
a
lock on
it. A second transaction may
change the data while the
first transaction is in
progress. If
the first transaction later
decides to change the data it accessed, it
has to
detect
the fact that the data is
now changed and inform the
initiator of the fact.
In
optimistic
locking, therefore, the fact
that a transaction accessed
data first does
not
guarantee
that it can, at a later
stage, update it.
At the
most fundamental level, locks
can be classified into (in
increasingly restrictive
order)
shared, update, and exclusive
locks. A shared lock
signifies that
another
transaction
can take an update or
another shared lock on the
same piece of data.
Shared
locks are used when data is
read (usually in pessimistic locking
mode).
An update
lock ensures that another
transaction can take only a
shared lock on the
same
data. Update locks are
held by transactions that intend to
change data (not just
read it).
If a transaction locks a piece of data
with an exclusive lock, no
other
transaction
may take a lock on the
data. For example, a
transaction with an
isolation
level of
read uncommitted does not
result in any locks on the
data read by the
transaction,
and a transaction with
repeatable read isolation can
take only a share
lock
on data it
has read.
319
Database
Management System
(CS403)
VU
DeadLock
A
deadlock occurs when the
first transaction has locks
on the resources that
the
second
transaction wants to modify,
and the second transaction
has locks on the
resources
that the first transaction
intends to modify. So a deadlock is
much like an
infinite
loop: If you let it go, it
will continue until the end
of time, until your
server
crashes,
or until the power goes
out (whichever comes first).
Deadlock is a situation
when
two transactions are waiting
for each other to release a
lock. The transaction
involved
in deadlock keeps on waiting unless
deadlock is over.
DeadLock
Handling
Following
are some of the approaches
for the deadlock
handling:
�
Deadlock
prevention
�
Deadlock
detection and
resolution
�
Prevention
is not always
possible
�
Deadlock
is detected by wait-for graph
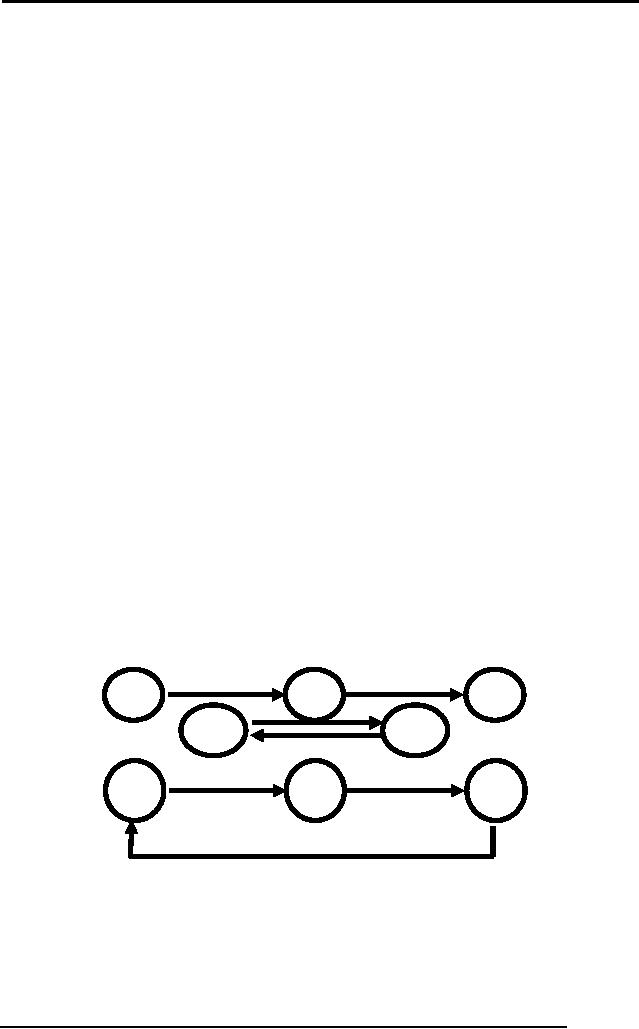
Wait
for Graph:
It is
used for the detection of
deadlock. It consists of nodes
and links. The nodes
represent transaction,
whereas
arrowhead represents that a transaction
has locked a particular data
item. We will see it
following
example:
TA
TB
TN
TA
TB
TC
TD
TA
Now in
this figure transaction A is
waiting for transaction B
and B is waiting for
N.
So it will
move inversely for releasing
of lock and transaction A will be
the last one to
execute.
In the second figure there
is a cycle, which represents
deadlock, this kind
of
320

Database
Management System
(CS403)
VU
cycle
can be in between two or
more transactions as well.
The DBMS keeps on
checking
for the cycle.
Two Phase
Locking
This
approach locks data and
assumes that a transaction is
divided into a
growing
phase, in
which locks are only
acquired, and a shrinking
phase, in which locks
are
only
released. A transaction that tries to
lock data that has been
locked is forced to
wait
and may deadlock. During
the first phase, the
transaction only acquires
locks;
during
the second phase, the
transaction only releases
locks. More formally, once
a
transaction
releases a lock, it may not
acquire any additional
locks. Practically,
this
translates
into a system in which locks
are acquired as they are
needed throughout a
transaction
and retained until the
transaction ends, either by
committing or aborting.
For
applications, the implications of
2PL are that long-running
transactions will hold
locks
for a long time. When
designing applications, lock
contention should be
considered.
In order to reduce the probability of
deadlock and achieve the
best level
of
concurrency possible, the
following guidelines are
helpful.
�
When
accessing multiple databases,
design all transactions so that
they access
the
files in the same
order.
�
If
possible, access your most
hotly contested resources last
(so that their
locks
are
held for the shortest time
possible).
�
If
possible, use nested transactions to
protect the parts of your
transaction most
likely to
deadlock.
321
Database
Management System
(CS403)
VU
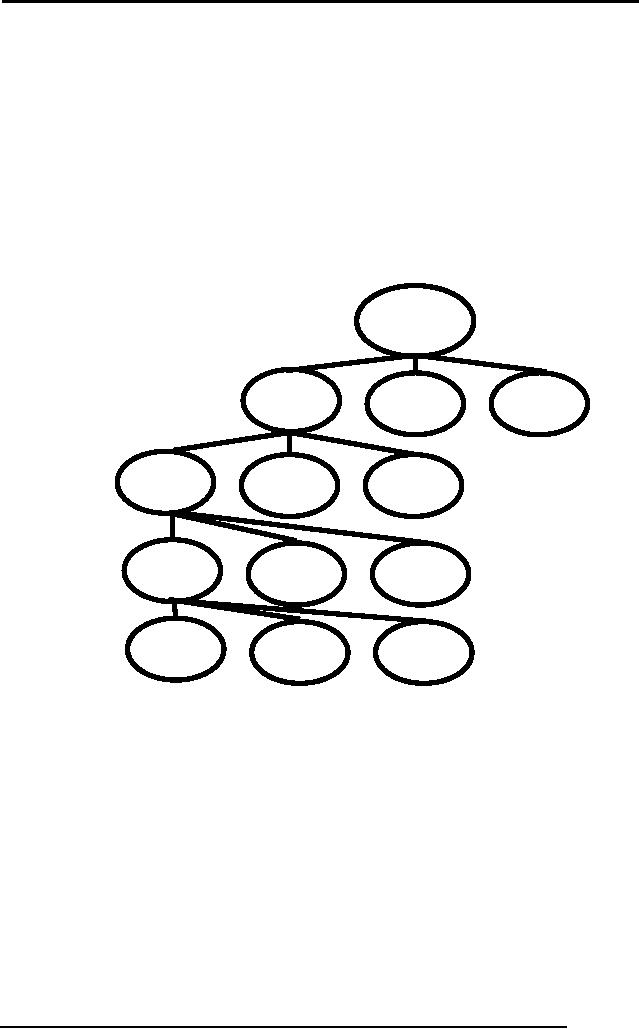
Levels of
Locking
�
Lock
can be applied on attribute,
record, file, group of files
or even entire
database
�
Granularity
of locks.
�
Finer
the granularity more
concurrency but more
overhead.
Greater
lock granularity gives you
finer sharing and
concurrency but higher
overhead;
four
separate degrees of consistency
which give increasingly
greater protection
from
inconsistencies
are presented, requiring increasingly
greater lock
granularity.
Databas
e
Area
Area
B
Area
C
A
File
File
File
A1
A2
A3
Rec
Rec
Rec
A11
A12
A13
At
At
At
A111
A112
A113
When a
lock at lower level is
applied, compatibility is checked upward.
It means
intimation
would be available in the
hierarchy till the database.
The granularity of
locks in
a database refers to how
much of the data is locked
at one time. A
database
server
can lock as much as the
entire database or as little as
one column of data. Such
extremes
affect the concurrency
(number of users that can
access the data)
and
locking
overhead (amount of work to
process lock requests) in
the server. By
locking
at higher
levels of granularity, the
amount of work required to
obtain and manage
locks is
reduced. If a query needs to read or
update many rows in a
table:
It can
acquire just one table-level
lock
�
It can
acquire a lock for each page
that contained one of the
required rows
�
It can
acquire a lock on each
row
�
322

Database
Management System
(CS403)
VU
Less
overall work is required to
use a table-level lock, but
large-scale locks can
degrade
performance, by making other
users wait until locks
are released. Decreasing
the
lock size makes more of
the data accessible to other
users. However, finer
granularity
locks can also degrade
performance, since more work is
necessary to
maintain
and coordinate the increased
number of locks. To achieve
optimum
performance,
a locking scheme must balance
the needs of concurrency and
overhead.
Deadlock
Resolution
If a set
of transactions is considered to be
deadlocked:
choose a
victim (e.g. the
shortest-lived transaction)
�
Rollback
`victim' transaction and restart
it.
�
The
rollback terminates the
transaction, undoing all its
updates and releasing
�
all of
its locks.
A message
is passed to the victim and
depending on the system the
transaction
�
may or
may not be started again
automatically.
Timestamping
Two-phase
locking is not the only
approach to enforcing database
consistency.
Another
method used in some DMBS is
timestamping. With timestamping,
there are
no locks
to prevent transactions seeing uncommitted
changes, and all physical
updates
are
deferred to commit
time.
Locking
synchronizes the interleaved
execution of a set of transactions in
such
�
a way
that it is equivalent to some
serial execution of those
transactions.
Timestamping
synchronizes that interleaved
execution in such a way that
it is
�
equivalent
to a particular serial order -
the order of the
timestamps.
Problems
of Timestamping
�
When a
transaction wants to read an item
that has been updated by a
younger
transaction.
�
A
transaction wants to write an
item that has been read or
written by a younger
transaction.
323

Database
Management System
(CS403)
VU
Timestamping
rules
The
following rules are checked
when transaction T attempts to change a
data item. If
the
rule indicates ABORT, then
transaction T is rolled back
and aborted (and
perhaps
restarted).
If T attempts to read
a data item which has
already been written to by a
�
younger
transaction then ABORT
T.
If T attempts to
write a data item which has
been seen or written to by a
�
younger
transaction then ABORT
T.
If
transaction T aborts, then
all other transactions which
have seen a data item
written
to by T must
also abort. In addition,
other aborting transactions can
cause further
aborts on
other transactions. This is a `cascading
rollback'.
Summary
In
today's lecture we have read
the locking mechanism and
prevention of deadlocks.
With
this we are finished with
our course. Locking is a
natural part of any
application.
However,
if the design of the
applications and transactions is not
done correctly, you
can
run into severe blocking
issues that can manifest
themselves in severe
performance
and scalability issues by
resulting in contention on
resources.
Controlling
blocking in an application is a matter of
the right application
design, the
correct
transaction architecture, a correct
set of parameter settings,
and testing your
application
under heavy load with
volume data to make sure
that the application
scales
well.
324
Table of Contents:
- Introduction to Databases and Traditional File Processing Systems
- Advantages, Cost, Importance, Levels, Users of Database Systems
- Database Architecture: Level, Schema, Model, Conceptual or Logical View:
- Internal or Physical View of Schema, Data Independence, Funct ions of DBMS
- Database Development Process, Tools, Data Flow Diagrams, Types of DFD
- Data Flow Diagram, Data Dictionary, Database Design, Data Model
- Entity-Relationship Data Model, Classification of entity types, Attributes
- Attributes, The Keys
- Relationships:Types of Relationships in databases
- Dependencies, Enhancements in E-R Data Model. Super-type and Subtypes
- Inheritance Is, Super types and Subtypes, Constraints, Completeness Constraint, Disjointness Constraint, Subtype Discriminator
- Steps in the Study of system
- Conceptual, Logical Database Design, Relationships and Cardinalities in between Entities
- Relational Data Model, Mathematical Relations, Database Relations
- Database and Math Relations, Degree of a Relation
- Mapping Relationships, Binary, Unary Relationship, Data Manipulation Languages, Relational Algebra
- The Project Operator
- Types of Joins: Theta Join, Equi–Join, Natural Join, Outer Join, Semi Join
- Functional Dependency, Inference Rules, Normal Forms
- Second, Third Normal Form, Boyce - Codd Normal Form, Higher Normal Forms
- Normalization Summary, Example, Physical Database Design
- Physical Database Design: DESIGNING FIELDS, CODING AND COMPRESSION TECHNIQUES
- Physical Record and De-normalization, Partitioning
- Vertical Partitioning, Replication, MS SQL Server
- Rules of SQL Format, Data Types in SQL Server
- Categories of SQL Commands,
- Alter Table Statement
- Select Statement, Attribute Allias
- Data Manipulation Language
- ORDER BY Clause, Functions in SQL, GROUP BY Clause, HAVING Clause, Cartesian Product
- Inner Join, Outer Join, Semi Join, Self Join, Subquery,
- Application Programs, User Interface, Forms, Tips for User Friendly Interface
- Designing Input Form, Arranging Form, Adding Command Buttons
- Data Storage Concepts, Physical Storage Media, Memory Hierarchy
- File Organizations: Hashing Algorithm, Collision Handling
- Hashing, Hash Functions, Hashed Access Characteristics, Mapping functions, Open addressing
- Index Classification
- Ordered, Dense, Sparse, Multi-Level Indices, Clustered, Non-clustered Indexes
- Views, Data Independence, Security, Vertical and Horizontal Subset of a Table
- Materialized View, Simple Views, Complex View, Dynamic Views
- Updating Multiple Tables, Transaction Management
- Transactions and Schedules, Concurrent Execution, Serializability, Lock-Based Concurrency Control, Deadlocks
- Incremental Log with Deferred, Immediate Updates, Concurrency Control
- Serial Execution, Serializability, Locking, Inconsistent Analysis
- Locking Idea, DeadLock Handling, Deadlock Resolution, Timestamping rules