 |

Database
Management System
(CS403)
VU
Lecture No.
43
Reading
Material
"Database
Systems Principles, Design
and Implementation"
Chapter
12
written
by Catherine Ricardo, Maxwell
Macmillan.
"Database
Management Systems" Second edition
written by
Chapter
18
Raghu
Ramakrishnan, Johannes
Gehkre.
Overview of
Lecture
o Incremental
log with deferred
updates
o Incremental
log with immediate
updates
o Introduction
to concurrency control
Incremental
Log with Deferred
Updates
We are
discussing the deferred updates approach
regarding the database
recovery
techniques.
In the previous lecture we
studied the structure of log
file entries for
the
deferred
updates approach. In today's lecture we
will discuss the recovery
process.
Write
Sequence:
First we
see what the sequence of
actions is when a write
operation is performed. On
encountering
a `write' operation, the
DBMS places an entry in the
log file buffer
mentioning
the effect of the write
operation. For example, if
the transaction
includes
the
operations:
.......
X = X +
10
Write
X
.......
Supposing
that the value of X before
the addition operation is 23
and after the
execution
of operation it becomes 33.
Now against the write
operation, the entry
made
in the
log file will be
302
Database
Management System
(CS403)
VU
<Tn,
X, 33>
In the
entry, Tn reflects the
identity of the transaction, X is
the object being
updated
and 33 is
the value that has to be
placed in X. Important point to be
noted here is that
the
log entry is made only for
the write operation. The
assignment operation and
any
other
mathematical or relational operation is
executed in RAM. For a `read'
operation
the
value may be read from the
disk (database) or it may already be in
RAM or cache.
But
the log entry results only
from a `write'
operation.
The
transaction proceeds in a similar
fashion and entries keep on
adding for the
write
operations.
When the `commit' statement is
executed then, first, the
database buffer
is
updated, that is the new
value is placed in the
database buffer. After that
the log file
is moved
to disk log file which
means that the log
file entries have been
made
permanent.
Then write is performed,
that is, the data from DB
buffer is moved to
disk.
There
may be some delay between
the execution of the commit
statement and the
actual
writing of data from
database buffer to disk.
Now, during this time if
system
crashes
then the problem is that
the transaction has been
declared as committed
whereas
the final result of the
object was still in RAM (in
database buffer) and due
to
system
crash the contents of the RAM
have been lost. The crash
recovery procedure
takes
care of this
situation.
The
Recovery Procedure
When
crash occurs, the recovery
manager (RM), on restart, examines the
log file from
the
disk. The transactions for
which the RM finds both
begin and commit
operations,
are
redone, that is, the
`write' entries for such
transactions are executed again.
For
example,
consider the example entries
in a log file
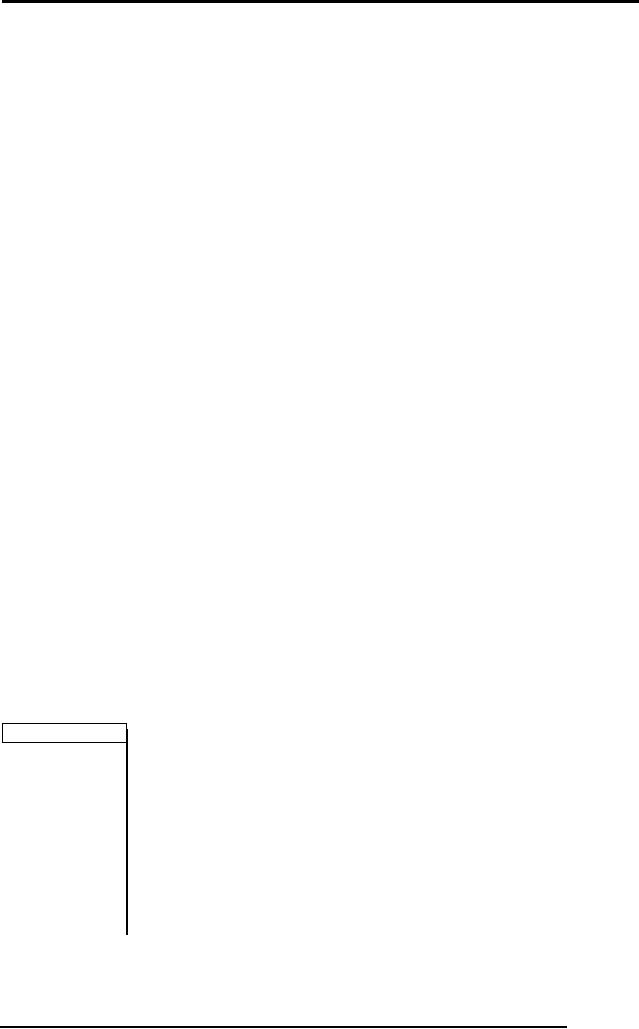
Log File
Entries
Here we find the begin
entries for
<T1, begin
>
T1, T2 and T3,
however,
the
<T1, X,
33>
commit entry is only
for T1. On
<T2,
begin>
restart
after the crash,
the
RM
<T1, Y,
9>
performs the write
operations of T1
<T2, A,
43>
again in the forward
order, that is,
it writes the value 33
for object X,
<T1, X,
18>
then writes 9 for Y
and writes 19
<T1, commit
>
for X
again. If some or all of these
<T2,
abort>
operations
have been
performed
<T3,
begin>
already,
writing them again will not
<T3, B,
12>
cause any
harm.
303

Database
Management System
(CS403)
VU
The RM
does not any action
for the transactions for
which there is only a begin
entry
or for
which there are begin
and abort entries, like T3
and T2 respectively.
A
question arises here, that
how far should the RM go
backward in the log file to
trace
the
transactions affected from the
crash that the RM needs to
Redo or ignore. The
log
file
may contain so many entries
and going too much
back or starting right from
the
start of
the log file will be
inefficient. For this purpose
another concept of
`checkpoint'
is used in the recovery
procedure.
Checkpoint:
Checkpoint
is also a record or an entry in the
log file. It serves as a
milestone or
reference
point in the log file. At
certain point in time the
DBMS enters a log
entry/record
in the log file and also
performs certain operations
listed below:
�
It moves
modified database buffers to
disk
�
All log
records from buffer to
disk
�
Writing a
checkpoint record to log;
log record mentions all
active
transactions
at the time
Now in
case of crash, the RM
monitors the log file up to
the last checkpoint.
The
checkpoint
guarantees that any prior
commit has been reflected in
the database. The
RM has to
decide which transactions to Redo
and which to ignore and RM
decides it
on the
following bases:
�
Transactions
ended before the checkpoint,
are ignored
altogether.
�
Transactions
which have both begin
and the commit entries,
are Redone.
It does
not matter if they are
committed again.
�
Transactions
that have begin and an
abort entry are
ignored.
�
Transactions
that have a begin and no
end entry (commit or
rollback) are
ignored
This
way checkpoint makes the
recovery procedure efficient. We
can summarize the
deferred
approach as:
304

Database
Management System
(CS403)
VU
�
Writes
are deferred until commit
for transaction is found
�
For
recovery purpose, log file
is maintained
�
Log file
helps to redo the actions
that may be lost due to
system crash
�
Log file
also contains checkpoint
records
Next, we
are going to discuss the
other approach of crash
recovery and that is
incremental
log with immediate
updates.
Incremental
Log with Immediate
Updates
Contrary
to the deferred updates, the
database buffers are updated
immediately as the
`write'
statement is executed and files
are updated when convenient.
The log file
and
database
buffers are maintained as in
the deferred update
approach. One effect
of
immediate
update is that the object
updating process needs not
to wait for the
commit
statement;
however, there is a problem
that the transaction in
which a `write'
statement
has been executed (and the
buffer has been updated
accordingly) may be
aborted
later. Now there needs to be
some process that cancels
the updation that
has
been
performed for the aborted
transaction. This is achieved by a
slightly different
log
file
entry/record. The structure of
log file entry for
immediate update technique
is
<Tr,
object, old_value, new_value>,
where Tr represents the
transaction Id, `object'
is
the
object to be updated, old_value
represents the value of
object before the
execution
of
`write' statement and new_value is
the new value of object.
Other entries of the
log
file in
immediate update approach are
just like those of deferred
update.
The
sequence of steps on write statement
is:
�
A log
record of the form <T, X,
old val, new val> is
written in the log
file
�
Database
buffers are updated
�
Log
record is moved from buffer
to the file
�
Database
is updated when
convenient
�
On commit
a log file entry is made in
the log file as <T,
commit>
Recovery
Sequence
305
Database
Management System
(CS403)
VU
In case
of a crash, the RM detects
the crash as before on restart
and after that
the
recovery
procedure is initiated. The transactions
for which the <Tr,
begin> and <Tr,
commit>
are found, those transactions are
redone. The redo process is
performed by
copying
the new value of the
objects in the forward
order. If these transactions
have
already
been successfully executed even
then this redo will not do
any harm and
the
final
state of the objects will be
the same. The transactions
for which a <Tr,
begin>
and
<Tr, abort> are found
or those transaction for which
only <Ts, begin> is
found,
such
transactions are undone. The
undo activity is performed by
executing the write
statements
in the reverse order till
the start of the transaction.
During this
execution,
the
old value of the objects
are copied/placed so all the
changes made by this
transaction
are cancelled.
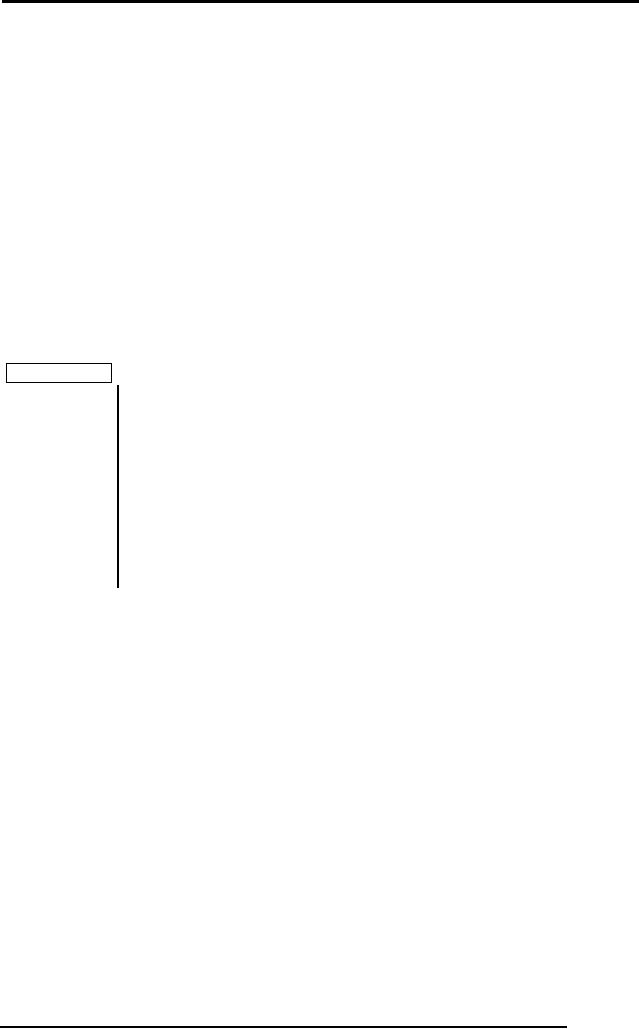
Log File
Entries
Here we
find the begin entries
for
T1, T2
and T3, however,
the
commit
entry is only for T1
and
<T1,
begin>
also
there is an abort entry for
T2.
<T1, X, 25,
33>
On
restart after the crash,
the RM
<T2,
begin>
<T1, Y, 5,
9>
performs
the write operations of
T1
<T2, A, 80,
43>
again in
the forward order, that
is,
<T1, X, 33,
18>
it writes
the value 33 for object
X,
<T1,
commit>
then
writes 9 for Y and writes
18
<T3 begin
>
for X
again. If some or all of
these
<T2, A, 43,
10>
operations
have been
performed
<T3, B, 12,
9>
already,
writing them again will
not
<T2,
abort>
cause
any harm.
To undo
the effects of T2 (which has
been aborted) the write
statements of T2 are
executed
in the reverse order copying
the old value from
the entry/record. Like,
here
the
second write statement of T2 that
had possibly written the
value 10 over 43,
now
43 will be
placed for A. Moving
backward we find another
write statement of T2 that
places 43
replacing 80. Now we pick
the old value, i.e., 80
and place this value
for A.
After
performing these operations
the effects of executing an
aborted T2 are
completely
eliminated, that is, the
object A contains value 80
that it had before
the
execution
of transaction T2. Same
process is also applied for
the transaction T3.
Checkpoints
are used in immediate updates
approach as well.
We have
discussed recovery procedure
both in deferred update and
immediate update.
Crash
recovery is an important aspect of a
DBMS, since in spite of all
precautions and
protections
the crashes happen. We can
minimize the frequency but
they cannot be
avoided
altogether. Once crash happens, the
purpose of recovery mechanism is
to
306

Database
Management System
(CS403)
VU
reduce
the effect of this crash as
much as possible and to
bring database in a
consistent
state and we have studied
how the DBMS performs
this activity.
Concurrency
Control
Concurrency
control (CC) is the second
part of the transaction
management. The
objective
of the CC is to control the
concurrent access of database by
multiple users at
the
same time called the
concurrent access.
First
questions is that why to
have the concurrent access.
The answer to this
question
refers to
very basic objective of the
database approach that is
sharing of data. Now
if
we are
allowing multiple users to
share the data stored in the
database, then how
will
they
access this data. One user
at a time? If so, it will be very
inefficient, we cannot
expect
the users to be that patient
to wait so long. At the same
time we have so
powerful
and sophisticated computer
hardware and software that
it will be a very bad
under-utilization
of the resources if allow
one user access at one
time. That is why
concurrent
access of the data is very
much required and
essential.
We are
convinced that concurrent
access is required, but if
not controlled properly
the
concurrent
access may cause certain
problems and those problems
may turn the
database
into an inconsistent state
and this is never every
allowed in the
database
processing.
The objective of CC is to allow
the concurrent access in
such a way that
these
problems due to concurrent
access are not encountered
or to maintain the
consistency
of the database in the
concurrent access. It is important to
understand that
CC only
takes care of the inconsistencies
that may possibly be
encountered due to
concurrent
access. Inconsistency due to
some other reasons is not
the concern of CC.
Problems
due to Concurrent
Access
If not
controlled properly, the
concurrent access may
introduce following
three
problems
in database:
�
Lost
Update Problem
�
Uncommitted
Update Problem
�
Inconsistent
Analysis Problem
We
discuss these problems one
by one
307

Database
Management System
(CS403)
VU
Lost
Update Problem
This
problem occurs when multiple
users want to update same
object at the same
time.
This
phenomenon is shown in the
table below:
TIME
TA
TB
BAL
t1
Read (BAL)
1000
t2
.......
Read
(BAL)
1000
t3
BAL = BAL -
50
........
1000
t4
Write
(BAL)
950
t5
.......
BAL = BAL +
10
950
t6
........
Write
(BAL)
1010
Table 1:
Lost update problem
This
first column represents the
time that acts as reference
for the execution of
the
statements.
As is shown in the table, at
time t1 transaction TA reads
the value of
object
`BAL' that supposedly be 1000. At
time t2, transaction TB
reads the value of
same
object `BAL' and also finds
the value as 1000. Now at
time t3, TA subtracts
50
of `BAL
and writes it at time t4. On
the other hand TB adds 10
into value of `BAL'
(that
she has already read as
1000) and writes the
value of `BAL'. Now since TB
wrote
the value after TA, the
update made by TA is lost, it
has been overwritten by
value of
TB. This is the situation
that reflects the lost
update problem.
This
problem occurred because
concurrent access to the
same object was
not
controlled
properly, that is,
concurrency control did not
manage the things
properly.
There
are two more situations
that reflect the problems of
concurrent access that
we
will
discuss in the next
lecture.
Summary
This
lecture concluded the discussion on
crash recovery where we
studied that the
main
tool used for recovery is
the log file. The
structure of records stored in the
different
types of log files is almost
the same, except for
the record that stores
the
record of
the change made in the
database as a result of a write
statement. The
deferred
update approach stores only
the new value of the
object in the log
file.
Whereas
the immediate update
approach stores the previous
as well as new value
of
the
object being updated. After
the crash recovery we started
the discussion on CC,
308

Database
Management System
(CS403)
VU
where we
were studying different
problems of CC; first of
them is the lost
update
problem
that we have discussed in
today's lecture, rest two
will be discussed in the
next
lecture.
309
Table of Contents:
- Introduction to Databases and Traditional File Processing Systems
- Advantages, Cost, Importance, Levels, Users of Database Systems
- Database Architecture: Level, Schema, Model, Conceptual or Logical View:
- Internal or Physical View of Schema, Data Independence, Funct ions of DBMS
- Database Development Process, Tools, Data Flow Diagrams, Types of DFD
- Data Flow Diagram, Data Dictionary, Database Design, Data Model
- Entity-Relationship Data Model, Classification of entity types, Attributes
- Attributes, The Keys
- Relationships:Types of Relationships in databases
- Dependencies, Enhancements in E-R Data Model. Super-type and Subtypes
- Inheritance Is, Super types and Subtypes, Constraints, Completeness Constraint, Disjointness Constraint, Subtype Discriminator
- Steps in the Study of system
- Conceptual, Logical Database Design, Relationships and Cardinalities in between Entities
- Relational Data Model, Mathematical Relations, Database Relations
- Database and Math Relations, Degree of a Relation
- Mapping Relationships, Binary, Unary Relationship, Data Manipulation Languages, Relational Algebra
- The Project Operator
- Types of Joins: Theta Join, Equi–Join, Natural Join, Outer Join, Semi Join
- Functional Dependency, Inference Rules, Normal Forms
- Second, Third Normal Form, Boyce - Codd Normal Form, Higher Normal Forms
- Normalization Summary, Example, Physical Database Design
- Physical Database Design: DESIGNING FIELDS, CODING AND COMPRESSION TECHNIQUES
- Physical Record and De-normalization, Partitioning
- Vertical Partitioning, Replication, MS SQL Server
- Rules of SQL Format, Data Types in SQL Server
- Categories of SQL Commands,
- Alter Table Statement
- Select Statement, Attribute Allias
- Data Manipulation Language
- ORDER BY Clause, Functions in SQL, GROUP BY Clause, HAVING Clause, Cartesian Product
- Inner Join, Outer Join, Semi Join, Self Join, Subquery,
- Application Programs, User Interface, Forms, Tips for User Friendly Interface
- Designing Input Form, Arranging Form, Adding Command Buttons
- Data Storage Concepts, Physical Storage Media, Memory Hierarchy
- File Organizations: Hashing Algorithm, Collision Handling
- Hashing, Hash Functions, Hashed Access Characteristics, Mapping functions, Open addressing
- Index Classification
- Ordered, Dense, Sparse, Multi-Level Indices, Clustered, Non-clustered Indexes
- Views, Data Independence, Security, Vertical and Horizontal Subset of a Table
- Materialized View, Simple Views, Complex View, Dynamic Views
- Updating Multiple Tables, Transaction Management
- Transactions and Schedules, Concurrent Execution, Serializability, Lock-Based Concurrency Control, Deadlocks
- Incremental Log with Deferred, Immediate Updates, Concurrency Control
- Serial Execution, Serializability, Locking, Inconsistent Analysis
- Locking Idea, DeadLock Handling, Deadlock Resolution, Timestamping rules