 |
Hashing, Hash Functions, Hashed Access Characteristics, Mapping functions, Open addressing |
| << File Organizations: Hashing Algorithm, Collision Handling |
| Index Classification >> |

Database
Management System
(CS403)
VU
Lecture No.
36
Reading
Material
"Database
Management Systems", 2nd edition, Raghu Ramakrishnan,
Johannes
Gehrke,
McGraw-Hill
Database
Management, Jeffery A
Hoffer
Overview of
Lecture
o Hashing
o Hashing
Algorithm
o Collision
Handling
In the
previous lecture we have
discussed file organization
and techniques of
file
handling.
In today's lecture we will study
hashing techniques, its
algorithms and
collision
handling.
Hashing
A hash
function is computed on some
attribute of each record.
The result of the
function
specifies in which block of
the file the record
should be placed
.Hashing
provides
rapid, non-sequential, direct
access to records. A key record
field is used to
calculate
the record address by
subjecting it to some calculation; a
process called
hashing.
For numeric ascending order
a sequential key record
fields this might
involve
simply using relative
address indexes from a base
storage address to access
records.
Most of the time, key
field does not have
the values in sequence that
can
directly
be used as relative record
number. It has to be transformed.
Hashing involves
computing
the address of a data item by
computing a function on the
search key value.
A hash
function h is a function from
the set of all search
key values K to the
set of all
bucket
addresses B.
265

Database
Management System
(CS403)
VU
�
We choose
a number of buckets to correspond to the
number of search key
values we
will have stored in the
database.
�
To
perform a lookup on a search
key value
, we
compute
,
and
search
the bucket with that
address.
�
If two
search keys i and
j
map to
the same address,
because
, then
the bucket at the address
obtained will contain
records
with both search key
values.
�
In this
case we will have to check the
search key value of every
record in
the
bucket to get the ones we
want.
�
Insertion
and deletion are
simple.
Hash
Functions
A good
hash function gives an
average-case lookup that is a
small constant,
independent
of the number of search
keys. We hope records are distributed
uniformly
among
the buckets. The worst
hash function maps all
keys to the same bucket.
The
best
hash function maps all
keys to distinct addresses.
Ideally, distribution of keys
to
addresses
is uniform and
random.
Hashed
Access Characteristics
Following
are the major
characteristics:
�
No
indexes to search or
maintain
�
Very
fast direct access
�
Inefficient
sequential access
�
Use
when direct access is needed,
but sequential access is
not.
Mapping
functions
The
direct address approach
requires that the function,
h(k), is a one-to-one
mapping
from
each k to integers in (1,m). Such a
function is known as a perfect
hashing
function:
it maps each key to a
distinct integer within some
manageable range and
enables us to
trivially build an O(1)
search time table.
Unfortunately,
finding a perfect hashing
function is not always
possible. Let's say
that
we can
find a hash function, h(k),
which maps most of the keys
onto unique integers,
but
maps a small number of keys
on to the same integer. If
the number of
collisions
266

Database
Management System
(CS403)
VU
(cases
where multiple keys map onto
the same integer), is
sufficiently small,
then
hash
tables work quite well
and give O(1) search
times.
Handling
the Collisions
In the
small number of cases, where multiple
keys map to the same
integer, then elements
with
different
keys may be stored in the
same "slot" of the hash
table. It is clear that when
the hash function
is used
to locate a potential match, it will be
necessary to compare the key
of that element with
the
search
key. But there may be more
than one element, which
should be stored in a single slot of
the table.
Various
techniques are used to
manage this problem:
�
Chaining,
�
Overflow
areas,
�
Re-hashing,
�
Using
neighboring slots (linear
probing),
�
Quadratic
probing,
�
Random
probing, ...
Chaining:
One
simple scheme is to chain
all collisions in lists attached to
the appropriate slot.
This
allows an unlimited number of
collisions to be handled and doesn't
require a
priori
knowledge of how many elements
are contained in the
collection. The
tradeoff
is the
same as with linked lists
versus array implementations of
collections: linked
list
overhead
in space and, to a lesser
extent, in time.
Re-hashing:
Re-hashing
schemes use a second hashing
operation when there is a
collision. If
there is
a further collision, we re-hash
until an empty "slot" in the
table is found.
The
re-hashing function can
either be a new function or a
re-application of the
original
one. As long as the
functions are applied to a
key in the same order,
then
a sought
key can always be
located.
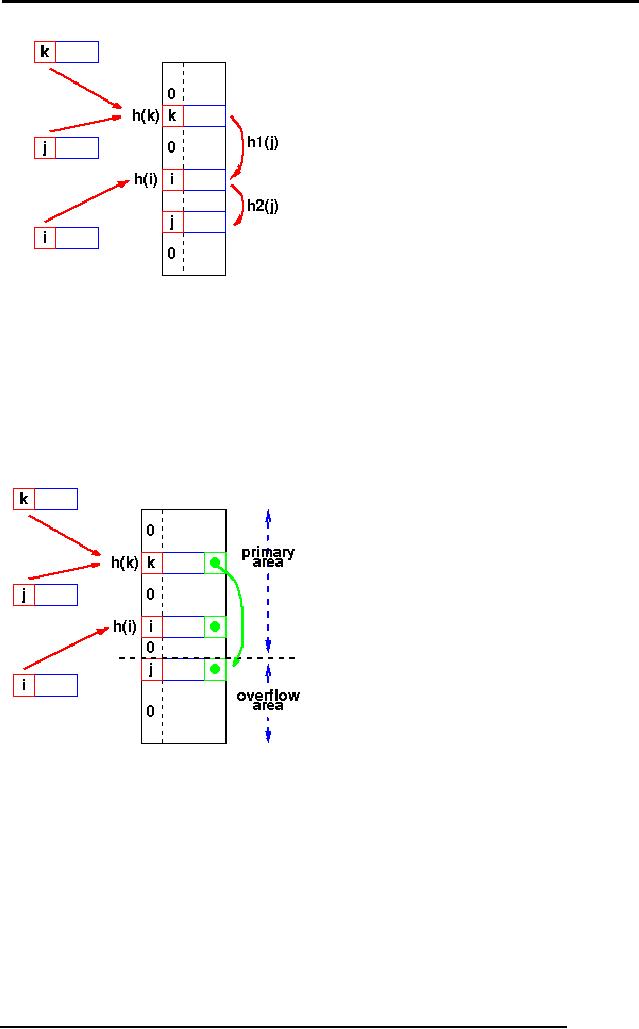
Linear
probing:
One of
the simplest re-hashing
functions is +1 (or -1), ie on a
collision; look in
the
neighboring
slot in the table. It calculates
the new address extremely
quickly and may
be
extremely efficient on a modern
RISC processor due to
efficient cache
utilization.
The
animation gives you a
practical demonstration of the
effect of linear probing:
it
also
implements a quadratic re-hash function
so that you can compare the
difference.
267
Database
Management System
(CS403)
VU
h(j)=h(k),
so the next hash function,
h1 is used. A second collision
occurs, so h2 is used.
Clustering:
Linear
probing is subject to a clustering
phenomenon. Re-hashes from
one location occupy a block
of
slots in
the table which "grows"
towards slots to which other
keys hash. This exacerbates
the collision
problem
and the number of re-hashed
can become large.
Overflow
area:
Another
scheme will divide the
pre-allocated table into two
sections: the primary area
to which keys
are
mapped and an area for
collisions, normally termed the
overflow area.
When a
collision occurs, a slot in
the overflow area is used
for the new element
and a
link
from the primary slot
established as in a chained system.
This is essentially
the
same as
chaining, except that the
overflow area is pre-allocated
and thus possibly
faster to
access. As with re-hashing,
the maximum number of elements must
be
known in
advance, but in this case,
two parameters must be estimated: the
optimum
size of
the primary and overflow
areas.
268

Database
Management System
(CS403)
VU
Of
course, it is possible to design
systems with multiple
overflow tables, or with
a
mechanism
for handling overflow out of
the overflow area, which
provide
flexibility
without losing the
advantages of the overflow
scheme.
Collision
handling
A
well-chosen hash function
can avoid anomalies which
are result of an excessive
number of
collisions, but does not
eliminate collisions. We need some
method for
handling
collisions when they occur.
We'll consider the following
techniques:
�
Open
addressing
�
Chaining
Open
addressing:
The
hash table is an array of
(key, value) pairs. The
basic idea is that when a
(key,
value)
pair is inserted into the
array, and a collision
occurs, the entry is
simply
inserted
at an alternative location in the
array. Linear probing,
double hashing, and
rehashing
are all different ways of
choosing an alternative location.
The simplest
probing
method is called linear
probing. In linear probing,
the probe sequence is
simply
the sequence of consecutive
locations, beginning with
the hash value of
the
key. If
the end of the table is
reached, the probe sequence
wraps around and
continues
at location 0. Only if the
table is completely full will
the search fail.
Summary
Hash Table
Organization:
Organization
Advantages
Disadvantages
Unlimited
number of elements
Overhead
of multiple linked
Chaining
Unlimited
number of collisions
lists
Re-hashing
Maximum
number
of
Fast
re-hashing
elements must be
known
Fast
access
through
use
of main
table space
Multiple
collisions
may
become
probable
Overflow
Fast
access
Two
parameters
which
area
Collisions
don't use primary
table
govern
performance
space
need to be
estimated
269
Table of Contents:
- Introduction to Databases and Traditional File Processing Systems
- Advantages, Cost, Importance, Levels, Users of Database Systems
- Database Architecture: Level, Schema, Model, Conceptual or Logical View:
- Internal or Physical View of Schema, Data Independence, Funct ions of DBMS
- Database Development Process, Tools, Data Flow Diagrams, Types of DFD
- Data Flow Diagram, Data Dictionary, Database Design, Data Model
- Entity-Relationship Data Model, Classification of entity types, Attributes
- Attributes, The Keys
- Relationships:Types of Relationships in databases
- Dependencies, Enhancements in E-R Data Model. Super-type and Subtypes
- Inheritance Is, Super types and Subtypes, Constraints, Completeness Constraint, Disjointness Constraint, Subtype Discriminator
- Steps in the Study of system
- Conceptual, Logical Database Design, Relationships and Cardinalities in between Entities
- Relational Data Model, Mathematical Relations, Database Relations
- Database and Math Relations, Degree of a Relation
- Mapping Relationships, Binary, Unary Relationship, Data Manipulation Languages, Relational Algebra
- The Project Operator
- Types of Joins: Theta Join, Equi–Join, Natural Join, Outer Join, Semi Join
- Functional Dependency, Inference Rules, Normal Forms
- Second, Third Normal Form, Boyce - Codd Normal Form, Higher Normal Forms
- Normalization Summary, Example, Physical Database Design
- Physical Database Design: DESIGNING FIELDS, CODING AND COMPRESSION TECHNIQUES
- Physical Record and De-normalization, Partitioning
- Vertical Partitioning, Replication, MS SQL Server
- Rules of SQL Format, Data Types in SQL Server
- Categories of SQL Commands,
- Alter Table Statement
- Select Statement, Attribute Allias
- Data Manipulation Language
- ORDER BY Clause, Functions in SQL, GROUP BY Clause, HAVING Clause, Cartesian Product
- Inner Join, Outer Join, Semi Join, Self Join, Subquery,
- Application Programs, User Interface, Forms, Tips for User Friendly Interface
- Designing Input Form, Arranging Form, Adding Command Buttons
- Data Storage Concepts, Physical Storage Media, Memory Hierarchy
- File Organizations: Hashing Algorithm, Collision Handling
- Hashing, Hash Functions, Hashed Access Characteristics, Mapping functions, Open addressing
- Index Classification
- Ordered, Dense, Sparse, Multi-Level Indices, Clustered, Non-clustered Indexes
- Views, Data Independence, Security, Vertical and Horizontal Subset of a Table
- Materialized View, Simple Views, Complex View, Dynamic Views
- Updating Multiple Tables, Transaction Management
- Transactions and Schedules, Concurrent Execution, Serializability, Lock-Based Concurrency Control, Deadlocks
- Incremental Log with Deferred, Immediate Updates, Concurrency Control
- Serial Execution, Serializability, Locking, Inconsistent Analysis
- Locking Idea, DeadLock Handling, Deadlock Resolution, Timestamping rules