 |

Lecture-20
Data
Duplication Elimination & BSN
Method
The
duplicate
elimination task is
typically performed after
most other transformation and
cleaning steps
have taken place, especially
after having cleaned single
-source errors and
conflicting
representations. It is performed either on
two cleaned sources at a time or on a
single
already
integrated data set. Duplicate
elimination requires to first
identify (i.e. match) simi lar
records
concerning the same real world
entity. In the second step,
similar records are merged
into
one
record containing all relevant attributes
without redundancy. Furthermore,
redundant records
are
removed.
Why
data duplicated?
A data
warehouse is created from
heterogeneous sources, with
heterogeneous databases
(different
schema/representation)
of the same entity.
The
data coming from outside the
organization owning the DWH
can have even lower
quality
data
i.e. different representation
for same entity, transcription or
typographical errors.
A data
warehouse is created by merging large
databases acquired from
different sources
with
heterogeneous
representations of information. This
raises the issue of data
quality, the foremost
being
identification and elimination of
duplicates, crucial for accurate
statistical analyses. Other
than
using own historical/transactional
data, it is not uncommon for large
businesses to acquire
scores of
databases each month, with a total
size of hundreds of millions t o
over a billion
records
that
need to be added to the
warehouse. The fundamental problem is
that the data supplied
by
various
sources typically include identifiers or string
data that are either
different among
different
datasets or
simply erroneous due to a variety of
reasons including typographical or
transcription
errors or
purposeful fraudulent activity, such as
aliases in the case of
names.
Problems
due to data
duplication
Data
duplication, can result in costly
errors, such as:
§ False
frequency distributions.
§
Incorrect
aggregates due to double
counting.
§
Difficulty
with catching fabricated identities by credit
card companies.
Without
accurate identification of duplicated
information frequency distributions and
various
other aggregates
will produce false or misleading
statistics leading to perhaps untrustworthy
new
knowledge and
bad decisions. Thus this has
become an increasingly important and
complex
problem for
many organizations that are
in the process of establishing a
data warehouse or
updating the
one already in
existence.
Credit
card companies routinely
assess the financial risk of potential
new customers who may
purposely hide
their true identities and thus
their history or manufacture new
ones.
The
sources of corruption of data
are many. To name a few,
errors due to data entry
mistakes,
faulty
sensor readings or more
malicious activities provide scores of
erroneous datasets
that
propagate
errors in each successive
generation of data.
153
Data
Duplication: Non-Unique PK
·
Duplicate
Identification Numbers
·
Multiple
Customer Numbers
Name
Phone
Number
Cust.
No.
M. Ismail
Siddiqi
021.666.1244
780701
M. Ismail
Siddiqi
021.666.1244
780203
M. Ismail
Siddiqi
021.666.1244
780009
·
Multiple
Employee Numbers
Bonus
Date
Name
Department
Emp.
No.
Jan.
2000
Khan
Muhammad
213
(MKT)
5353536
Dec.
2001
Khan
Muhammad
567
(SLS)
4577833
Mar.
2002
Khan
Muhammad
349
(HR)
3457642
Unable to
determine customer relationships
(CRM)
Unable to
analyze employee benefits
trends
What if
the customers are divided
amon g sales people to make
telephone calls? Maybe the
three
records of
the same person go to three
telesales people or maybe to
the same one, but arranged
as
per Cust.No.
The point is that no
telesales person would know
that a single customer is going
to
get
multiple calls from the
company, resulting in wastage of time and
resources of the
company,
and at
the same time annoying the
customer.
In the
other case, the employee is
same, who has been
moving among different
departments, and
possibly
during the process got new
employee numbers. He has
also been getting
bonuses
regularly, maybe
because every time he appears to be an
employee who has never got a
bonus.
This resulting
in loss to the company and
an inability of the company to do
any meaningful
employee benefit
analysis.
Data
Duplication: House
Holding
§
Group
together all records that
belong to the same
household.
......
S.
Ahad
440, Munir
Road, Lahore
...
......
................
....................................
...
......
No. 440,
Munir Rd, Lhr
Shiekh
Ahad
...
......
................
....................................
...
......
Shiekh Ahed
House # 440,
Munir Road, Lahore
...
Why
bother?
154
Why
bother?
In a joint
family system, many working
people live at the same
house, but have different
bank
accounts
and ATM cards. If the
bank would like to introduce a
new service and wants to get
in
touch
with its customers, it would
be much better if a single
letter is sent to a single
household,
instead of
sending multiple letters.
The problem is difficult
because multiple persons living at
the
same
house may have written
the same address differently
even worse, one person
with multiple
accounts at
the same bank may have
written his/her name and
address differently.
One month is a
typical business cycle in certain
direct marketing operations. This
means that
sources of
data need to be identified,
acquired, conditioned and then correlated
or merged within
a small portion
of a month in order to prepare mailings
and response analyses. With
tens of
thousands of
mails to be sent, reducing the
numbers of duplicate mails sent to
the same household
can
result in a significant savings.
Data
Duplication: Individualization
§
Identify
multiple records in each
household which represent
the same individual
.........
M.
Ahad
440, Munir
Road, Lahore
.........
................
....................................
.........
Maj
Ahad
440, Munir
Road, Lahore
Address
field is standardized, is this by
coincidence? This could be your luck
data, but don't
count on it
i.e. this is very unlikely
to be the default
case.
Formal
definition & Nomenclature
§
Problem
statement:
§ "Given
two databases, identify the
potentially matched records
Efficiently and
Effectively"
§
Many
names, such as:
§ Record
linkage
§ Merge/purge
§ Entity
reconciliation
§ List
washing and data
cleansing.
§
Current
market and tools heavily
centered towards customer
lists.
Within
the data warehousing field,
data cleansing is applied especially when
several databases are
merged.
Records referring to the
same entity are represented in
different formats in the
different
data
sets or are represented
erroneously. Thus, duplicate
records will appear in the
merged
database.
The issue is to identify and
eliminate these duplicates. The
problem is known as
the
155

merge/purge
problem. Instances of
this problem appearing in literature are
called record
linkage,
semantic
integration, instance identification, or o
bject identity problem.
Data
cleansing is much more than
simply updating a record with good
data. Serious data
cleansing
involves decomposing and
reassembling the data. One
can break down the
cleansing
into
six steps: elementizing,
standardizing, verifyin g, matching,
house holding, and
documenting.
Although
data cleansing can take
many forms, the current
marketplace and the current
technology
for
data cleansing are heavily
focused on customer
lists.
Need &
Tool Support
§
Logical solution
to dirty data is to clean it in
some way.
§
Doing it
manually is very slow and prone to
errors.
§
Tools
are required to do it "cost" effectively to
achieve reasonable quality.
§
Tools
are there, some for specific
fields, others for specific cleaning
phase.
§
Since
application specific, so work very well,
but need support from other
tools for
broad
spectrum of cleaning
problems.
For existing
data sets, the logical
solution to the dirty data
problem is to attempt to cleanse
the
data in
some way. That is, explore
the data set for
possible problems and endeavor to
correct the
errors. Of
course, for any real world
data set, doing this
task "by hand" is completely out of
the
question
given the amount of man
hours involved. Some
organizations spend millions of
dollars
per
year to detect data errors.
A manual process of data
cleansing is also laborious, time
consuming,
and itself prone to errors.
The need for useful and
powerful tools that automate
or
greatly assist
in the data cleansing
process are necessary and
may be the only practical
and cost
effective way to
achieve a reasonable quality level in an
existing data set.
A large variety
of tools is available in the
market to support data transformation
and data
cleaning
tasks, in particular for data
warehousing. Some tools
concentrate on a specific domain,
such as
cleaning name and address
data, or a specific cleaning
phase, such as data analysis
or
duplicate
elimination. Due to their restricted
domain, specialized tools typically
perform very
well but
must be complemented by other
tools to address the broad
spectrum of transformation
and
cleaning problems.
Overview of
the Basic Concept
§
In its
simplest form, there is an
identifying attribute (or combination)
per record for
identification.
§
Records
can be from single source or
multiple sources sharing
same PK or other common
unique
attributes.
§
Sorting performed on
identifying attributes and neighboring
records checked.
§
What if no
common attributes or dirty
data?
§
The
degree of similarity measured numerically,
different attributes may
contribute
differently.
156

In the
simplest case, there is an
identifying attribute or attribute
combination per record that
can
be used
for matching records, e.g.,
if different sources share
the same primary key or if
there are
other common
unique attributes. For
example people in income tax
department get
customer
details
from the phone company
and the Electricity Company
and want to identify customers
who
have
high electricity and high
telephone bill but do not pay
tax accordingly. Would be
the
common field,
NID, they have changed
over time, how about
addresses, too many ways to
write
addresses so
have to figure out common
attributes.
Instance
matching between different
sources is then achieved by a standard
equi-join on the
identifying
attribute(s), if you are very,
very lucky. In the case of a
single data set, matches
can be
determined by
sorting on the identifying attribute
and checking if neighboring
records match. In
both cases,
efficient implementations can be achieved
even for large data sets .
Unfortunately,
without
common key attributes or in
the presence of dirty data
such straightforward
approaches
are
often too restrictive. For example,
consider a rule that states
person records are likely
to
correspond if
name and portions of the
address match.
The
degree of similarity between
two records, often measured
by a numerical value between 0
and 1,
usually depends on application
characteristics. For instance, different
attributes in a
matching
rule may contribute different
weight to the overall degree
of similarity.
Basic
Sorted Neighborhood (BSN)
Method
§
Concatenate
data into one sequential
list of N records
§
Steps 1:
Create
Keys
§ Compute a
key for each record in the
list by extracting relevant fields or
portions
of
fields
§
Effectiveness of
the this method highly
depends on a properly chosen
key
§
Step 2:
Sort
Data
§ Sort
the records in the data list
using the key of step
1
§
Step 3:
Merge
§ Move a
fixed size window through
the sequential list of records
limiting the
comparisons
for matching records to
those records in the
window
§
If the
size of the window is w records
then every new record
entering the window
is compared
with the previous w-1
records.
1. Create
Keys: Compute a
key for each record in
the list by extracting relevant fields
or
portions of
fields. The choice of the
key depends upon an error model
that may be viewed as
knowledge intensive
and domain specific for the
effectiveness of the sorted
neighborhood
method.
This highly depends on a
properly chosen key with
the assumption that common
but
erroneous
data will have closely
matching keys .
2. Sort
Data: Sort
the records in the data list
using the key of step
-1.
3. Merge:
Move a
fixed size window through
the sequential list of records
limiting the
comparisons
for matching records to
those records in the window.
If the size of the window
is
157
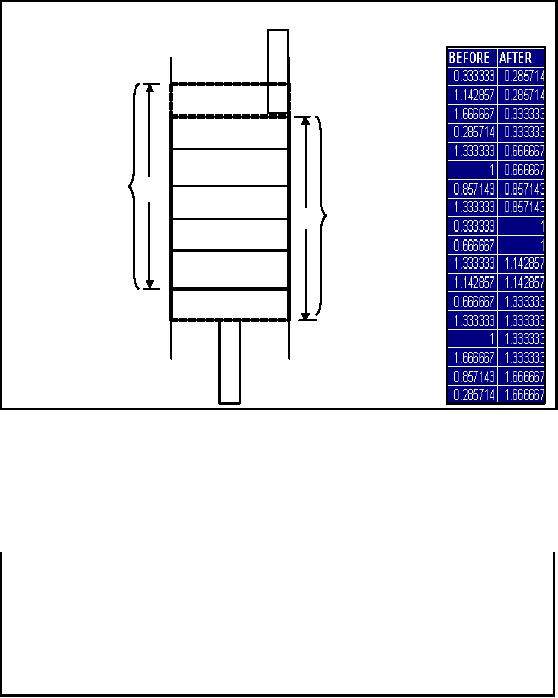
w records as
shown in Figure 20.1, then
every new record entering
the window is
compared
with
the previous w - 1 records to
find "matching" records. The
first record in the
window
slides out of
the window.
Note that in
the absence of a window, the
comparison would cover all
the sorted records i.e.
a
pair-wise
comparison, resulting in O (n2) comparisons.
BSN Method
: Sliding Window
.
.
.
Current
window
w
of
records
Next
w
window
of
records
.
.
.
Figure-20.1:
BSN Method: Sliding Window
Figure -20.1
shows the outcome of the
sliding window i.e. the
IDs sorted after completion of
the
run. The
outcome will also depend on
the window size, as it may
so happen that when
the
window
size is relatively small and
the keys are dispersed
then some (or most o f
the keys) may
not land in
their corresponding neighborhood, thus defeating
the purpose of the BSN
method.
One way of
overcoming this problem is working with
different window sizes in a
multipass
approach.
Complexity
Analysis of BSN Method
§
Time Complexi
ty: O(n log n)
§ O (n)
for Key Creation
§ O (n log
n) for Sorting
§ O (w n)
for matching, where w ≤ 2 ≤ n
§ Constants
vary a lot
§
At least
three passes required on the
dataset.
158

§
For large
sets disk I/O is
detrimental.
§
Complexity or
rule and window size
detrimental.
When
this procedure is executed
serially as a main memory
based process the create
keys phase is
an O(n)
operation the sorting phase is O(n
log n) and the merging
phase is O( wn) where n is
the
number of
records in the database. Thus,
the total time complexity of this
method is O (n log n) if
w < log n
, O(wn)
otherwise. However the
constants in the equations
differ greatly. It could be
relatively
expensive to extract relevant key
values from a record during
the create key
phase.
Sorting requires
a few machine instructions to
compare the keys. The
merge phase requires
the
application of a potentially
large number of rules to compare two
records and thus has
the
potential
for the largest constant
factor.
Notice
that w is a parameter of the
window scanning procedure.
The legitimate values of w may
range
from 2 (whereby only two
consecutive elements are
compared) to n (whereby each
element
is compared to
all others). The latter case
pertains to the full quadratic O
(n2) time process at
the
maximal
potential accuracy. The
former case (where w may be
viewed as a small
constant
relative to
n)
pertains to
optimal time performance (only O (n) time)
but at minimal
accuracy.
Note however
that for very large
databases the dominant cost is
likely disk I/O and
hence the
number of passes
over the data set. In
this case at least three
passes would be needed one
pass for
conditioning
the data and preparing
keys at least a second pass
likely more for a high speed
sort,
and a
final pass for window
processing and application of
the rule program for each
record
entering the
sliding window. Depending upon the
complexity of the rule program and
window
size w
the last pass may
indeed be the dominant
cost.
BSN
Method: Selection of
Keys
§
Selection of
Keys
§ Effectiveness
highly dependent on the key
selected to sort the records
middle
name
vs. last name,
§
A key is a
sequence of a subset of attributes or
sub -strings within the
attributes
chosen
from the record.
§
The
keys are used for sorting
the entire dataset with the
intention that matched
candidates
will appear close to each
other.
First
Middle
Address
NID
Key
MuhammedAhmad 440
Munir Road
34535322AHM440MUN345
MuhammadAhmad 440
Munir Road
34535322AHM440MUN345
MuhammedAhmed 440
Munir Road
34535322AHM440MUN345
MuhammadAhmar
440 Munawar Road
34535334AHM440MUN345
Table-20.1:
BSN Method: Selection of
Keys
The
key consists of the
concatenation of several ordered
fields or attributes in the
data. The first
three
letters of a middle name are
concatenated with the first
three letters of the first
name field
159

followed by
the address number field
and all of the consonants of
the road name. This is
followed
by the
first three digits of the
National ID field as shown in
Table 20.1.
These
choices are made since
the key designer determined
that family names are not
very
discriminating (Khan,
Malik andCheema). The first
names are also not
very discriminating and
are
typically misspelled (Muhammed, Muhammad, Mohamed)
due to mistakes in vocalized
sounds
vowels but middle names are
typically more uncommon and
less prone to being
misunderstood
and hence less likely to be
recorded incorrectly.
The
keys are now used
for sorting the entire dataset
with the intention that
all equivalent or
matching data
will appear close to each
other in the final sorted
list. Notice in table 20.1,
how the
first
and second records are
exact duplicates while the
third is likely to be the
same person but
with a
misspelled middle name i.e.
Ahmed instead of
Ahmad. We would
expect that this
phonetically bas
ed mistake will be caught by a
reasonable equational theory.
However the fourth
record although
having the exact same
key as the prior three
records appears unlikely to be
the
same
person.
BSN Method:
Problem with keys
§
Since
data is dirty, so keys WILL
also be dirty, and matching
records will not come
together.
§
Data
becomes dirty due to data
entry errors or use of abbreviations. Some real
examples
are as
follows:
Technology
Tech.
Techno.
Tchnlgy
§
Solution is to
use external standard source
files to validate the data
and resolve any
data
conflicts.
Since
the data is dirty and
the keys are extracted
directly from the data then
the keys for sorting
will
also be dirty. Therefore the
process of sorting the records to
bring matching records
togethe r
will not be as
effective. A substantial number of
matching records may not be
detected in the
subsequent
window scan.
Data
can become dirty due to
data entry errors. To speed
-up data entry abbreviations
are also
used
(all taken from the
telephone directory.), such
as:
Tehcnology,
Tech. Tehcno. Tchnlgy
The above is a
typical case of a non-PK error of
same entity with multiple
representations. To
ensure
the correctness of data in
the database, solution is using
external source files to
validate
the
data and resolve any data
conflicts.
160

BSN Method:
Problem with keys
(e.g.)
If contents of
fields are not properly
ordered, similar records
will NOT fall in the
same window.
Example:
Records 1 and 2 are similar
but will occur far
apart.
No
Name
Address
Gender
1 N. Jaffri,
SyedNo. 420, Street 15,
Chaklala 4, Rawalpindi M
2 S.
Noman
420,
Scheme 4, Rwp
M
3 Saiam
Noor Flat 5, Afshan Colony, Saidpur
Road, Lahore F
Solution is to
TOKENize the fields i.e.
break them further. Use
the tokens in different
fields for
sorting to fix
the error.
Example: Either
using the name or the
address field records 1 and
2 will fall close.
No
Name
Address
Gender
1
Syed N
Jaffri
420 15 4
Chaklala No Rawalpindi Street
M
2
Syed
Noman
420 4
Rwp Scheme
M
3
Saiam
Noor
5 Afshan Colony
Flat Lahore Road
Saidpur
F
We observe that
characters in a string can be grouped
into meaningful pieces. We
can often
identify
important components or tokens within a
Name or Address field by
using a set of
delimiters such
as space and punctua tions.
Hence we can first tokenize
these fields and then
sort
the
tokens within these fields.
Records are then sorted on
the select key fields;
note that this
approach is an
improvement over the standard BSN
method.
BSN Method:
Matching Candidates
Mergin g of
records is a complex inferential
process.
Example-1:
Two
persons with names spelled
nearly but not identically, have the
exact same
address. We
infer they are same
person i.e. Noma Abdullah
and Noman Abdullah.
Example-2:
Two
persons have same National ID
numbers but names and
addresses are
completely
different. We infer same
person who changed his
name and moved or the
records
represent
different persons and NID is
incorrect for one of
them.
Use of
further information such as
age, gender etc. can alter
the decision.
Example-3:
Noma-F
and Noman-M we could perhaps infer
that Noma and Noman are
siblings
i.e.
brothers and sisters.
Noma-30 and Noman-5 i.e.
mother and son.
The
comparison of records during
the merge phase to determine
their equivalenc e is a complex
inferential
process that considers and
requires much more information in
the compared records
than
the keys used for sorting.
For example suppose two
person names are spelled
nearly but not
identically, and
have the exact same
address. We might infer they
are the same person.
For
161

example
Noma Abdullah and Noman
Abdullah could be the same
person if they have the
same
address.
On the
other hand suppose two
records have exactly the
same National ID numbers but
the names
and
addresses are completely
different. We could either assume the
records represent the
same
person
who changed his name
and moved or the records
represent different persons
and the NID
number
field is incorrect for one
of them. Without any further
information we may
perhaps
assume
the latter. The more
information there is in the
records the better
inferences can be
made.
For
example, if gender and age
information is available in some
field of the data
(Noma-F,
Noman-M) we
could perhaps infer that Noma
and Noman are
siblings.
BSN Method:
Equational Theory
To specify the
inferences we need equational
Theory.
§
Logic is
NOT based on string equivalence.
§
Logic
based on domain equivalence.
§
Requires
declarative rule language.
To specify
the inferences as discussed above we
need an equational theory in
which the logic is
based not on
the string equivalence but on the domain equivalence.
A natural approach to
specifying an equational
theory and making it practical too would be
the use of a declarative
rule
language. Rule
languages have been effectively
used in a wide range of
applications requiring
inference over
large data sets. Much
research has been conducted
to provide efficient means
for
their
compilation and evaluation
and this technology can be exploited
here for purposes of
data
cleansing
efficiently.
BSN Method:
Rule Language
§
Rule Language
Example
Given
two records r1 and r2
IF the
family_name of r1 equals the family_name of
r2
AND
the first names differ
slightly
AND
the address of r1 equals the
address of r2
THEN r1 is
equivalent to r2
This is
rather self explanatory. The
rule merely states that if
for two records the
last names and
the
addresses are same, but the
first names differ slightly,
then both the records are
same. This
makes
sense, as using default values l st
names can be easily fixed,
and sorting the address
and
a
then
using default values can fix
most part of the address
too, as the addresses are
repeating.
162

BSN
Method: Mis -Matching
Candidates
§
Transposition of
names
§
How do
you specify "Differ
Slightly"?
§ Calculate
on the basis of a distance
function applied to the family_name
fields of
two
records
§
Multiple
options for distance
functions
Notice
that rules do not necessarily
need to compare values from
the same attribute or
same
domain.
For instance to detect a
transposition in a persons name we could
write a rule that
compares
the first name of one record
with the last name of
the second record and the
last name
of the
first record with the first
name of the second
record.
BSN Method:
Distance Metrics
§
Distance
Functions
§ Phonetic
distance
§ Typewriter
distance
§ Edit
Distance
§
A widely
used metric to define string
similarity
§ Ed(s1,s2)=
minimum # of operations (insertion,
deletion, substitution) to
change
s1 to s2
§
Example:
s1:
Muhammad Ehasn
s2:
Muha mmed Ahasn
ed(s1,s2) =
2
The
implementation is based upon the
computation of a distance function
applied to the first
name
fields of two records and
the comparison of its
results to a threshold to capture
obvious
typographical errors
that may occur in the
data. The selection of a
distance function and a
proper
threshold is
also a knowledge intensive activity that
demands experimental evaluation.
An
improperly
chosen threshold will lead
to either an increase in the number of falsely
matched
records or to a
decrease in the number of matching
records that should be
merged. A number of
alternative
distance functions for typographical
mistakes are possible,
including distances
based
upon (i) edit
distance (ii) phonetic
distance and (iii)
typewriter distance.
163

Limitations
of BSN Method
§
BSN Method
Limitations
§ No single
key is sufficient to catch
all matching records.
§
Fields
that appear first in the
key have higher discriminating power than
those
appearing after
them.
§
If NID number is
first attribute in the key
81684854432 and 18684854432
are
highly
likely to fall in windows
that are far
apart.
§
Two
Possible Modifications to BSN
Method
§ Increase
w, the
size of window
§ Multiple
passes over the data
set
In general no single
key will be sufficient to
catch all matching records.
The attributes or
fields
that
appear first in the key
have higher discriminating power
than those appearing after
them.
Hence if
the error in a record occurs in
the particular field or
portion of the field that is
the most
important part
of the key there may be
little chance a record will
end up close to a
matching
record after
sorting. For instance if an employee
has two records in the
database one with
NID
number 81684854432
and another with NID number
18684854432 (the first two
numbers were
transposed)
and if the NID number is
used as the principal field
of the key then it is very
unlikely
both records
will fall under the same
window i.e. the two
records with transposed NID
numbers
will be
far apart in the sorted list
and hence they may not be
merged. As it was
empirically
established
that the number of matching
records missed by one run of
the sorted neighborhood
method
can be large unless the neighborhood
grows very large.
Increasing
w
§
Increases
the computational complexity.
§
Quality does
not increase
dramatically.
§
Not useful
unless the window spans
the entire database.
§ W spanning
the entire set of rows is infeasible
under strict time and
cost
constraints.
§
What
would be the computational
complexity?
§
O(w2)
Increasing w clearly this
increases the computational complexity
and as discussed in the
next
section
does not increase dramatically the number
of similar records merged in
the test cases we
ran unless of
course the window spans
the entire database which we
have presumed is infeasible
under strict
time and cost
constraints.
164

Multi-pass
Approach
§
Several
independent runs of the BSN
method each time with a
different key and a
relatively
small window.
§
Each
independent run will produce
a set of pairs of records
which can be merged
(takes
care of
transposition errors)
§
Apply
the transitive closure property to those
pairs of records.
§ If records
a and b are found to be
similar and at the same time
records b and c are
also
found to be similar the transitive
closure step ca n mark a and
c to be similar.
§
The
results will be a union of
all pairs discovered by all
independent runs with
no
duplicates
plus all those pairs
that can be inferred by
transitivity of equality.
The
alternative strategy we implemented is to
execute sev eral independent
runs of the sorted
neighborhood
method each time using a
different key and a
relatively small window. We call
this
strategy
the multipass approach. For
instance in one run we use
the address as the principal
part
of the
key while in another run we
use the last name of
the employee as the
principal part of the
key.
Each independent run will
produce a set of pairs of
records which can be merged.
We then
apply the
transitive closure to those
pairs of records.
The
results will be a union of a ll
pairs discovered by all
independent runs with no
duplicates plus
all
those pairs that can be
inferred by transitivity of equality. The
reason this approach works
for
the
test cases explored here
has much to do with the
nature of the errors in the data.
Transposing
the
first two digits of the NID
number leads to nonmergeable records as
we noted. However in
such
records the variability or
error appearing in another
field of the records may
indeed not be so
large. Therefore
although the NID numbers in
two records are grossly in
error the name
fields
may not
be. Hence first sorting on
the name fields as the
primary key will bring
these two records
closer
together, lessening the negative
effects of a gross error in
the social security
field.
165
Table of Contents:
- Need of Data Warehousing
- Why a DWH, Warehousing
- The Basic Concept of Data Warehousing
- Classical SDLC and DWH SDLC, CLDS, Online Transaction Processing
- Types of Data Warehouses: Financial, Telecommunication, Insurance, Human Resource
- Normalization: Anomalies, 1NF, 2NF, INSERT, UPDATE, DELETE
- De-Normalization: Balance between Normalization and De-Normalization
- DeNormalization Techniques: Splitting Tables, Horizontal splitting, Vertical Splitting, Pre-Joining Tables, Adding Redundant Columns, Derived Attributes
- Issues of De-Normalization: Storage, Performance, Maintenance, Ease-of-use
- Online Analytical Processing OLAP: DWH and OLAP, OLTP
- OLAP Implementations: MOLAP, ROLAP, HOLAP, DOLAP
- ROLAP: Relational Database, ROLAP cube, Issues
- Dimensional Modeling DM: ER modeling, The Paradox, ER vs. DM,
- Process of Dimensional Modeling: Four Step: Choose Business Process, Grain, Facts, Dimensions
- Issues of Dimensional Modeling: Additive vs Non-Additive facts, Classification of Aggregation Functions
- Extract Transform Load ETL: ETL Cycle, Processing, Data Extraction, Data Transformation
- Issues of ETL: Diversity in source systems and platforms
- Issues of ETL: legacy data, Web scrapping, data quality, ETL vs ELT
- ETL Detail: Data Cleansing: data scrubbing, Dirty Data, Lexical Errors, Irregularities, Integrity Constraint Violation, Duplication
- Data Duplication Elimination and BSN Method: Record linkage, Merge, purge, Entity reconciliation, List washing and data cleansing
- Introduction to Data Quality Management: Intrinsic, Realistic, Orrs Laws of Data Quality, TQM
- DQM: Quantifying Data Quality: Free-of-error, Completeness, Consistency, Ratios
- Total DQM: TDQM in a DWH, Data Quality Management Process
- Need for Speed: Parallelism: Scalability, Terminology, Parallelization OLTP Vs DSS
- Need for Speed: Hardware Techniques: Data Parallelism Concept
- Conventional Indexing Techniques: Concept, Goals, Dense Index, Sparse Index
- Special Indexing Techniques: Inverted, Bit map, Cluster, Join indexes
- Join Techniques: Nested loop, Sort Merge, Hash based join
- Data mining (DM): Knowledge Discovery in Databases KDD
- Data Mining: CLASSIFICATION, ESTIMATION, PREDICTION, CLUSTERING,
- Data Structures, types of Data Mining, Min-Max Distance, One-way, K-Means Clustering
- DWH Lifecycle: Data-Driven, Goal-Driven, User-Driven Methodologies
- DWH Implementation: Goal Driven Approach
- DWH Implementation: Goal Driven Approach
- DWH Life Cycle: Pitfalls, Mistakes, Tips
- Course Project
- Contents of Project Reports
- Case Study: Agri-Data Warehouse
- Web Warehousing: Drawbacks of traditional web sear ches, web search, Web traffic record: Log files
- Web Warehousing: Issues, Time-contiguous Log Entries, Transient Cookies, SSL, session ID Ping-pong, Persistent Cookies
- Data Transfer Service (DTS)
- Lab Data Set: Multi -Campus University
- Extracting Data Using Wizard
- Data Profiling