 |
Classical SDLC and DWH SDLC, CLDS, Online Transaction Processing |
| << The Basic Concept of Data Warehousing |
| Types of Data Warehouses: Financial, Telecommunication, Insurance, Human Resource >> |
Lecture
Handout
Data
Warehousing
Lecture
No. 04
Starts
with a 6x12 availability requirement
... but 7x24 usually becomes
the goal.
�
Decision
makers typically don't work 24
hrs a day and 7 days a
week. An ATM system
does.
�
Once
decision makers' start using
the DWH, and start
reaping the benefits, they
start
liking
it...
�
Start
using the DWH more often,
till want it available 100% of
the time.
�
For
business across the globe,
50% of the world may be
sleeping at any one time,
but the
businesses
are up 100% of the
time.
�
100%
availability not a trivial
task, need to take into
loading strategies, refresh rates
etc.
If we look at
the availability requirements
for a data warehouse,
normally you start out with
6
days a
week, 12 hours a day. The
decision makers are not
going to come during the
middle of a
weekend to
ask marketing questions. They
don't normally do that. They
don't come in
midnight
to ask
these questions either. However, a
transaction processing system,
like the ATM systems,
should be
available all the time. I
can go to an ATM at midnight if I want
to, and withdraw
money.
That's not usually the requirement in the
beginning of the data
warehouse project, but as
the
data warehouse matures,
availability becomes much
more important. Because the
decision
makers
start accessin g and using
the data more often. They
start doing maybe
interactive kind of
analysis in
the day and data
mining kind of things over
night. We will talk more about
data
mining later. So
you can start out with 6� 12 availability
but will usually evolve in to
7�24 over
a
period of time.
So one of the things we are
going to talk about,
although there will not be a
major
focus is
about the tradeoffs that you
make in availability. How do I
design my data warehouse
for
100%
availability? So that it is always
available for quires. And it
turns out that there are
very
subtle
interactions between availability
and data loading. How do I
make sure the data is
available
for
querying while uploading the
data? These issues turn out
to have some tricky
subtleties in that
kind of
environment.
Does not
follows the traditional development
model
19
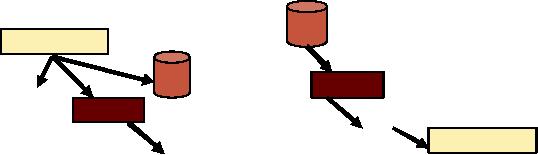
DWH
Requirements
Program
�
4
Program
4
Requirements
Classical
SDLC
DWH
SDLC (CLDS)
� Requirements
gathering
� Implement
warehouse
� Analysis
� Integrate
data
� Design
� Test for
biasness
� Programming
� Program
w.r.t data
� Testing
� Design DSS
system
� Integration
� Analyze
results
� Implementation
� Understand
requirement
Figure-4.1:
Comparison of SDLC &
CLDS
Operational environment is
created using the classical
systems development life cycle.
The DWH
on the
other hand operates under a
very different life cycle.
Sometimes called CLDS i.e.
the
reverse of
SDLC. The classical SDLC is
requirement driven. In order to build
the system, you
must
first understand the end
user or business user
requirements. Then you go into the
stages of
design
and development typically taught in software
engineering. The CLDS is
almost exactly the
reverse of
SDLC. The CLDS starts
with the data. Once
the data is in hand, it is
integrated, and
then
tested to see what bias
there is, if any. Programs
are then written against
the data. The
results
are
analyzed, and finally the
requirements of the system
are understood. Some Data
Warehouse
developers/vendors
oversuse this "natural"
approach and add extensive
charges for adding
features or
enhancing features already present
once the end users
get the "hang" of the
system.
The
CLDS is a classical data
driven development life cycle.
Trying to apply inappropriate
tools
and
techniques of development will only
result in waste of effort/resources
and confusion
20
Typical
queries
OLTP (On Li ne Trans acti on Proc essing) specifi c query
Select
tx_date, balance from
tx_table
Where
account_ID = 23876;
DWH specific query
Select
balance, age, sal, gender
from customer_table and
tx_table
Where age
between (30 and 40)
and
Education =
`graduate' and
CustID.customer_table =
Customer_ID.tx_table;
Lets
take a brief look a the
two queries, the results of
comparing them are summarized in
table
4.1
below:
OLTP
DWH
Primary
key used
Primary
key NOT used
No concept of
Primary Index
Primary index
used
May
use a single table
Uses multiple
tables
Few rows
returned
Many rows
returned
High selectivity
of query
Low selectivity
of query
Indexing on
primary key (unique)
Indexing on
primary index (non-unique)
Table-4.1:
Comparison of OLTP and DWH
for given queries
Data
Warehouse
OLTP
Scope
* Application
Neutral
* Application
specific
* Single source
of "truth"
* Multiple
databases with repetition
* Evolves
over time
* Off
the shelf application
* How to
improve business
* Runs
the business
Data
* Historical,
detailed data
* Operational
data
Perspective
* Some
summary
* No
summary
* Lightly
denormalized
* Fully
normalized
Queries
* Hardly uses
PK
* Based on
PK
* Number of
results returned
* Number of
results returned in
hundreds
in
thousands
Time
factor
* Minutes to
hours
* Sub
seconds to seconds
* Typical
availability 6x12
* Typical
availability 24x7
Table-4.2:
Detailed comparison of OLTP
and DWH
Comparisons of
response times
�
On-line
analytical processing (OLAP)
queries must be executed in a
small nu mber of
seconds.
� Often
requires denormalization and/or
sampling.
�
Complex query
scripts and large list selections
can generally be executed in a
small
number of
minutes.
21
�
Sophisticated
clustering algorithms (e.g., data
mining) can generally be executed in
a
small number of
hours (even for hundreds of
thousands of customers).
So there is
one class of decision
support environment called OLAP
(Online Analytical
Processing).
The idea is that I am doing
iterative decision making, using
point and clicking,
drilling
down into data, and
refining my decision model and I
should be able to "execute"
queries
in an OLAP
environment in a small number of seconds.
How is it possible to execute
queries in a
small
numbers of seconds? And
potentially working with
billions of rows of data? I
have to be a
bit
clever here. I have to
consider special techniques
like sampling, like de-normalization,
special
indexing
techniques and other smart
kinds of techniques. We will talk
about those
techniques
when we go to
the relevant parts. And how
do I design a database which
has these
characteristics?
If I have got
complex combination of tables and a large
list selection and if it takes
small number
of minutes
that's acceptable. If I got a lot of
iterative analysis to do by pulling a lis
t of names and
customers
and some information about
them to send a direct mail to
those customers, then it
is
acceptable to
assume that that such
queries don't have to be
executed in few seconds. Of
course
as long as I am
going to find them, it's
all right .
Putting
the pieces
together
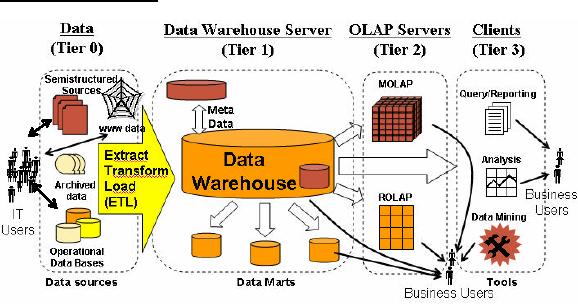
Figure-4.2:
Putting the pieces
together
Figure 4.2 gives
a complete picture of how different
"pieces" of a data warehouse
fit together. We
start
with extracting data from
different sources, transform and
clean that data and
then load it
into
the data warehouse. The
data warehouse itself has to
have specialized schemas to
give quick
answers to
typical macroscopic queries. Data
marts are created out of the
data warehouse to
service
the needs of different
departments such as marketing,
sales etc such that
they don't have
to work
with the heavy load of the
complete data warehouse.
Once the data warehouse is
in place
(as
briefly discussed before)
data cubes are created
for OLAP based drill -down
"all" possible
queries.
And we move further and
use smart tools such as
data mining clustering
and
classification
techniques.
22

Why
this is hard?
�
Data
sources are unstructured &
heterogeneous.
�
Requirements
are always changing.
�
Most computer
scientist trained on OTLP systems,
those concepts not valid for
VLDB &
DSS.
�
The
scale factor in VLDB implementations is
difficult to comprehend.
�
Performance
impacts are often non-linear
O(n) Vs. O(nlog_n) e.g.
scanning vs. indexing.
�
Complex
computer/database architectures.
�
Rapidly
changing product characteristics.
�
And so
on...
In early days of
data warehousing you would
never even conceive giving
business end user
access to
the data. They would
always have to go through a data
center, some kind of
reporting or
MIS
system, that's really not tru e
any more. The hard part of
the problem now is
architecting,
designing and
building these systems. And
it is particularly hard at the high
end. Because in a
data
warehouse environment, there are no
stable requirements-change is constant.
This is one of
the main
reasons why SDLC system
dose not work. By the time
you collect all the
requirements
following
the SDLC approach and
start designing the system
the requirements may
have
completely
changed. They are completely
meaningless. Because any
question that was
interesting
6 months
ago is definitely not interesting
today.
The other
issue is with very large
databases scale dose strange
things in the environment.
And
this is
very important for computer
scientist to understand because at
small scale (i.e. hundreds
of
rows) an O(n
log n) algorithm and an O(n 2) algorithms are not much
different in terms of
performance. It
dose not matter if you are
using bubble sort or a heap
sort for small amount
of
data; nobody
cares as the difference in performance is
not noticeable. However, when you
get
millions of
records or a billion records,
then it starts to hurt. So when you
get very large data
bases,
and manipulating large amount of data
because we are retaining history,
this becomes a big
problem
and a proper desi n is required to be in
place. Else the scale
will kill you. The
difference
g
between
O(n log n) and an
O(n2) is huge when you
get to billions of
records.
High
level implementation
steps
Phase-I
1. Determine
Users' Needs
2. Determine
DBMS Server Platform
3. Determine
Hardware Platform
4. Information
& Data Modeling
5. Construct
Metadata Repository
Phase-II
6. Data
Acquisition & Cleansing
7. Data
Transform, Transport &
Populate
23
8. Determine
Middleware Connectivity
9. Prototyping,
Querying & Reporting
10. Data
Mining
11. On
Line Analytical Processing
(OLAP)
Phase-III
12.
Deployment & System
Management
If you
look at the high level
implementations steps for a
data warehouse it is important that
you
are
driving the design of the
data warehouse in the
context of the data
warehouse by the
business
requirements,
and not driven by the
technology.
So you start
with the business
requirements and say ok what
problems I am trying to solve
here.
Am I going to do
fraud detection or do customer
retention analysis? What are
the specifications
of the
problems that we have
discussed? And identify the
key source of these problems
so you
can
understand what is going to be the
cost and time required to fix
them. But make sure this
is
done in
the context of a logical
data model that expresses
the underlying business relationship
of
the
data.
The
data warehouse should be
able to support multiple
applications, multiple workloads against
a
single source of
truth for the organization. So by
identifying the business opportunity,
you
identify
the information required, and
then in the next stage,
how to schedule those
deliverables
that
are most important to the
business. Ask yourself, what can I do in
a 90 days time period to
deliver
values to the business? And
then based on what I have
decided here do the software
and
hardware
selection. Remember that software is
hardware, and hardware is easy ware.
Because the
software is much
more complex to scale
(algorithm complexity) then the
hardware. Hardware is
getting cheaper
over time. So you drive typically
from the software not the
hardware.
24
Table of Contents:
- Need of Data Warehousing
- Why a DWH, Warehousing
- The Basic Concept of Data Warehousing
- Classical SDLC and DWH SDLC, CLDS, Online Transaction Processing
- Types of Data Warehouses: Financial, Telecommunication, Insurance, Human Resource
- Normalization: Anomalies, 1NF, 2NF, INSERT, UPDATE, DELETE
- De-Normalization: Balance between Normalization and De-Normalization
- DeNormalization Techniques: Splitting Tables, Horizontal splitting, Vertical Splitting, Pre-Joining Tables, Adding Redundant Columns, Derived Attributes
- Issues of De-Normalization: Storage, Performance, Maintenance, Ease-of-use
- Online Analytical Processing OLAP: DWH and OLAP, OLTP
- OLAP Implementations: MOLAP, ROLAP, HOLAP, DOLAP
- ROLAP: Relational Database, ROLAP cube, Issues
- Dimensional Modeling DM: ER modeling, The Paradox, ER vs. DM,
- Process of Dimensional Modeling: Four Step: Choose Business Process, Grain, Facts, Dimensions
- Issues of Dimensional Modeling: Additive vs Non-Additive facts, Classification of Aggregation Functions
- Extract Transform Load ETL: ETL Cycle, Processing, Data Extraction, Data Transformation
- Issues of ETL: Diversity in source systems and platforms
- Issues of ETL: legacy data, Web scrapping, data quality, ETL vs ELT
- ETL Detail: Data Cleansing: data scrubbing, Dirty Data, Lexical Errors, Irregularities, Integrity Constraint Violation, Duplication
- Data Duplication Elimination and BSN Method: Record linkage, Merge, purge, Entity reconciliation, List washing and data cleansing
- Introduction to Data Quality Management: Intrinsic, Realistic, Orr’s Laws of Data Quality, TQM
- DQM: Quantifying Data Quality: Free-of-error, Completeness, Consistency, Ratios
- Total DQM: TDQM in a DWH, Data Quality Management Process
- Need for Speed: Parallelism: Scalability, Terminology, Parallelization OLTP Vs DSS
- Need for Speed: Hardware Techniques: Data Parallelism Concept
- Conventional Indexing Techniques: Concept, Goals, Dense Index, Sparse Index
- Special Indexing Techniques: Inverted, Bit map, Cluster, Join indexes
- Join Techniques: Nested loop, Sort Merge, Hash based join
- Data mining (DM): Knowledge Discovery in Databases KDD
- Data Mining: CLASSIFICATION, ESTIMATION, PREDICTION, CLUSTERING,
- Data Structures, types of Data Mining, Min-Max Distance, One-way, K-Means Clustering
- DWH Lifecycle: Data-Driven, Goal-Driven, User-Driven Methodologies
- DWH Implementation: Goal Driven Approach
- DWH Implementation: Goal Driven Approach
- DWH Life Cycle: Pitfalls, Mistakes, Tips
- Course Project
- Contents of Project Reports
- Case Study: Agri-Data Warehouse
- Web Warehousing: Drawbacks of traditional web sear ches, web search, Web traffic record: Log files
- Web Warehousing: Issues, Time-contiguous Log Entries, Transient Cookies, SSL, session ID Ping-pong, Persistent Cookies
- Data Transfer Service (DTS)
- Lab Data Set: Multi -Campus University
- Extracting Data Using Wizard
- Data Profiling