 |

new
NameComponent("ExactTime", "");
NameComponent[] path = {
nc };
ncRef.rebind(path,
timeServerObjRef);
// Wait for client
requests:
java.lang.Object sync
=
new
java.lang.Object();
synchronized(sync){
sync.wait();
}
}
}
///:~
As
you can see, implementing
the server object is simple;
it's a regular
Java
class that inherits from
the skeleton code generated
by the IDL
compiler.
Things get a bit more
complicated when it comes to
interacting
with
the ORB and other
CORBA services.
Some
CORBA services
This
is a short description of what
the JavaIDL-related code is
doing
(primarily
ignoring the part of the
CORBA code that is
vendor
dependent).
The first line in main( )
starts
up the ORB, and of
course,
this
is because our server object
will need to interact with
it. Right after
the
ORB initialization, a server
object is created. Actually,
the right term
would
be a transient
servant object: an object
that receives requests
from
clients,
and whose lifetime is the
same as the process that
creates it. Once
the
transient servant object is
created, it is registered with
the ORB, which
means
that the ORB knows of
its existence and can
now forward requests
to
it.
Up
to this point, all we have
is timeServerObjRef,
an object reference
that
is known only inside the
current server process. The
next step will be
to
assign a stringified name to
this servant object; clients
will use that
name
to locate the servant
object. We accomplish this
operation using the
Naming
Service. First, we need an
object reference to the
Naming Service;
the
call to resolve_initial_references(
) takes
the stringified
object
reference
of the Naming Service that
is "NameService," in JavaIDL,
and
returns
an object reference. This is
cast to a specific NamingContext
reference
using the narrow(
) method.
We can use now the
naming
services.
986
Thinking
in Java

To
bind the servant object
with a stringified object
reference, we first
create
a NameComponent
object,
initialized with "ExactTime,"
the
name
string we want to bind to
the servant object. Then,
using the
rebind(
) method,
the stringified reference is
bound to the object
reference.
We use rebind(
) to
assign a reference, even if it
already exists,
whereas
bind( )
raises
an exception if the reference
already exists. A
name
is made up in CORBA by a sequence of
NameContexts--that's why
we
use an array to bind the
name to the object
reference.
The
servant object is finally
ready for use by clients. At
this point, the
server
process enters a wait state.
Again, this is because it is a
transient
servant,
so its lifetime is confined to
the server process. JavaIDL
does not
currently
support persistent objects--objects
that survive the execution
of
the
process that creates
them.
Now
that we have an idea of what
the server code is doing,
let's look at the
client
code:
//:
c15:corba:RemoteTimeClient.java
import
remotetime.*;
import
org.omg.CosNaming.*;
import
org.omg.CORBA.*;
public
class RemoteTimeClient {
//
Throw exceptions to console:
public
static void main(String[] args)
throws
Exception {
//
ORB creation and initialization:
ORB
orb = ORB.init(args, null);
//
Get the root naming context:
org.omg.CORBA.Object
objRef =
orb.resolve_initial_references(
"NameService");
NamingContext
ncRef =
NamingContextHelper.narrow(objRef);
//
Get (resolve) the stringified object
//
reference for the time server:
NameComponent
nc =
new
NameComponent("ExactTime", "");
NameComponent[]
path = { nc };
ExactTime
timeObjRef =
Chapter
15: Distributed
Computing
987

ExactTimeHelper.narrow(
ncRef.resolve(path));
//
Make requests to the server object:
String
exactTime = timeObjRef.getTime();
System.out.println(exactTime);
}
}
///:~
The
first few lines do the
same as they do in the
server process: the ORB
is
initialized
and a reference to the
naming service server is
resolved. Next,
we
need an object reference for
the servant object, so we
pass the
stringified
object reference to the
resolve(
) method,
and we cast the
result
into an ExactTime
interface
reference using the
narrow(
)
method.
Finally, we call getTime(
).
Activating
the name service
process
Finally
we have a server and a
client application ready to
interoperate.
You've
seen that both need
the naming service to bind
and resolve
stringified
object references. You must
start the naming service
process
before
running either the server or
the client. In JavaIDL, the
naming
service
is a Java application that
comes with the product
package, but it
can
be different with other
products. The JavaIDL naming
service runs
inside
an instance of the JVM and
listens by default to network
port 900.
Activating
the server and the
client
Now
you are ready to start
your server and client
application (in this
order,
since our server is
transient). If everything is set up
correctly, what
you'll
get is a single output line
on the client console
window, giving you
the
current time. Of course,
this might be not very
exciting by itself,
but
you
should take one thing
into account: even if they
are on the same
physical
machine, the client and
the server application are
running inside
different
virtual machines and they
can communicate via an
underlying
integration
layer, the ORB and
the Naming Service.
This
is a simple example, designed to
work without a network, but
an
ORB
is usually configured for
location transparency. When
the server and
the
client are on different
machines, the ORB can
resolve remote
stringified
references using a component
known as the Implementation
988
Thinking
in Java

Repository.
Although the Implementation
Repository is part of
CORBA,
there
is almost no specification, so it differs
from vendor to
vendor.
As
you can see, there is
much more to CORBA than
what has been
covered
here,
but you should get
the basic idea. If you
want more information
about
CORBA, the place to start is
the OMG Web site, at
www.omg.org.
There
you'll find documentation,
white papers, proceedings,
and
references
to other CORBA sources and
products.
Java
Applets and CORBA
Java
applets can act as CORBA
clients. This way, an applet
can access
remote
information and services
exposed as CORBA objects.
But an
applet
can connect only with
the server from which it
was downloaded, so
all
the CORBA objects the
applet interacts with must
be on that server.
This
is the opposite of what
CORBA tries to do: give
you complete location
transparency.
This
is an issue of network security. If
you're on an intranet, one
solution
is
to loosen the security
restrictions on the browser.
Or, set up a firewall
policy
for connecting with external
servers.
Some
Java ORB products offer
proprietary solutions to this
problem. For
example,
some implement what is
called HTTP Tunneling, while
others
have
their special firewall
features.
This
is too complex a topic to be
covered in an appendix, but it
is
definitely
something you should be
aware of.
CORBA
vs. RMI
You
saw that one of the
main CORBA features is RPC
support, which
allows
your local objects to call
methods in remote objects. Of
course,
there
already is a native Java
feature that does exactly
the same thing:
RMI
(see Chapter 15). While
RMI makes RPC possible
between Java
objects,
CORBA makes RPC possible
between objects implemented in
any
language.
It's a big
difference.
However,
RMI can be used to call
services on remote, non-Java
code. All
you
need is some kind of wrapper
Java object around the
non-Java code
on
the server side. The
wrapper object connects
externally to Java
clients
Chapter
15: Distributed
Computing
989

via
RMI, and internally connects
to the non-Java code using
one of the
techniques
shown above, such as JNI or
J/Direct.
This
approach requires you to
write a kind of integration
layer, which is
exactly
what CORBA does for
you, but then you
don't need a
third-party
ORB.
Enterprise
JavaBeans
Suppose6 you need to develop a
multi-tiered application to view
and
update
records in a database through a
Web interface. You can
write a
database
application using JDBC, a
Web interface using
JSP/servlets, and
a
distributed system using
CORBA/RMI. But what extra
considerations
must
you make when developing a
distributed object system
rather than
just
knowing API's? Here are
the issues:
Performance:
The
distributed objects you
create must perform well,
as
they
could potentially service
many clients at a time.
You'll need to use
optimization
techniques such as caching as
well as pooling resources
like
database
connections. You'll also
have to manage the lifecycle
of your
distributed
objects.
Scalability: The
distributed objects must
also be scalable. Scalability
in
a
distributed application means
that the number of instances
of your
distributed
objects can be increased and
moved onto additional
machines
without
modifying any code.
Security:
A distributed
object must often manage
the authorization of
the
clients that access it.
Ideally, you can add
new users and roles to
it
without
recompilation.
Distributed
Transactions: A distributed
object should be able
to
reference
distributed transactions transparently.
For example, if you
are
working
with two separated
databases, you should be
able to update them
simultaneously
within the same transaction
and roll them both
back if a
certain
criteria is not met.
6
This section
was contributed by Robert
Castaneda, with help from
Dave Bartlett.
990
Thinking
in Java

Reusability:
The
ideal distributed object can
be effortlessly moved
onto
another
vendors' application server. It
would be nice if you could
resell a
distributed
object component without
making special modifications,
or
buy
someone else's component and
use it without having to
recompile or
rewrite
it.
Availability:
If one of
the machines in the system
goes down, clients
should
automatically fail-over to backup
copies of the objects
running on
other
machines.
These
considerations, in addition the
business problem that you
set out to
solve,
can make for a daunting
development project. However,
all the
issues
except
for
your business problem are
redundant--solutions must be
reinvented
for every distributed
business application.
Sun,
along with other leading
distributed object vendors,
realized that
sooner
or later every development
team would be reinventing
these
particular
solutions, so they created
the Enterprise
JavaBeans
specification
(EJB). EJB describes a
server-side component model
that
tackles
all of the considerations
mentioned above using a
standard
approach
that allows developers to
create business components
called
EJBs
that are isolated from
low-level "plumbing" code
and that focus
solely
on providing business logic.
Because EJB's are defined in
a
standard
way, they can vendor
independent.
JavaBeans
vs. EJBs
Because
of the similarity in names,
there is much confusion
about the
relationship
between the JavaBeans
component model and the
Enterprise
JavaBeans
specification. While both
the JavaBeans and
Enterprise
JavaBeans
specifications share the
same objectives in promoting
reuse
and
portability of Java code
between development and
deployment tools
with
the use of standard design
patterns, the motives behind
each
specification
are geared to solve
different problems.
The
standards defined in the
JavaBeans component model
are designed
for
creating reusable components
that are typically used in
IDE
development
tools and are commonly,
although not exclusively,
visual
components.
Chapter
15: Distributed
Computing
991

The
Enterprise JavaBeans specification
defines a component model
for
developing
server side java code.
Because EJBs can potentially
run on
many
different server-side
platforms--including mainframes that do
not
have
visual displays--An EJB
cannot make use of graphical
libraries such
as
AWT or Swing.
The
EJB specification
The
Enterprise JavaBeans specification
describes a server-side
component
model. It defines six roles
that are used to perform
the tasks
in
development and deployment as
well as defining the
components of the
system.
These roles are used in
the development, deployment
and
running
of a distributed system. Vendors,
administrators and
developers
play
the various roles, to allow
the partitioning of technical
and domain
knowledge.
The vendor provides a
technically sound framework
and the
developers
create domain-specific components;
for example, an
"accounting"
component. The same party
can perform one or many
roles.
The
roles defined in the EJB
specification are summarized in
the
following
table:
Role
Responsibility
Enterprise
Bean
The
developer responsible for
creating reusable
Provider
EJB
components. These components
are
packaged
into a special jar file
(ejb-jar file).
Application
Creates
and assembles applications
from a
Assembler
collection
of ejb-jar files. This
includes writing
applications
that utilize the collection
of EJBs
(e.g.,
servlets, JSP, Swing etc.
etc.).
Deployer
Takes
the collection of ejb-jar
files from the
Assembler
and/or Bean Provider and
deploys
them
into a run-time environment:
one or more
EJB
Containers.
EJB
Provides
a run-time environment and
tools that
Container/Server
are
used to deploy, administer,
and run EJB
components.
Provider
System
Manages
the different components and
services
Administrator
so
that they are configured
and they interact
correctly,
as well as ensuring that the
system is
up
and running.
992
Thinking
in Java

EJB
components
EJB
components are elements of
reusable business logic that
adhere to
strict
standards and design
patterns as defined in the
EJB specification.
This
allows the components to be
portable. It also allows
other services--
such
as security, caching and
distributed transactions--to be
performed
on
behalf of the components. An
Enterprise Bean Provider is
responsible
for
developing EJB
components.
EJB
Container & Server
The
EJB
Container is a run-time
environment that contains
and runs EJB
components
and provides a set of
standard services to those
components.
The
EJB Container's responsibilities
are tightly defined by
the
specification
to allow for vendor
neutrality. The EJB
container provides
the
low-level "plumbing" of EJB,
including distributed
transactions,
security,
lifecycle management of beans,
caching, threading and
session
management.
The EJB Container Provider
is responsible for providing
an
EJB
Container.
An
EJB
Server is defined as
an Application Server that
contains and runs
one
or more EJB Containers. The
EJB Server Provider is
responsible for
providing
an EJB Server. You can
generally assume that the
EJB
Container
and EJB Server are
the same.
Java
Naming and Directory Interface
(JNDI)
Java
Naming and Directory
Interface (JNDI) is used in
Enterprise
JavaBeans
as the naming service for
EJB Components on the
network and
other
container services such as
transactions. JNDI maps very
closely to
other
naming and directory
standards such as CORBA
CosNaming and
can
actually be implemeted as a wrapper on
top of it.
Java
Transaction API/Java
Transaction
Service
(JTA/JTS)
JTA/JTS
is used in Enterprise JavaBeans as
the transactional API.
An
Enterprise
Bean Provider can use
the JTS to create
transaction code,
although
the EJB Container commonly
implements transactions in
EJB
Chapter
15: Distributed
Computing
993

on
the EJB components' behalf.
The deployer can define
the transactional
attributes
of an EJB component at deployment
time. The EJB Container
is
responsible
for handling the transaction
whether it is local or
distributed.
The
JTS specification is the
Java mapping to the CORBA
OTS (Object
Transaction
Service)
CORBA
and RMI/IIOP
The
EJB specification defines
interoperability with CORBA
through
compatibility
with CORBA protocols. This
is achieved by mapping
EJB
services
such as JTS and JNDI to
corresponding CORBA services
and the
implementation
of RMI on top of the CORBA
protocol IIOP.
Use
of CORBA and RMI/IIOP in
Enterprise JavaBeans is implemented
in
the
EJB Container and is the
responsibility of the EJB
Container provider.
Use
of CORBA and RMI/IIOP in the
EJB Container is hidden from
the
EJB
Component itself. This means
that the Enterprise Bean
Provider can
write
their EJB Component and
deploy it into any EJB
Container without
any
regard of which communication
protocol is being
used.
The
pieces of an EJB component
An
EJB consists of a number of
pieces, including the Bean
itself, the
implementation
of some interfaces, and an
information file. Everything
is
packaged
together into a special jar
file.
Enterprise
Bean
The
Enterprise Bean is a Java
class that the Enterprise
Bean Provider
develops.
It implements an Enterprise Bean
interface and provides
the
implementation
of the business methods that
the component is to
perform.
The class does not
implement any authorization,
authentication,
multithreading,
or transactional code.
Home
interface
Every
Enterprise Bean that is
created must have an
associated Home
interface.
The Home interface is used
as a factory for your EJB.
Clients
use
the Home interface to find
an instance of your EJB or
create a new
instance
of your EJB.
994
Thinking
in Java

Remote
interface
The
Remote interface is a Java
Interface that reflects the
methods of your
Enterprise
Bean that you wish to
expose to the outside world.
The Remote
interface
plays a similar role to a
CORBA IDL interface.
Deployment
descriptor
The
deployment descriptor is an XML
file that contains
information about
your
EJB. Using XML allows
the deployer to easily
change attributes
about
your EJB. The configurable
attributes defined in the
deployment
descriptor
include:
�
The
Home and Remote interface
names that are required by
your
EJB
�
The
name to publish into JNDI
for your EJBs Home
interface
�
Transactional
attributes for each method
of your EJB
�
Access
Control Lists for
authentication
EJB-Jar
file
The
EJB-Jar file is a normal
java jar file that
contains your EJB,
Home
and
Remote interfaces, as well as
the deployment
descriptor.
EJB
operation
Once
you have an EJB-Jar file
containing the Bean, the
Home and
Remote
interfaces, and the
deployment descriptor, you
can fit all of
the
pieces
together and in the process
understand why the Home
and Remote
interfaces
are needed and how
the EJB Container uses
them.
The
EJB Container implements the
Home and Remote interfaces
that are
in
the EJB-Jar file. As
mentioned earlier, the Home
interface provides
methods
to create and find your
EJB. This means that
the EJB Container
is
responsible for the
lifecycle management of your
EJB. This level of
indirection
allows for optimizations to
occur. For example, 5
clients might
simultaneously
request the creation of an
EJB through a Home
Interface,
and
the EJB Container would
respond by creating only one
EJB and
sharing
it between all 5 clients.
This is achieved through the
Remote
Chapter
15: Distributed
Computing
995

Interface,
which is also implemented by
the EJB Container.
The
implemented
Remote object plays the
role of a proxy object to
the EJB.
All
calls to the EJB are
`proxied' through the EJB
Container via the
Home
and
Remote interfaces. This
indirection is the reason
why the EJB
container
can control security and
transactional behavior.
Types
of EJBs
The
Enterprise JavaBeans specification
defines different types of
EJBs
that
have different characteristics
and behaviors. Two
categories of EJBs
have
been defined in the
specification: Session
Beans and
Entity
Beans,
and
each categoriy has
variations.
Session
Beans
Session
Beans are used to represent
Use-Cases or Workflow on behalf of
a
client.
They represent operations on
persistent data, but not
the persistent
data
itself. There are two
types of Session Beans,
Stateless
and
Stateful.
All
Session Beans must implement
the javax.ejb.SessionBean
interface.
The EJB Container governs
the life of a Session
Bean.
Stateless
Session Beans are
the simplest type of EJB
component to
implement.
They do not maintain any
conversational state with
clients
between
method invocations so they
are easily reusable on the
server side
and
because they can be cached,
they scale well on demand.
When using
Stateless
Session Beans, all state
must be stored outside of
the EJB.
Stateful
Session Beans maintain
state between invocations.
They have
a
one-to-one logical mapping to a
client and can maintain
state within
themselves.
The EJB Container is
responsible for pooling and
caching of
Stateful
Session Beans, which is
achieved through Passivation
and
Activation.
If the EJB Container
crashes, data for all
Stateful Session
Beans
could be lost. Some high-end
EJB Containers provide
recovery for
Stateful
Session Beans.
Entity
Beans
Entity
Beans are components that
represent persistent data
and behavior
of
this data. Entity Beans
can be shared among multiple
clients, the same
way
that data in a database can
be shared. The EJB Container
is
996
Thinking
in Java

responsible
for caching Entity Beans
and for maintaining the
integrity of
the
Entity Beans. The life of an
Entity Bean outlives the
EJB Container, so
if
an EJB Container crashes,
the Entity Bean is still
expected to be
available
when the EJB Container
again becomes
available.
There
are two types of Entity
Beans: those with Container
Managed
persistence
and those with Bean-Managed
persistence.
Container
Managed Persistence (CMP). A CMP
Entity Bean has
its
persistence
implemented on its behalf by
the EJB Container.
Through
attributes
specified in the deployment
descriptor, the EJB
Container will
map
the Entity Bean's attributes
to some persistent store
(usually--but
not
always--a database). CMP
reduces the development time
for the EJB,
as
well as dramatically reducing
the amount of code
required.
Bean
Managed Persistence (BMP). A BMP
Entity Bean has
its
persistence
implemented by the Enterprise
Bean Provider. The
Enterprise
Bean
Provider is responsible for
implementing the logic
required to create
a
new EJB, update some
attributes of the EJBS,
delete an EJB and find
an
EJB
from persistent store. This
usually involves writing
JDBC code to
interact
with a database or other
persistent store. With BMP,
the
developer
is in full control of how
the Entity Bean persistence
is managed.
BMP
also gives flexibility where
a CMP implementation may not
be
available.
For example, if you wanted
to create an EJB that
wrapped some
code
on an existing mainframe system,
you could write your
persistence
using
CORBA.
Developing
an EJB
As
an example, the "Perfect
Time" example from the
previous RMI section
will
be implemented as an EJB component.
The example will be a
simple
Stateless
Session Bean.
As
mentioned earlier, EJB
components consist of at least
one class (the
EJB)
and two interfaces: the
Remote and Home interfaces.
When you
create
a Remote interface for an
EJB , you must follow
these guidelines:
1.
The
remote interface must be
public.
Chapter
15: Distributed
Computing
997

2.
The
remote interface must extend
the interface
javax.ejb.EJBObject.
3.
Each
method in the remote
interface must
declare
java.rmi.RemoteException
in
its throws
clause
in addition to
any
application-specific exceptions.
4.
Any
object passed as an argument or
return value (either
directly or
embedded
within a local object) must
be a valid RMI-IIOP
data
type
(this includes other EJB
objects).
Here
is the simple remote
interface for the
PerfectTime EJB:
//:
c15:ejb:PerfectTime.java
//#
You must install the J2EE Java Enterprise
//#
Edition from java.sun.com and add j2ee.jar
//#
to your CLASSPATH in order to compile
//#
this file. See details at java.sun.com.
//
Remote Interface of PerfectTimeBean
import
java.rmi.*;
import
javax.ejb.*;
public
interface PerfectTime extends EJBObject {
public
long getPerfectTime()
throws
RemoteException;
}
///:~
The
Home interface is the
factory where the component
will be created. It
can
define create
methods,
to create instances of EJBs, or
finder
methods,
which
locate existing EJBs and
are used for Entity
Beans only. When
you
create
a Home interface for an EJB
, you must follow these
guidelines:
1.
The
Home interface must be
public.
2.
The
Home interface must extend
the interface
javax.ejb.EJBHome.
3.
Each
create
method
in the Home interface must
declare
java.rmi.RemoteException
in
its throws
clause
as well as a
javax.ejb.CreateException.
4.
The
return value of a create
method
must be a Remote
Interface.
998
Thinking
in Java

5.
The
return value of a finder
method
(Entity Beans only) must be
a
Remote
Interface or java.util.Enumeration
or
java.util.Collection.
6.
Any
object passed as an argument
(either directly or
embedded
within
a local object) must be a
valid RMI-IIOP data type
(this
includes
other EJB objects)
The
standard naming convention
for Home interfaces is to
take the
Remote
interface name and append
"Home" to the end. Here is
the Home
interface
for the PerfectTime
EJB:
//:
c15:ejb:PerfectTimeHome.java
//
Home Interface of PerfectTimeBean.
import
java.rmi.*;
import
javax.ejb.*;
public
interface PerfectTimeHome extends EJBHome {
public
PerfectTime create()
throws
CreateException, RemoteException;
}
///:~
You
can now implement the
business logic. When you
create your EJB
implementation
class, you must follow
these guidelines, (note that
you
should
consult the EJB
specification for a complete
list of guidelines
when
developing
Enterprise JavaBeans):
1.
The
class must be public.
2.
The
class must implement an EJB
interface (either
javax.ejb.SessionBean
or
javax.ejb.EntityBean).
3.
The
class should define methods
that map directly to the
methods
in
the Remote interface. Note
that the class does
not implement the
Remote
interface; it mirrors the
methods in the Remote
interface
but
does not
throw
java.rmi.RemoteException.
4.
Define
one or more ejbCreate(
) methods
to initialize your
EJB.
5.
The
return value and arguments
of all methods must be valid
RMI-
IIOP
data types.
Chapter
15: Distributed
Computing
999

//:
c15:ejb:PerfectTimeBean.java
//
Simple Stateless Session Bean
//
that returns current system time.
import
java.rmi.*;
import
javax.ejb.*;
public
class PerfectTimeBean
implements
SessionBean {
private
SessionContext sessionContext;
//return
current time
public
long getPerfectTime() {
return
System.currentTimeMillis();
}
//
EJB methods
public
void ejbCreate()
throws
CreateException {}
public
void ejbRemove() {}
public
void ejbActivate() {}
public
void ejbPassivate() {}
public
void
setSessionContext(SessionContext
ctx) {
sessionContext
= ctx;
}
}///:~
Because
this is a simple example,
the EJB methods (ejbCreate(
),
ejbRemove(
),
ejbActivate(
),
ejbPassivate(
) )
are all empty.
These
methods
are invoked by the EJB
Container and are used to
control the
state
of the component. The
setSessionContext(
) method
passes a
javax.ejb.SessionContext
object
which contains information
about the
component's
context, such as the current
transaction and
security
information.
After
we have created the
Enterprise JavaBean, we then
need to create a
deployment
descriptor. The deployment
descriptor is an XML file
that
describes
the EJB component. The
deployment descriptor should
be
stored
in a file called ejb-jar.xml.
//:!
c15:ejb:ejb-jar.xml
<?xml
version="1.0"
encoding="Cp1252"?>
1000
Thinking
in Java

<!DOCTYPE
ejb-jar PUBLIC '-//Sun Microsystems,
Inc.//DTD
Enterprise JavaBeans 1.1//EN'
'http://java.sun.com/j2ee/dtds/ejb-jar_1_1.dtd'>
<ejb-jar>
<description>Example
for Chapter 15</description>
<display-name></display-name>
<small-icon></small-icon>
<large-icon></large-icon>
<enterprise-beans>
<session>
<ejb-name>PerfectTime</ejb-name>
<home>PerfectTimeHome</home>
<remote>PerfectTime</remote>
<ejb-class>PerfectTimeBean</ejb-class>
<session-type>Stateless</session-type>
<transaction-type>Container</transaction-type>
</session>
</enterprise-beans>
<ejb-client-jar></ejb-client-jar>
</ejb-jar>
///:~
You
can see the Component,
the Remote interface and
the Home interface
defined
inside the <session>
tag
of this deployment
descriptor.
Deployment
descriptors may be automatically
generated using EJB
development
tools.
Along
with the standard ejb-jar.xml
deployment
descriptor, the EJB
specification
states that any vendor
specific tags should be
stored in a
separate
file. This is to achieve
high portability between
components and
different
brands of EJB
containers.
The
files must be archived
inside a standard Java
Archive (JAR) file.
The
deployment
descriptors should be placed
inside the /META-INF
sub-
directory
of the Jar file.
Once
the EJB component is defined
in the deployment descriptor,
the
deployer
should then deploy the
EJB component into the
EJB Container.
At
the time of this writing,
the deployment process was
quite "GUI
intensive"
and specific to each
individual EJB Container, so
this overview
Chapter
15: Distributed
Computing
1001

does
not document that process.
Every EJB Container, however
will have
a
documented process for
deploying an EJB.
Because
an EJB component is a distributed
object, the
deployment
process
should also create some
client stubs for calling
the EJB
component.
These classes should be
placed on the classpath of
the client
application.
Because EJB components can
be implemented on top of
RMI-IIOP
(CORBA) or RMI-JRMP, the
stubs generated could
vary
between
EJB Containers; nevertheless
they are generated
classes.
When
a client program wishes to
invoke an EJB, it must look
up the EJB
component
inside JNDI and obtain a
reference to the home
interface of
the
EJB component. The Home
interface is used to create an
instance of
the
EJB.
In
this example the client
program is a simple Java
program, but you
should
remember that it could just
as easily be a servlet, a JSP or
even a
CORBA
or RMI distributed
object.
//:
c15:ejb:PerfectTimeClient.java
//
Client program for PerfectTimeBean
public
class PerfectTimeClient {
public
static void main(String[] args)
throws
Exception {
//
Get a JNDI context using
//
the JNDI Naming service:
javax.naming.Context
context =
new
javax.naming.InitialContext();
//
Look up the home interface in the
//
JNDI Naming service:
Object
ref = context.lookup("perfectTime");
//
Cast the remote object to the home interface:
PerfectTimeHome
home = (PerfectTimeHome)
javax.rmi.PortableRemoteObject.narrow(
ref,
PerfectTimeHome.class);
//
Create a remote object from the home interface:
PerfectTime
pt = home.create();
//
Invoke getPerfectTime()
System.out.println(
"Perfect
Time EJB invoked, time is: " +
1002
Thinking
in Java

pt.getPerfectTime()
);
}
}
///:~
The
sequence of the example is
explained in the comments.
Note the use
of
the narrow(
) method
to perform a kind of casting of
the object before
a
Java cast is performed. This
is very similar to what
happens in CORBA.
Also
note that the Home
object becomes a factory for
PerfectTime
objects.
EJB
summary
The
Enterprise JavaBeans specification is a
dramatic step forward in
the
standardization
and simplification of distributed
object computing. It is a
major
piece of the Java 2
Enterprise Edition (J2EE)
platform and is
receiving
much support from the
distributed object community.
Many
tools
are currently available or
will be available in the
near future to help
accelerate
the development of EJB
components.
This
overview was only a brief
tour of EJBs. For more
information about
the
EJB specification you should
see the official Enterprise
JavaBeans
home
page at java.sun.com/products/ejb/,
where
you can download
the
latest
specification and the J2EE
reference implementation. These
can be
used
to develop and deploy your
own EJB components.
Jini:
distributed services
This
section7 gives an overview of Sun
Microsystems's Jini technology.
It
describes
some Jini nuts and
bolts and shows how
Jini's architecture
helps
to raise the level of
abstraction in distributed systems
programming,
effectively
turning network programming
into object-oriented
programming.
Jini
in context
Traditionally,
operating systems have been
designed with the
assumption
that
a computer will have a
processor, some memory, and
a disk. When
7
This section
was contributed by Bill
Venners (www.artima.com).
Chapter
15: Distributed
Computing
1003

you
boot a computer, the first
thing it does is look for a
disk. If it doesn't
find
a disk, it can't function as a
computer. Increasingly,
however,
computers
are appearing in a different
guise: as embedded devices
that
have
a processor, some memory,
and a network connection--but no
disk.
The
first thing a cell phone
does when you boot it
up, for example, is
look
for
the telephone network. If it
doesn't find the network, it
can't function
as
a cell phone. This trend in
the hardware environment,
from disk-
centric
to network-centric, will affect
how we organize the
software--and
that's
where Jini comes
in.
Jini
is an attempt to rethink computer
architecture, given the
rising
importance
of the network and the
proliferation of processors in
devices
that
have no disk drive. These
devices, which will come
from many
different
vendors, will need to
interact over a network. The
network itself
will
be very dynamic--devices and
services will be added and
removed
regularly.
Jini provides mechanisms to
enable smooth adding,
removal,
and
finding of devices and
services on the network. In
addition, Jini
provides
a programming model that
makes it easier for
programmers to
get
their devices talking to
each other.
Building
on top of Java, object
serialization, and RMI
(which together
enable
objects to move around the
network from virtual machine
to
virtual
machine) Jini attempts to
extend the benefits of
object-oriented
programming
to the network. Instead of
requiring device vendors to
agree
on
the network protocols
through which their devices
can interact, Jini
enables
the devices to talk to each
other through interfaces to
objects.
What
is Jini?
Jini
is a set of APIs and network
protocols that can help
you build and
deploy
distributed systems that are
organized as federations
of services. A
service
can
be anything that sits on the
network and is ready to
perform a
useful
function. Hardware devices,
software, communications
channels--
even
human users themselves--can be
services. A Jini-enabled disk
drive,
for
example, could offer a
"storage" service. A Jini-enabled
printer could
offer
a "printing" service. A federation of
services, then, is a set of
services,
currently
available on the network,
that a client (meaning a
program,
service,
or user) can bring together
to help it accomplish some
goal.
1004
Thinking
in Java

To
perform a task, a client
enlists the help of
services. For example,
a
client
program might upload
pictures from the image
storage service in a
digital
camera, download the
pictures to a persistent storage
service
offered
by a disk drive, and send a
page of thumbnail-sized versions of
the
images
to the printing service of a
color printer. In this
example, the client
program
builds a distributed system
consisting of itself, the
image storage
service,
the persistent storage
service, and the
color-printing service.
The
client
and services of this
distributed system work
together to perform
the
task:
to offload and store images
from a digital camera and
print a page of
thumbnails.
The
idea behind the word
federation
is
that the Jini view of
the network
doesn't
involve a central controlling
authority. Because no one
service is
in
charge, the set of all
services available on the
network form a
federation--a
group composed of equal
peers. Instead of a
central
authority,
Jini's run-time infrastructure
merely provides a way for
clients
and
services to find each other
(via a lookup service, which
stores a
directory
of currently available services).
After services locate each
other,
they
are on their own. The
client and its enlisted
services perform
their
task
independently of the Jini
run-time infrastructure. If the
Jini lookup
service
crashes, any distributed
systems brought together via
the lookup
service
before it crashed can
continue their work. Jini
even includes a
network
protocol that clients can
use to find services in the
absence of a
lookup
service.
How
Jini works
Jini
defines a run-time
infrastructure that
resides on the network
and
provides
mechanisms that enable you
to add, remove, locate, and
access
services.
The run-time infrastructure
resides in three places: in
lookup
services
that sit on the network, in
the service providers (such
as Jini-
enabled
devices), and in clients.
Lookup
services are
the central
organizing
mechanism for Jini-based
systems. When new services
become
available
on the network, they
register themselves with a
lookup service.
When
clients wish to locate a
service to assist with some
task, they consult
a
lookup service.
The
run-time infrastructure uses
one network-level protocol,
called
discovery,
and two object-level
protocols, called join
and
lookup.
Chapter
15: Distributed
Computing
1005

Discovery
enables clients and services
to locate lookup services.
Join
enables
a service to register itself in a
lookup service. Lookup
enables a
client
to query for services that
can help accomplish its
goals.
The
discovery process
Discovery
works like this: Imagine
you have a Jini-enabled disk
drive that
offers
a persistent storage service. As
soon as you connect the
drive to the
network,
it broadcasts a presence
announcement by dropping a
multicast
packet
onto a well-known port.
Included in the presence
announcement is
an
IP address and port number
where the disk drive
can be contacted by a
lookup
service.
Lookup
services monitor the
well-known port for presence
announcement
packets.
When a lookup service
receives a presence announcement,
it
opens
and inspects the packet.
The packet contains
information that
enables
the lookup service to
determine whether or not it
should contact
the
sender of the packet. If so,
it contacts the sender
directly by making a
TCP
connection to the IP address
and port number extracted
from the
packet.
Using RMI, the lookup
service sends an object,
called a service
registrar,
across the network to the
originator of the packet.
The purpose
of
the service registrar object
is to facilitate further communication
with
the
lookup service. By invoking
methods on this object, the
sender of the
announcement
packet can perform join
and lookup on the lookup
service.
In
the case of the disk
drive, the lookup service
would make a TCP
connection
to the disk drive and
would send it a service
registrar object,
through
which the disk drive
would then register its
persistent storage
service
via the join
process.
The
join process
Once
a service provider has a
service registrar object,
the end product of
discovery,
it is ready to do a join--to become
part of the federation
of
services
that are registered in the
lookup service. To do a join,
the service
provider
invokes the register(
) method
on the service registrar
object,
passing
as a parameter an object called a
service item, a bundle of
objects
that
describe the service. The
register(
) method
sends a copy of the
service
item up to the lookup
service, where the service
item is stored.
1006
Thinking
in Java

Once
this has completed, the
service provider has
finished the join
process:
its service has become
registered in the lookup
service.
The
service item is a container
for several objects,
including an object
called
a service
object, which
clients can use to interact
with the service.
The
service item can also
include any number of
attributes,
which can be
any
object. Some potential
attributes are icons,
classes that provide
GUIs
for
the service, and objects
that give more information
about the service.
Service
objects usually implement
one or more interfaces
through which
clients
interact with the service.
For example, a lookup
service is a Jini
service,
and its service object is
the service registrar. The
register(
)
method
invoked by service providers
during join is declared in
the
ServiceRegistrar
interface
(a member of the net.jini.core.lookup
package),
which all service registrar
objects implement. Clients
and
service
providers talk to the lookup
service through the service
registrar
object
by invoking methods declared in
the ServiceRegistrar
interface.
Likewise,
a disk drive would provide a
service object that
implemented
some
well-known storage service
interface. Clients would
look up and
interact
with the disk drive by
this storage service
interface.
The
lookup process
Once
a service has registered
with a lookup service via
the join process,
that
service is available for use
by clients who query that
lookup service.
To
build a distributed system of
services that will work
together to
perform
some task, a client must
locate and enlist the
help of the
individual
services. To find a service,
clients query lookup
services via a
process
called lookup.
To
perform a lookup, a client
invokes the lookup(
) method on a service
registrar
object. (A client, like a
service provider, gets a
service registrar
through
the previously-described process of
discovery.) The client
passes
as
an argument to lookup(
) a
service
template, an object
that serves as
search
criteria for the query.
The service template can
include a reference
to
an array of Class
objects.
These Class
objects
indicate to the
lookup
service
the Java type (or
types) of the service object
desired by the
client.
The
service template can also
include a service
ID,
which uniquely
identifies
a service, and attributes,
which must exactly match
the
attributes
uploaded by the service
provider in the service
item. The service
Chapter
15: Distributed
Computing
1007

template
can also contain wildcards
for any of these fields. A
wildcard in
the
service ID field, for
example, will match any
service ID. The
lookup(
) method
sends the service template
to the lookup
service,
which
performs the query and
sends back zero to any
matching service
objects.
The client gets a reference
to the matching service
objects as the
return
value of the lookup(
) method.
In
the general case, a client
looks up a service by Java
type, usually an
interface.
For example, if a client
needed to use a printer, it
would
compose
a service template that
included a Class
object
for a well-known
interface
to printer services. All
printer services would
implement this
well-known
interface. The lookup
service would return a
service object (or
objects)
that implemented this
interface. Attributes can be
included in the
service
template to narrow the
number of matches for such a
type-based
search.
The client would use
the printer service by
invoking methods from
the
well-known printer service
interface on the service
object.
Separation
of interface and
implementation
Jini's
architecture brings object-oriented
programming to the network
by
enabling
network services to take
advantage of one of the
fundamentals of
objects:
the separation of interface
and implementation. For
example, a
service
object can grant clients
access to the service in
many ways. The
object
can actually represent the
entire service, which is
downloaded to
the
client during lookup and
then executed locally.
Alternatively, the
service
object can serve merely as a
proxy to a remote server.
Then when
the
client invokes methods on
the service object, it sends
the requests
across
the network to the server,
which does the real
work. A third option
is
for the local service
object and a remote server
to each do part of
the
work.
One
important consequence of Jini's
architecture is that the
network
protocol
used to communicate between a
proxy service object and
a
remote
server does not need to be
known to the client. As
illustrated in
the
figure below, the network
protocol is part of the
service's
implementation.
This protocol is a private
matter decided upon by
the
developer
of the service. The client
can communicate with the
service via
1008
Thinking
in Java
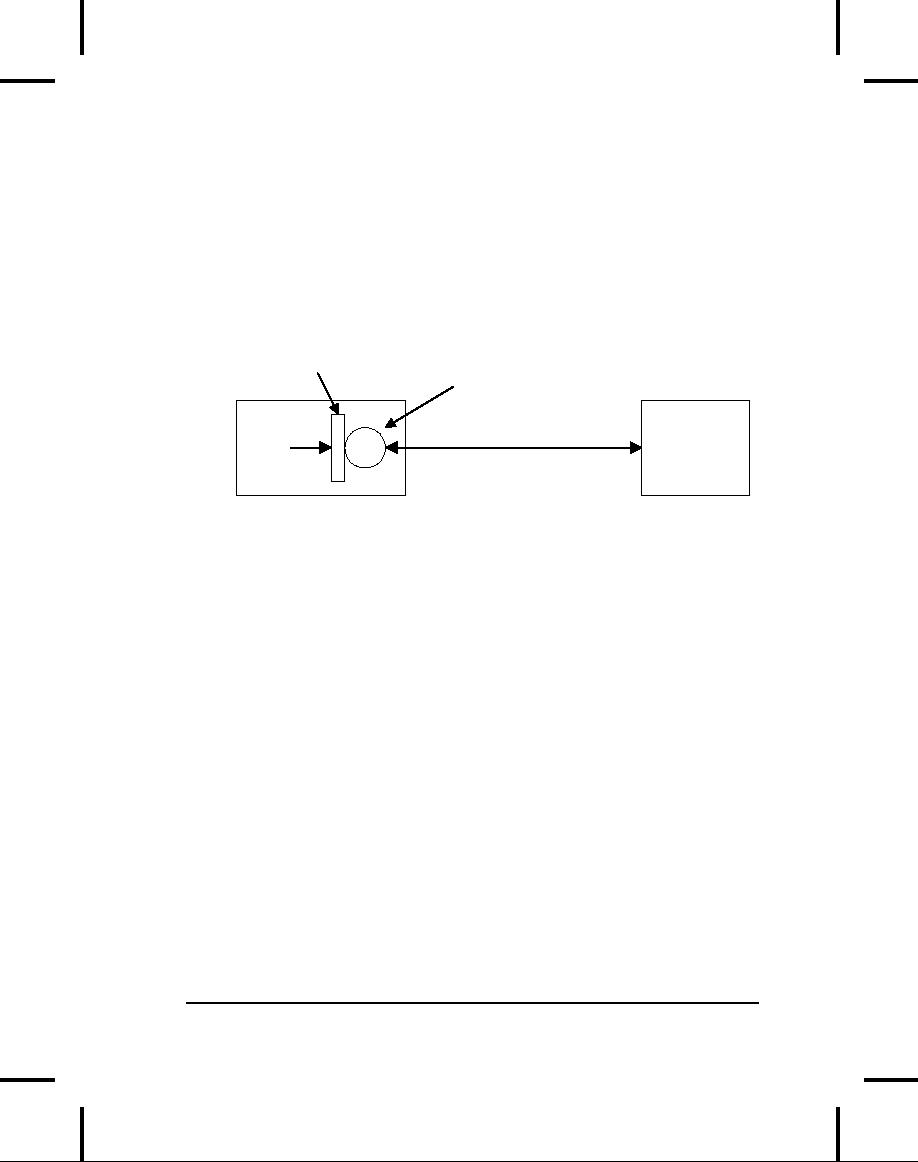
this
private protocol because the
service injects some of its
own code (the
service
object) into the client's
address space. The injected
service object
could
communicate with the service
via RMI, CORBA, DCOM,
some
home-brewed
protocol built on top of
sockets and streams, or
anything
else.
The client simply doesn't
need to care about network
protocols,
because
it can talk to the
well-known interface that
the service object
implements.
The service object takes
care of any necessary
communication
on the network.
"Well-known"
interface
Service
object
Private
network
protocol
Client
Service
The
client talks to the service through a
well-known interface
Different
implementations of the same
service interface can
use
completely
different approaches and
network protocols. A service
can use
specialized
hardware to fulfill client
requests, or it can do all
its work in
software.
In fact, the implementation
approach taken by a single
service
can
evolve over time. The
client can be sure it has a
service object that
understands
the current implementation of
the service, because the
client
receives
the service object (by
way of the lookup service)
from the service
provider
itself. To the client, a
service looks like the
well-known interface,
regardless
of how the service is
implemented.
Abstracting
distributed systems
Jini
attempts to raise the level
of abstraction for distributed
systems
programming,
from the network protocol
level to the object
interface
level.
In the emerging proliferation of
embedded devices connected
to
networks,
many pieces of a distributed
system may come from
different
vendors.
Jini makes it unnecessary
for vendors of devices to
agree on
network
level protocols that allow
their devices to interact.
Instead,
vendors
must agree on Java
interfaces through which
their devices can
Chapter
15: Distributed
Computing
1009

interact.
The processes of discovery,
join, and lookup, provided
by the Jini
run-time
infrastructure, enable devices to
locate each other on
the
network.
Once they locate each
other, devices can
communicate with each
other
through Java
interfaces.
Summary
Along
with Jini for local
device networks, this
chapter has
introduced
some,
but not all, of the
components that Sun refers
to as J2EE: the Java
2
Enterprise Edition. The
goal of J2EE is to build a
set of tools that
allows
the
Java developer to build
server-based applications much
more quickly,
and
in a platform-independent way. It's
not only difficult and
time-
consuming
to build such applications,
but it's especially hard to
build
them
so that they can be easily
ported to other platforms,
and also to keep
the
business logic separated
from the underlying details
of the
implementation.
J2EE provides a framework to
assist in creating
server-
based
applications; these applications
are in demand now, and
that
demand
appears to be increasing.
Exercises
Solutions
to selected exercises can be
found in the electronic
document The
Thinking in Java
Annotated
Solution Guide, available
for a small fee from
.
1.
Compile
and run the JabberServer
and
JabberClient
programs
in this chapter. Now edit
the files to remove all of
the
buffering
for the input and
output, then compile and
run them
again
to observe the
results.
2.
Create
a server that asks for a
password, then opens a file
and
sends
the file over the
network connection. Create a
client that
connects
to this server, gives the
appropriate password,
then
captures
and saves the file.
Test the pair of programs on
your
machine
using the localhost
(the
local loopback IP
address
127.0.0.1
produced
by calling
InetAddress.getByName(null)).
3.
Modify
the server in Exercise 2 so
that it uses multithreading
to
handle
multiple clients.
1010
Thinking
in Java

4.
Modify
JabberClient.java
so
that output flushing doesn't
occur
and
observe the effect.
5.
Modify
MultiJabberServer
so
that it uses thread
pooling.
Instead
of throwing away a thread
each time a client
disconnects,
the
thread should put itself
into an "available pool" of
threads.
When
a new client wants to
connect, the server will
look in the
available
pool for a thread to handle
the request, and if one
isn't
available,
make a new one. This
way the number of
threads
necessary
will naturally grow to the
required quantity. The value
of
thread
pooling is that it doesn't
require the overhead of
creating
and
destroying a new thread for
each new client.
6.
Starting
with ShowHTML.java,
create an applet that is
a
password-protected
gateway to a particular portion of
your Web
site.
7.
Modify
CIDCreateTables.java
so
that it reads the SQL
strings
from
a text file instead of
CIDSQL.
8.
Configure
your system so that you
can successfully
execute
CIDCreateTables.java
and
LoadDB.java.
9.
Modify
ServletsRule.java
by
overriding the destroy(
) method
to
save the value of i to
a file, and and the
init( )
method
to
restore
the value. Demonstrate that
it works by rebooting
the
servlet
container. If you do not
have an existing servlet
container,
you
will need to download,
install, and run Tomcat
from
jakarta.apache.org
in
order to run
servlets.
10.
Create
a servlet that adds a cookie
to the response object,
thereby
storing
it on the client's site. Add
code to the servlet that
retrieves
and
displays the cookie. If you
do not have an existing
servlet
container,
you will need to download,
install, and run
Tomcat
from
jakarta.apache.org
in
order to run
servlets.
11.
Create
a servlet that uses a
Session
object
to store session
information
of your choosing. In the
same servlet, retrieve
and
display
that session information. If
you do not have an
existing
Chapter
15: Distributed
Computing
1011

servlet
container, you will need to
download, install, and
run
Tomcat
from jakarta.apache.org
in
order to run
servlets.
12.
Create
a servlet that changes the
inactive interval of a session to
5
seconds
by calling getMaxInactiveInterval(
).
Test to see that
the
session does indeed expire
after 5 seconds. If you do
not have
an
existing servlet container,
you will need to download,
install,
and
run Tomcat from jakarta.apache.org
in
order to run
servlets.
13.
Create
a JSP page that prints a
line of text using the
<H1> tag. Set
the
color of this text randomly,
using Java code embedded in
the
JSP
page. If you do not have an
existing JSP container, you
will
need
to download, install, and
run Tomcat from
jakarta.apache.org
in
order to run JSPs.
14.
Modify
the maximum age value in
Cookies.jsp
and
observe the
behavior
under two different
browsers. Also note the
difference
between
just re-visiting the page,
and shutting down
and
restarting
the browser. If you do not
have an existing JSP
container,
you will need to download,
install, and run
Tomcat
from
jakarta.apache.org
in
order to run JSPs.
15.
Create
a JSP with a field that
allows the user to enter
the session
expiration
time and and a second
field that holds data
that is
stored
in the session. The submit
button refreshes the page
and
fetches
the current expiration time
and session data and
puts them
in
as default values of the
aforementioned fields. If you do
not
have
an existing JSP container,
you will need to download,
install,
and
run Tomcat from jakarta.apache.org
in
order to run JSPs.
16.
(More
challenging) Take the
VLookup.java
program
and modify
it
so that when you click on
the resulting name it
automatically
takes
that name and copies it to
the clipboard (so you
can simply
paste
it into your email). You'll
need to look back at Chapter
13 to
remember
how to use the clipboard in
JFC.
1012
Thinking
in Java

A:
Passing &
Returning
Objects
By
now you should be reasonably
comfortable with the
idea
that when you're "passing"
an object, you're
actually
passing
a reference.
In
many programming languages
you can use that
language's "regular"
way
to pass objects around, and
most of the time everything
works fine.
But
it always seems that there
comes a point at which you
must do
something
irregular and suddenly
things get a bit more
complicated (or in
the
case of C++, quite
complicated). Java is no exception,
and it's
important
that you understand exactly
what's happening as you
pass
objects
around and manipulate them.
This appendix will provide
that
insight.
Another
way to pose the question of
this appendix, if you're
coming from
a
programming language so equipped, is
"Does Java have
pointers?"
Some
have claimed that pointers
are hard and dangerous
and therefore
bad,
and since Java is all
goodness and light and
will lift your
earthly
programming
burdens, it cannot possibly
contain such things.
However,
it's
more accurate to say that
Java has pointers; indeed,
every object
identifier
in Java (except for
primitives) is one of these
pointers, but their
use
is restricted and guarded
not only by the compiler
but by the run-time
system.
Or to put it another way,
Java has pointers, but no
pointer
arithmetic.
These are what I've
been calling "references,"
and you can
think
of them as "safety pointers,"
not unlike the safety
scissors of
elementary
school--they aren't sharp, so
you cannot hurt yourself
without
great
effort, but they can
sometimes be slow and
tedious.
1013

Passing
references around
When
you pass a reference into a
method, you're still
pointing to the same
object.
A simple experiment demonstrates
this:
//:
appendixa:PassReferences.java
//
Passing references around.
public
class PassReferences {
static
void f(PassReferences h) {
System.out.println("h
inside f(): " + h);
}
public
static void main(String[] args) {
PassReferences
p = new PassReferences();
System.out.println("p
inside main(): " + p);
f(p);
}
}
///:~
The
method toString(
) is
automatically invoked in the
print statements,
and
PassReferences
inherits
directly from Object
with
no redefinition
of
toString(
).
Thus, Object's
version of toString(
) is
used, which
prints
out the class of the
object followed by the
address where that
object
is
located (not the reference,
but the actual object
storage). The output
looks
like this:
p
inside main(): PassReferences@1653748
h
inside f(): PassReferences@1653748
You
can see that both
p and
h refer
to the same object. This is
far more
efficient
than duplicating a new
PassReferences
object
just so that you
can
send an argument to a method.
But it brings up an important
issue.
Aliasing
Aliasing
means that more than
one reference is tied to the
same object, as
in
the above example. The
problem with aliasing occurs
when someone
writes
to
that object. If the owners
of the other references
aren't expecting
that
object to change, they'll be
surprised. This can be
demonstrated with
a
simple example:
1014
Thinking
in Java
//:
appendixa:Alias1.java
//
Aliasing two references to one object.
public
class Alias1 {
int
i;
Alias1(int
ii) { i = ii; }
public
static void main(String[] args) {
Alias1
x = new Alias1(7);
Alias1
y = x; // Assign the reference
System.out.println("x:
" + x.i);
System.out.println("y:
" + y.i);
System.out.println("Incrementing
x");
x.i++;
System.out.println("x:
" + x.i);
System.out.println("y:
" + y.i);
}
}
///:~
In
the line:
Alias1
y = x; // Assign the reference
a
new Alias1
reference
is created, but instead of
being assigned to a
fresh
object
created with new,
it's assigned to an existing
reference. So the
contents
of reference x,
which is the address of the
object x
is
pointing to,
is
assigned to y,
and thus both x and
y are
attached to the same object.
So
when
x's
i is
incremented in the
statement:
x.i++;
y's
i will
be affected as well. This
can be seen in the
output:
x:
7
y:
7
Incrementing
x
x:
8
y:
8
One
good solution in this case
is to simply not do it:
don't consciously
alias
more than one reference to
an object at the same scope.
Your code
will
be much easier to understand
and debug. However, when
you're
passing
a reference in as an argument--which is
the way Java is
supposed
to
work--you automatically alias
because the local reference
that's created
Appendix
A: Passing & Returning
Objects
1015

can
modify the "outside object"
(the object that was
created outside the
scope
of the method). Here's an
example:
//:
appendixa:Alias2.java
//
Method calls implicitly alias their
//
arguments.
public
class Alias2 {
int
i;
Alias2(int
ii) { i = ii; }
static
void f(Alias2 reference) {
reference.i++;
}
public
static void main(String[] args) {
Alias2
x = new Alias2(7);
System.out.println("x:
" + x.i);
System.out.println("Calling
f(x)");
f(x);
System.out.println("x:
" + x.i);
}
}
///:~
The
output is:
x:
7
Calling
f(x)
x:
8
The
method is changing its
argument, the outside
object. When this
kind
of
situation arises, you must
decide whether it makes
sense, whether the
user
expects it, and whether
it's going to cause
problems.
In
general, you call a method
in order to produce a return
value and/or a
change
of state in the object
that
the method is called for.
(A method is
how
you "send a message" to that
object.) It's much less
common to call a
method
in order to manipulate its
arguments; this is referred to
as
"calling
a method for its side
effects." Thus,
when you create a
method
that
modifies its arguments the
user must be clearly
instructed and
warned
about the use of that
method and its potential
surprises. Because
of
the confusion and pitfalls,
it's much better to avoid
changing the
argument.
1016
Thinking
in Java

If
you need to modify an
argument during a method
call and you
don't
intend
to modify the outside
argument, then you should
protect that
argument
by making a copy inside your
method. That's the subject
of
much
of this appendix.
Making
local copies
To
review: All argument passing
in Java is performed by
passing
references.
That is, when you
pass "an object," you're
really passing only a
reference
to an object that lives
outside the method, so if
you perform any
modifications
with that reference, you
modify the outside object.
In
addition:
♦
Aliasing
happens automatically during
argument passing.
♦
There
are no local objects, only
local references.
♦
References
have scopes, objects do
not.
♦
Object
lifetime is never an issue in
Java.
♦
There is no
language support (e.g.,
"const") to prevent objects
from being
modified
(that is, to prevent the
negative effects of
aliasing).
If
you're only reading
information from an object
and not modifying
it,
passing
a reference is the most
efficient form of argument
passing. This is
nice;
the default way of doing
things is also the most
efficient. However,
sometimes
it's necessary to be able to
treat the object as if it
were "local"
so
that changes you make
affect only a local copy
and do not modify
the
outside
object. Many programming
languages support the
ability to
automatically
make a local copy of the
outside object, inside the
method1.
Java
does not, but it allows
you to produce this
effect.
1
In C, which generally
handles small bits of data, the default is
pass-by-value. C++ had to
follow
this form, but with objects
pass-by-value isn't usually the
most efficient way.
In
addition,
coding classes to support
pass-by-value in C++ is a big
headache.
Appendix
A: Passing & Returning
Objects
1017

Pass
by value
This
brings up the terminology
issue, which always seems
good for an
argument.
The term is "pass by value,"
and the meaning depends on
how
you
perceive the operation of
the program. The general
meaning is that
you
get a local copy of whatever
you're passing, but the
real question is
how
you think about what
you're passing. When it
comes to the meaning
of
"pass by value," there are
two fairly distinct
camps:
1.
Java
passes everything by value.
When you're passing
primitives
into
a method, you get a distinct
copy of the primitive. When
you're
passing
a reference into a method,
you get a copy of the
reference.
Ergo,
everything is pass-by-value. Of course,
the assumption is
that
you're
always thinking (and caring)
that references are
being
passed,
but it seems like the
Java design has gone a
long way
toward
allowing you to ignore (most
of the time) that
you're
working
with a reference. That is,
it seems to allow you to
think of
the
reference as "the object,"
since it implicitly dereferences
it
whenever
you make a method
call.
2.
Java
passes primitives by value
(no argument there), but
objects
are
passed by reference. This is
the world view that
the reference is
an
alias for the object, so
you don't
think
about passing
references,
but
instead say "I'm passing
the object." Since you
don't get a local
copy
of the object when you
pass it into a method,
objects are
clearly
not passed by value. There
appears to be some support
for
this
view within Sun, since
one of the "reserved but
not
implemented"
keywords was byvalue.
(There's no knowing,
however,
whether that keyword will
ever see the light of
day.)
Having
given both camps a good
airing, and after saying
"It depends on
how
you think of a reference," I
will attempt to sidestep the
issue. In the
end,
it isn't that
important--what
is important is that you
understand that
passing
a reference allows the
caller's object to be changed
unexpectedly.
Cloning
objects
The
most likely reason for
making a local copy of an
object is if you're
going
to modify that object and
you don't want to modify
the caller's
object.
If you decide that you
want to make a local copy,
you simply use
1018
Thinking
in Java

the
clone( )
method
to perform the operation.
This is a method
that's
defined
as protected
in
the base class Object,
and which you
must
override
as public
in
any derived classes that
you want to clone.
For
example,
the standard library class
ArrayList
overrides
clone(
),
so we
can
call clone(
) for
ArrayList:
//:
appendixa:Cloning.java
//
The clone() operation works for only a few
//
items in the standard Java library.
import
java.util.*;
class
Int {
private
int i;
public
Int(int ii) { i = ii; }
public
void increment() { i++; }
public
String toString() {
return
Integer.toString(i);
}
}
public
class Cloning {
public
static void main(String[] args) {
ArrayList
v = new ArrayList();
for(int
i = 0; i < 10; i++ )
v.add(new
Int(i));
System.out.println("v:
" + v);
ArrayList
v2 = (ArrayList)v.clone();
//
Increment all v2's elements:
for(Iterator
e = v2.iterator();
e.hasNext();
)
((Int)e.next()).increment();
//
See if it changed v's elements:
System.out.println("v:
" + v);
}
}
///:~
The
clone( )
method
produces an Object,
which must then be recast
to
the
proper type. This example
shows how ArrayList's
clone( )
method
does
not automatically
try to clone each of the
objects that the ArrayList
contains--the
old ArrayList
and
the cloned ArrayList
are
aliased to the
same
objects. This is often
called a shallow
copy, since
it's copying only
Appendix
A: Passing & Returning
Objects
1019

the
"surface" portion of an object.
The actual object consists
of this
"surface,"
plus all the objects
that the references are
pointing to, plus
all
the
objects those
objects
are pointing to, etc.
This is often referred to
as
the
"web of objects." Copying
the entire mess is called a
deep
copy.
You
can see the effect of
the shallow copy in the
output, where the
actions
performed
on v2
affect
v:
v:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
v:
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Not
trying to clone(
) the
objects contained in the
ArrayList
is
probably
a
fair assumption because
there's no guarantee that
those objects are
cloneable2.
Adding
cloneability to a class
Even
though the clone method is
defined in the
base-of-all-classes
Object,
cloning is not
automatically
available in every
class3.
This would
seem
to be counterintuitive to the idea
that base-class methods are
always
available
in derived classes. Cloning in
Java goes against this
idea; if you
want
it to exist for a class, you
must specifically add code
to make cloning
work.
2
This is not
the dictionary spelling of the word, but
it's what is used in the
Java library, so
I've
used it here, too, in some
hopes of reducing confusion.
3
You can apparently create a
simple counter-example to this statement,
like this:
public
class Cloneit implements
Cloneable {
public
static void main (String[]
args)
throws
CloneNotSupportedException {
Cloneit
a = new Cloneit();
Cloneit
b = (Cloneit)a.clone();
}
}
However,
this only works because
main( )
is
a method of Cloneit
and
thus has
permission
to call the protected
base-class
method clone(
).
If you call it from a
different
class, it won't
compile.
1020
Thinking
in Java

Using
a trick with protected
To
prevent default cloneability in
every class you create,
the clone(
)
method
is protected
in
the base class Object.
Not only does this
mean
that
it's not available by
default to the client
programmer who is
simply
using
the class (not subclassing
it), but it also means
that you cannot
call
clone(
) via
a reference to the base
class. (Although that might
seem to be
useful
in some situations, such as to
polymorphically clone a bunch
of
Objects.)
It is in effect a way to give
you, at compile-time,
the
information
that your object is not
cloneable--and oddly enough
most
classes
in the standard Java library
are not cloneable. Thus, if
you say:
Integer
x = new Integer(1);
x
= x.clone();
You
will get, at compile-time, an
error message that says
clone( )
is
not
accessible
(since Integer
doesn't
override it and it defaults to
the
protected
version).
If,
however, you're in a class
derived from Object
(as
all classes are),
then
you
have permission to call
Object.clone(
) because
it's protected
and
you're
an inheritor. The base class
clone( )
has
useful functionality--it
performs
the actual bitwise
duplication of
the derived-class object,
thus
acting
as the common cloning
operation. However, you then
need to make
your
clone
operation public
for
it to be accessible. So, two
key issues
when
you clone are:
�
Virtually
always call super.clone(
)
�
Make
your clone public
You'll
probably want to override
clone( )
in
any further derived
classes,
otherwise
your (now public)
clone( )
will
be used, and that might
not do
the
right thing (although, since
Object.clone(
) makes
a copy of the
actual
object, it might). The
protected
trick
works only once--the
first
time
you inherit from a class
that has no cloneability and
you want to
make
a class that's cloneable. In
any classes inherited from
your class the
clone(
) method
is available since it's not
possible in Java to reduce
the
access
of a method during derivation.
That is, once a class is
cloneable,
everything
derived from it is cloneable
unless you use
provided
mechanisms
(described later) to "turn
off" cloning.
Appendix
A: Passing & Returning
Objects
1021

Implementing
the Cloneable
interface
There's
one more thing you
need to do to complete the
cloneability of an
object:
implement the Cloneable
interface. This
interface
is
a bit
strange,
because it's empty!
interface
Cloneable {}
The
reason for implementing this
empty interface
is
obviously not
because
you are going to upcast to
Cloneable
and
call one of its
methods.
The
use of interface
here
is considered by some to be a "hack"
because
it's
using a feature for
something other than its
original intent.
Implementing
the Cloneable
interface acts as a
kind of a flag, wired
into
the type of the
class.
There
are two reasons for
the existence of the
Cloneable
interface.
First,
you might have an upcast
reference to a base type and
not know
whether
it's possible to clone that
object. In this case, you
can use the
instanceof
keyword
(described in Chapter 12) to
find out whether
the
reference
is connected to an object that
can be cloned:
if(myReference
instanceof Cloneable) // ...
The
second reason is that mixed
into this design for
cloneability was the
thought
that maybe you didn't
want all types of objects to
be cloneable. So
Object.clone(
) verifies
that a class implements the
Cloneable
interface.
If not, it throws a CloneNotSupportedException
exception.
So
in general, you're forced to
implement
Cloneable as part of
support
for
cloning.
Successful
cloning
Once
you understand the details
of implementing the clone(
) method,
you're
able to create classes that
can be easily duplicated to
provide a local
copy:
//:
appendixa:LocalCopy.java
//
Creating local copies with clone().
import
java.util.*;
class
MyObject implements Cloneable {
int
i;
1022
Thinking
in Java

MyObject(int
ii) { i = ii; }
public
Object clone() {
Object
o = null;
try
{
o
= super.clone();
}
catch(CloneNotSupportedException e) {
System.err.println("MyObject
can't clone");
}
return
o;
}
public
String toString() {
return
Integer.toString(i);
}
}
public
class LocalCopy {
static
MyObject g(MyObject v) {
//
Passing a reference, modifies outside object:
v.i++;
return
v;
}
static
MyObject f(MyObject v) {
v
= (MyObject)v.clone(); // Local copy
v.i++;
return
v;
}
public
static void main(String[] args) {
MyObject
a = new MyObject(11);
MyObject
b = g(a);
//
Testing reference equivalence,
//
not object equivalence:
if(a
== b)
System.out.println("a
== b");
else
System.out.println("a
!= b");
System.out.println("a
= " + a);
System.out.println("b
= " + b);
MyObject
c = new MyObject(47);
MyObject
d = f(c);
if(c
== d)
System.out.println("c
== d");
Appendix
A: Passing & Returning
Objects
1023

else
System.out.println("c
!= d");
System.out.println("c
= " + c);
System.out.println("d
= " + d);
}
}
///:~
First
of all, clone(
) must
be accessible so you must
make it public.
Second,
for the initial part of
your clone(
) operation
you should call
the
base-class
version of clone(
).
The clone(
) that's
being called here is
the
one
that's predefined inside
Object,
and you can call it
because it's
protected
and
thereby accessible in derived
classes.
Object.clone(
) figures
out how big the
object is, creates
enough
memory
for a new one, and
copies all the bits
from the old to the
new.
This
is called a bitwise
copy, and is
typically what you'd expect
a clone(
)
method
to do. But before Object.clone(
) performs
its operations, it
first
checks
to see if a class is Cloneable--that
is, whether it implements
the
Cloneable
interface.
If it doesn't, Object.clone(
) throws
a
CloneNotSupportedException
to
indicate that you can't
clone it.
Thus,
you've got to surround your
call to super.clone(
) with
a try-catch
block,
to catch an exception that
should never happen (because
you've
implemented
the Cloneable
interface).
In
LocalCopy,
the two methods g( ) and
f( ) demonstrate
the difference
between
the two approaches for
argument passing. g(
) shows
passing by
reference
in which it modifies the
outside object and returns a
reference
to
that outside object, while
f( ) clones
the argument, thereby
decoupling
it
and leaving the original
object alone. It can then
proceed to do whatever
it
wants, and even to return a
reference to this new object
without any ill
effects
to the original. Notice the
somewhat curious-looking
statement:
v
= (MyObject)v.clone();
This
is where the local copy is
created. To prevent confusion by
such a
statement,
remember that this rather
strange coding idiom is
perfectly
feasible
in Java because every object
identifier is actually a reference.
So
the
reference v
is
used to clone(
) a
copy of what it refers to,
and this
returns
a reference to the base type
Object
(because
it's defined that
way
in
Object.clone(
))
that must then be cast to
the proper type.
1024
Thinking
in Java

In
main(
),
the difference between the
effects of the two
different
argument-passing
approaches in the two
different methods is tested.
The
output
is:
a
==
b
a
=
12
b
=
12
c
!=
d
c
=
47
d
=
48
It's
important to notice that the
equivalence tests in Java do
not look
inside
the objects being compared
to see if their values are
the same. The
==
and
!= operators
are simply comparing the
references.
If the
addresses
inside the references are
the same, the references
are pointing
to
the same object and
are therefore "equal." So
what the operators
are
really
testing is whether the
references are aliased to
the same object!
The
effect of Object.clone(
)
What
actually happens when
Object.clone(
) is
called that makes it
so
essential
to call super.clone(
) when
you override clone(
) in
your
class?
The clone(
) method
in the root class is
responsible for
creating
the
correct amount of storage
and making the bitwise
copy of the bits
from
the original object into
the new object's storage.
That is, it doesn't
just
make storage and copy an
Object--it
actually figures out the
size of
the
precise object that's being
copied and duplicates that.
Since all this is
happening
from the code in the
clone( )
method
defined in the root
class
(that
has no idea what's being
inherited from it), you
can guess that
the
process
involves RTTI to determine
the actual object that's
being cloned.
This
way, the clone(
) method
can create the proper
amount of storage
and
do the correct bitcopy for
that type.
Whatever
you do, the first
part of the cloning process
should normally be
a
call to super.clone(
).
This establishes the
groundwork for the
cloning
operation
by making an exact duplicate. At
this point you can
perform
other
operations necessary to complete
the cloning.
To
know for sure what
those other operations are,
you need to
understand
exactly
what Object.clone(
) buys
you. In particular, does
it
Appendix
A: Passing & Returning
Objects
1025

automatically
clone the destination of all
the references? The
following
example
tests this:
//:
appendixa:Snake.java
//
Tests cloning to see if destination
//
of references are also cloned.
public
class Snake implements Cloneable {
private
Snake next;
private
char c;
//
Value of i == number of segments
Snake(int
i, char x) {
c
= x;
if(--i
> 0)
next
= new Snake(i, (char)(x + 1));
}
void
increment() {
c++;
if(next
!= null)
next.increment();
}
public
String toString() {
String
s = ":" + c;
if(next
!= null)
s
+= next.toString();
return
s;
}
public
Object clone() {
Object
o = null;
try
{
o
= super.clone();
}
catch(CloneNotSupportedException e) {
System.err.println("Snake
can't clone");
}
return
o;
}
public
static void main(String[] args) {
Snake
s = new Snake(5, 'a');
System.out.println("s
= " + s);
Snake
s2 = (Snake)s.clone();
System.out.println("s2
= " + s2);
1026
Thinking
in Java

s.increment();
System.out.println(
"after
s.increment, s2 = " + s2);
}
}
///:~
A
Snake
is
made up of a bunch of segments,
each of type Snake.
Thus,
it's
a singly linked list. The
segments are created
recursively,
decrementing
the first constructor
argument for each segment
until zero
is
reached. To give each
segment a unique tag, the
second argument, a
char,
is incremented for each
recursive constructor
call.
The
increment( )
method
recursively increments each
tag so you can
see
the
change, and the toString(
) recursively
prints each tag. The
output is:
s
= :a:b:c:d:e
s2
= :a:b:c:d:e
after
s.increment, s2 = :a:c:d:e:f
This
means that only the
first segment is duplicated by
Object.clone(
),
therefore
it does a shallow copy. If
you want the whole
snake to be
duplicated--a
deep copy--you must perform
the additional
operations
inside
your overridden clone(
).
You'll
typically call super.clone(
) in
any class derived from a
cloneable
class
to make sure that all of
the base-class operations
(including
Object.clone(
))
take place. This is followed
by an explicit call to
clone(
) for
every reference in your
object; otherwise those
references
will
be aliased to those of the
original object. It's
analogous to the way
constructors
are called--base-class constructor
first, then the
next-derived
constructor,
and so on to the most-derived
constructor. The difference
is
that
clone( )
is
not a constructor, so there's
nothing to make it
happen
automatically.
You must make sure to do it
yourself.
Cloning
a composed object
There's
a problem you'll encounter
when trying to deep copy a
composed
object.
You must assume that
the clone(
) method
in the member objects
will
in turn perform a deep copy
on their
references,
and so on. This is
quite
a commitment. It effectively means
that for a deep copy to
work you
must
either control all of the
code in all of the classes,
or at least have
Appendix
A: Passing & Returning
Objects
1027

enough
knowledge about all of the
classes involved in the deep
copy to
know
that they are performing
their own deep copy
correctly.
This
example shows what you
must do to accomplish a deep
copy when
dealing
with a composed
object:
//:
appendixa:DeepCopy.java
//
Cloning a composed object.
class
DepthReading implements Cloneable {
private
double depth;
public
DepthReading(double depth) {
this.depth
= depth;
}
public
Object clone() {
Object
o = null;
try
{
o
= super.clone();
}
catch(CloneNotSupportedException e) {
e.printStackTrace(System.err);
}
return
o;
}
}
class
TemperatureReading implements Cloneable {
private
long time;
private
double temperature;
public
TemperatureReading(double temperature)
{
time
= System.currentTimeMillis();
this.temperature
= temperature;
}
public
Object clone() {
Object
o = null;
try
{
o
= super.clone();
}
catch(CloneNotSupportedException e) {
e.printStackTrace(System.err);
}
return
o;
}
1028
Thinking
in Java

}
class
OceanReading implements Cloneable {
private
DepthReading depth;
private
TemperatureReading temperature;
public
OceanReading(double tdata, double ddata){
temperature
= new TemperatureReading(tdata);
depth
= new DepthReading(ddata);
}
public
Object clone() {
OceanReading
o = null;
try
{
o
= (OceanReading)super.clone();
}
catch(CloneNotSupportedException e) {
e.printStackTrace(System.err);
}
//
Must clone references:
o.depth
= (DepthReading)o.depth.clone();
o.temperature
=
(TemperatureReading)o.temperature.clone();
return
o; // Upcasts back to Object
}
}
public
class DeepCopy {
public
static void main(String[] args) {
OceanReading
reading =
new
OceanReading(33.9, 100.5);
//
Now clone it:
OceanReading
r =
(OceanReading)reading.clone();
}
}
///:~
DepthReading
and
TemperatureReading
are
quite similar; they
both
contain only primitives.
Therefore, the clone(
) method
can be quite
simple:
it calls super.clone(
) and
returns the result. Note
that the
clone(
) code
for both classes is
identical.
OceanReading
is
composed of DepthReading
and
TemperatureReading
objects
and so, to produce a deep
copy, its
Appendix
A: Passing & Returning
Objects
1029

clone(
) must
clone the references inside
OceanReading.
To
accomplish
this, the result of
super.clone(
) must
be cast to an
OceanReading
object
(so you can access
the depth
and
temperature
references).
A
deep copy with ArrayList
Let's
revisit the ArrayList
example
from earlier in this
appendix. This
time
the Int2
class
is cloneable, so the ArrayList
can
be deep copied:
//:
appendixa:AddingClone.java
//
You must go through a few gyrations
//
to add cloning to your own class.
import
java.util.*;
class
Int2 implements Cloneable {
private
int i;
public
Int2(int ii) { i = ii; }
public
void increment() { i++; }
public
String toString() {
return
Integer.toString(i);
}
public
Object clone() {
Object
o = null;
try
{
o
= super.clone();
}
catch(CloneNotSupportedException e) {
System.err.println("Int2
can't clone");
}
return
o;
}
}
//
Once it's cloneable, inheritance
//
doesn't remove cloneability:
class
Int3 extends Int2 {
private
int j; // Automatically duplicated
public
Int3(int i) { super(i); }
}
public
class AddingClone {
1030
Thinking
in Java

public
static void main(String[] args) {
Int2
x = new Int2(10);
Int2
x2 = (Int2)x.clone();
x2.increment();
System.out.println(
"x
= " + x + ", x2 = " + x2);
//
Anything inherited is also cloneable:
Int3
x3 = new Int3(7);
x3
= (Int3)x3.clone();
ArrayList
v = new ArrayList();
for(int
i = 0; i < 10; i++ )
v.add(new
Int2(i));
System.out.println("v:
" + v);
ArrayList
v2 = (ArrayList)v.clone();
//
Now clone each element:
for(int
i = 0; i < v.size(); i++)
v2.set(i,
((Int2)v2.get(i)).clone());
//
Increment all v2's elements:
for(Iterator
e = v2.iterator();
e.hasNext();
)
((Int2)e.next()).increment();
//
See if it changed v's elements:
System.out.println("v:
" + v);
System.out.println("v2:
" + v2);
}
}
///:~
Int3
is
inherited from Int2
and
a new primitive member
int j is
added.
You
might think that you'd
need to override clone(
) again
to make sure j
is
copied, but that's not
the case. When Int2's
clone( )
is
called as Int3's
clone(
),
it calls Object.clone(
), which
determines that it's
working
with
an Int3
and
duplicates all the bits in
the Int3.
As long as you don't
add
references that need to be
cloned, the one call to
Object.clone(
)
performs
all of the necessary
duplication, regardless of how
far down in
the
hierarchy clone(
) is
defined.
You
can see what's necessary in
order to do a deep copy of an
ArrayList:
after
the ArrayList
is
cloned, you have to step
through and clone
each
one
of the objects pointed to by
the ArrayList.
You'd have to do
something
similar to this to do a deep
copy of a HashMap.
Appendix
A: Passing & Returning
Objects
1031

The
remainder of the example
shows that the cloning
did happen by
showing
that, once an object is
cloned, you can change it
and the original
object
is left untouched.
Deep
copy via serialization
When
you consider Java's object
serialization (introduced in Chapter
11),
you
might observe that an object
that's serialized and then
deserialized is,
in
effect, cloned.
So
why not use serialization to
perform deep copying? Here's
an example
that
compares the two approaches
by timing them:
//:
appendixa:Compete.java
import
java.io.*;
class
Thing1 implements Serializable {}
class
Thing2 implements Serializable {
Thing1
o1 = new Thing1();
}
class
Thing3 implements Cloneable {
public
Object clone() {
Object
o = null;
try
{
o
= super.clone();
}
catch(CloneNotSupportedException e) {
System.err.println("Thing3
can't clone");
}
return
o;
}
}
class
Thing4 implements Cloneable {
Thing3
o3 = new Thing3();
public
Object clone() {
Thing4
o = null;
try
{
o
= (Thing4)super.clone();
}
catch(CloneNotSupportedException e) {
System.err.println("Thing4
can't clone");
1032
Thinking
in Java

}
//
Clone the field, too:
o.o3
= (Thing3)o3.clone();
return
o;
}
}
public
class Compete {
static
final int SIZE = 5000;
public
static void main(String[] args)
throws
Exception {
Thing2[]
a = new Thing2[SIZE];
for(int
i = 0; i < a.length; i++)
a[i]
= new Thing2();
Thing4[]
b = new Thing4[SIZE];
for(int
i = 0; i < b.length; i++)
b[i]
= new Thing4();
long
t1 = System.currentTimeMillis();
ByteArrayOutputStream
buf =
new
ByteArrayOutputStream();
ObjectOutputStream
o =
new
ObjectOutputStream(buf);
for(int
i = 0; i < a.length; i++)
o.writeObject(a[i]);
//
Now get copies:
ObjectInputStream
in =
new
ObjectInputStream(
new
ByteArrayInputStream(
buf.toByteArray()));
Thing2[]
c = new Thing2[SIZE];
for(int
i = 0; i < c.length; i++)
c[i]
= (Thing2)in.readObject();
long
t2 = System.currentTimeMillis();
System.out.println(
"Duplication
via serialization: " +
(t2
- t1) + " Milliseconds");
//
Now try cloning:
t1
= System.currentTimeMillis();
Thing4[]
d = new Thing4[SIZE];
for(int
i = 0; i < d.length; i++)
d[i]
= (Thing4)b[i].clone();
Appendix
A: Passing & Returning
Objects
1033

t2
= System.currentTimeMillis();
System.out.println(
"Duplication
via cloning: " +
(t2
- t1) + " Milliseconds");
}
}
///:~
Thing2
and
Thing4
contain
member objects so that
there's some deep
copying
going on. It's interesting
to notice that while
Serializable
classes
are
easy to set up, there's
much more work going on to
duplicate them.
Cloning
involves a lot of work to
set up the class, but
the actual
duplication
of objects is relatively simple.
The results really tell
the tale.
Here
is the output from three
different runs:
Duplication
via serialization: 940
Milliseconds
Duplication
via cloning: 50 Milliseconds
Duplication
via serialization: 710
Milliseconds
Duplication
via cloning: 60 Milliseconds
Duplication
via serialization: 770
Milliseconds
Duplication
via cloning: 50 Milliseconds
Despite
the significant time
difference between serialization
and cloning,
you'll
also notice that the
serialization technique seems to
vary more in its
duration,
while cloning tends to be
more stable.
Adding
cloneability
further
down a hierarchy
If
you create a new class,
its base class defaults to
Object,
which defaults
to
noncloneability (as you'll
see in the next section). As
long as you don't
explicitly
add cloneability, you won't
get it. But you
can add it in at any
layer
and it will then be
cloneable from that layer
downward, like this:
//:
appendixa:HorrorFlick.java
//
You can insert Cloneability
//
at any level of inheritance.
import
java.util.*;
class
Person {}
1034
Thinking
in Java

class
Hero extends Person {}
class
Scientist extends Person
implements
Cloneable {
public
Object clone() {
try
{
return
super.clone();
}
catch(CloneNotSupportedException e) {
//
this should never happen:
//
It's Cloneable already!
throw
new InternalError();
}
}
}
class
MadScientist extends Scientist {}
public
class HorrorFlick {
public
static void main(String[] args) {
Person
p = new Person();
Hero
h = new Hero();
Scientist
s = new Scientist();
MadScientist
m = new MadScientist();
//
p = (Person)p.clone(); // Compile error
//
h = (Hero)h.clone(); // Compile error
s
= (Scientist)s.clone();
m
= (MadScientist)m.clone();
}
}
///:~
Before
cloneability was added, the
compiler stopped you from
trying to
clone
things. When cloneability is
added in Scientist,
then Scientist
and
all
its descendants are
cloneable.
Why
this strange design?
If
all this seems to be a
strange scheme, that's
because it is. You
might
wonder
why it worked out this
way. What is the meaning
behind this
design?
Originally,
Java was designed as a
language to control hardware
boxes,
and
definitely not with the
Internet in mind. In a
general-purpose
Appendix
A: Passing & Returning
Objects
1035

language
like this, it makes sense
that the programmer be able
to clone
any
object. Thus, clone(
) was
placed in the root class
Object,
but
it
was
a
public
method
so you could always clone
any object. This seemed to
be
the
most flexible approach, and
after all, what could it
hurt?
Well,
when Java was seen as
the ultimate Internet
programming
language,
things changed. Suddenly,
there are security issues,
and of
course,
these issues are dealt
with using objects, and
you don't necessarily
want
anyone to be able to clone
your security objects. So
what you're
seeing
is a lot of patches applied on
the original simple
and
straightforward
scheme: clone(
) is
now protected
in
Object.
You must
override
it and
implement
Cloneable and deal
with the exceptions.
It's
worth noting that you
must use the Cloneable
interface
only
if
you're
going
to call Object's
clone(
),
method, since that method
checks at run-
time
to make sure that your
class implements Cloneable.
But for
consistency
(and since Cloneable
is
empty anyway) you
should
implement
it.
Controlling
cloneability
You
might suggest that, to
remove cloneability, the
clone( )
method
simply
be made private,
but this won't work
since you cannot take
a
base-class
method and make it less
accessible in a derived class. So
it's not
that
simple. And yet, it's
necessary to be able to control
whether an object
can
be cloned. There are
actually a number of attitudes
you can take to
this
in a class that you
design:
1.
Indifference.
You don't do anything about
cloning, which means
that
your class can't be cloned
but a class that inherits
from you can
add
cloning if it wants. This
works only if the
default
Object.clone(
) will
do something reasonable with
all the fields in
your
class.
2.
Support
clone(
).
Follow the standard practice
of implementing
Cloneable
and
overriding clone(
).
In the overridden clone(
),
you
call super.clone(
) and
catch all exceptions (so
your
overridden
clone( )
doesn't
throw any
exceptions).
1036
Thinking
in Java

3.
Support
cloning conditionally. If your
class holds references
to
other
objects that might or might
not be cloneable (a
container
class,
for example), your clone( )
can
try to clone all of the
objects
for
which you have references,
and if they throw exceptions
just
pass
those exceptions out to the
programmer. For
example,
consider
a special sort of ArrayList
that
tries to clone all
the
objects
it holds. When you write
such an ArrayList,
you don't
know
what sort of objects the
client programmer might put
into
your
ArrayList,
so you don't know whether
they can be cloned.
4.
Don't
implement Cloneable
but
override clone(
) as
protected,
producing
the correct copying behavior
for any fields. This
way,
anyone
inheriting from this class
can override clone(
) and
call
super.clone(
) to
produce the correct copying
behavior. Note that
your
implementation can and
should invoke super.clone(
) even
though
that method expects a
Cloneable
object
(it will throw an
exception
otherwise), because no one
will directly invoke it on
an
object
of your type. It will get
invoked only through a
derived class,
which,
if it is to work successfully, implements
Cloneable.
5.
Try
to prevent cloning by not
implementing Cloneable
and
overriding
clone( )
to
throw an exception. This is
successful only if
any
class derived from this
calls super.clone(
) in
its redefinition
of
clone(
).
Otherwise, a programmer may be
able to get around
it.
6.
Prevent
cloning by making your class
final.
If clone(
) has
not
been
overridden by any of your
ancestor classes, then it
can't be. If
it
has, then override it again
and throw
CloneNotSupportedException.
Making the class final is
the
only
way to guarantee that
cloning is prevented. In addition,
when
dealing
with security objects or
other situations in which
you want
to
control the number of
objects created you should
make all
constructors
private
and
provide one or more special
methods for
creating
objects. That way, these
methods can restrict the
number
of
objects created and the
conditions in which they're
created. (A
particular
case of this is the
singleton
pattern
shown in Thinking
in
Patterns
with Java, downloadable
at .)
Appendix
A: Passing & Returning
Objects
1037
Table of Contents:
- Introduction to Objects:The progress of abstraction, An object has an interface
- Everything is an Object:You manipulate objects with references, Your first Java program
- Controlling Program Flow:Using Java operators, Execution control, true and false
- Initialization & Cleanup:Method overloading, Member initialization
- Hiding the Implementation:the library unit, Java access specifiers, Interface and implementation
- Reusing Classes:Composition syntax, Combining composition and inheritance
- Polymorphism:Upcasting revisited, The twist, Designing with inheritance
- Interfaces & Inner Classes:Extending an interface with inheritance, Inner class identifiers
- Holding Your Objects:Container disadvantage, List functionality, Map functionality
- Error Handling with Exceptions:Basic exceptions, Catching an exception
- The Java I/O System:The File class, Compression, Object serialization, Tokenizing input
- Run-time Type Identification:The need for RTTI, A class method extractor
- Creating Windows & Applets:Applet restrictions, Running applets from the command line
- Multiple Threads:Responsive user interfaces, Sharing limited resources, Runnable revisited
- Distributed Computing:Network programming, Servlets, CORBA, Enterprise JavaBeans
- A: Passing & Returning Objects:Aliasing, Making local copies, Cloning objects
- B: The Java Native Interface (JNI):Calling a native method, the JNIEnv argument
- Java Programming Guidelines:Design, Implementation
- Resources:Software, Books, My own list of books
- Index