 |

stuffing
the current stack
information into the old
exception object.
Here's
what it
looks like:
//:
c10:Rethrowing.java
//
Demonstrating fillInStackTrace()
public class
Rethrowing {
public
static void f() throws Exception {
System.out.println(
"originating
the exception in f()");
throw
new Exception("thrown from f()");
}
public
static void g() throws Throwable {
try
{
f();
}
catch(Exception e) {
System.err.println(
"Inside
g(), e.printStackTrace()");
e.printStackTrace(System.err);
throw
e; // 17
//
throw e.fillInStackTrace(); // 18
}
}
public
static void
main(String[]
args) throws Throwable {
try
{
g();
}
catch(Exception e) {
System.err.println(
"Caught
in main, e.printStackTrace()");
e.printStackTrace(System.err);
}
}
}
///:~
The
important line numbers are
marked as comments. With
line 17
uncommented
(as shown), the output
is:
originating
the exception in f()
Inside
g(), e.printStackTrace()
java.lang.Exception:
thrown from f()
at
Rethrowing.f(Rethrowing.java:8)
546
Thinking
in Java

at
Rethrowing.g(Rethrowing.java:12)
at
Rethrowing.main(Rethrowing.java:24)
Caught
in main, e.printStackTrace()
java.lang.Exception:
thrown from f()
at
Rethrowing.f(Rethrowing.java:8)
at
Rethrowing.g(Rethrowing.java:12)
at
Rethrowing.main(Rethrowing.java:24)
So
the exception stack trace
always remembers its true
point of origin, no
matter
how many times it gets
rethrown.
With
line 17 commented and line
18 uncommented, fillInStackTrace(
)
is
used instead, and the
result is:
originating
the exception in f()
Inside
g(), e.printStackTrace()
java.lang.Exception:
thrown from f()
at
Rethrowing.f(Rethrowing.java:8)
at
Rethrowing.g(Rethrowing.java:12)
at
Rethrowing.main(Rethrowing.java:24)
Caught
in main, e.printStackTrace()
java.lang.Exception:
thrown from f()
at
Rethrowing.g(Rethrowing.java:18)
at
Rethrowing.main(Rethrowing.java:24)
Because
of fillInStackTrace(
),
line 18 becomes the new
point of origin
of
the exception.
The
class Throwable
must
appear in the exception
specification for g(
)
and
main( )
because
fillInStackTrace(
) produces
a reference to a
Throwable
object.
Since Throwable
is
a base class of Exception,
it's
possible
to get an object that's a
Throwable
but
not
an
Exception,
so
the
handler for Exception
in
main( )
might
miss it. To make
sure
everything
is in order, the compiler
forces an exception specification
for
Throwable.
For example, the exception
in the following program is
not
caught
in main(
):
//:
c10:ThrowOut.java
public
class ThrowOut {
public
static void
main(String[]
args) throws Throwable {
try
{
Chapter
10: Error Handling with
Exceptions
547

throw
new Throwable();
}
catch(Exception e) {
System.err.println("Caught
in main()");
}
}
}
///:~
It's
also possible to rethrow a
different exception from the
one you caught.
If
you do this, you get a
similar effect as when you
use
fillInStackTrace(
)--the
information about the
original site of the
exception
is lost, and what you're
left with is the information
pertaining to
the
new throw:
//:
c10:RethrowNew.java
//
Rethrow a different object
//
from the one that was caught.
class
OneException extends Exception {
public
OneException(String s) { super(s); }
}
class
TwoException extends Exception {
public
TwoException(String s) { super(s); }
}
public
class RethrowNew {
public
static void f() throws OneException {
System.out.println(
"originating
the exception in f()");
throw
new OneException("thrown from f()");
}
public
static void main(String[] args)
throws
TwoException {
try
{
f();
}
catch(OneException e) {
System.err.println(
"Caught
in main, e.printStackTrace()");
e.printStackTrace(System.err);
throw
new TwoException("from main()");
}
548
Thinking
in Java

}
}
///:~
The
output is:
originating
the exception in f()
Caught
in main, e.printStackTrace()
OneException:
thrown from f()
at
RethrowNew.f(RethrowNew.java:17)
at
RethrowNew.main(RethrowNew.java:22)
Exception
in thread "main" TwoException: from main()
at
RethrowNew.main(RethrowNew.java:27)
The
final exception knows only
that it came from main(
),
and not from
f(
).
You
never have to worry about
cleaning up the previous
exception, or any
exceptions
for that matter. They're
all heap-based objects
created with
new,
so the garbage collector
automatically cleans them
all up.
Standard
Java exceptions
The
Java class Throwable
describes
anything that can be thrown
as an
exception.
There are two general
types of Throwable
objects
("types of"
=
"inherited from"). Error
represents
compile-time and system
errors
that
you don't worry about
catching (except in special
cases). Exception
is
the basic type that
can be thrown from any of
the standard Java
library
class
methods and from your
methods and run-time
accidents. So the
Java
programmer's base type of
interest is Exception.
The
best way to get an overview
of the exceptions is to browse
the HTML
Java
documentation that you can
download from java.sun.com.
It's
worth
doing
this once just to get a
feel for the various
exceptions, but you'll
soon
see
that there isn't anything
special between one
exception and the
next
except
for the name. Also,
the number of exceptions in
Java keeps
expanding;
basically it's pointless to
print them in a book. Any
new library
you
get from a third-party
vendor will probably have
its own exceptions as
well.
The important thing to
understand is the concept
and what you
should
do with the
exceptions.
Chapter
10: Error Handling with
Exceptions
549

The
basic idea is that the
name of the exception
represents the
problem
that
occurred, and the exception
name is intended to be relatively
self-
explanatory.
The exceptions are not
all defined in java.lang;
some are
created
to support other libraries
such as util,
net,
and
io,
which you can
see
from their full class
names or what they are
inherited from. For
example,
all I/O exceptions are
inherited from java.io.IOException.
The
special case of
RuntimeException
The
first example in this
chapter was
if(t
== null)
throw
new NullPointerException();
It
can be a bit horrifying to
think that you must
check for null
on
every
reference
that is passed into a method
(since you can't know if
the caller
has
passed you a valid
reference). Fortunately, you
don't--this is part of
the
standard run-time checking
that Java performs for
you, and if any
call
is
made to a null
reference,
Java will automatically
throw a
NullPointerException.
So the above bit of code is
always superfluous.
There's
a whole group of exception
types that are in this
category. They're
always
thrown automatically by Java
and you don't need to
include them
in
your exception specifications.
Conveniently enough, they're
all grouped
together
by putting them under a
single base class
called
RuntimeException,
which is a perfect example of
inheritance: it
establishes
a family of types that have
some characteristics and
behaviors
in
common. Also, you never
need to write an exception
specification
saying
that a method might throw a
RuntimeException,
since that's
just
assumed. Because they
indicate bugs, you virtually
never catch a
RuntimeException--it's
dealt with automatically. If
you were forced to
check
for RuntimeExceptions
your code could get
messy. Even though
you
don't typically catch
RuntimeExceptions,
in your own packages
you
might choose to throw some
of the RuntimeExceptions.
What
happens when you don't
catch such exceptions? Since
the compiler
doesn't
enforce exception specifications
for these, it's quite
plausible that
a
RuntimeException
could
percolate all the way
out to your main(
)
550
Thinking
in Java

method
without being caught. To see
what happens in this case,
try the
following
example:
//:
c10:NeverCaught.java
//
Ignoring RuntimeExceptions.
public
class NeverCaught {
static
void f() {
throw
new RuntimeException("From f()");
}
static
void g() {
f();
}
public
static void main(String[] args) {
g();
}
}
///:~
You
can already see that a
RuntimeException
(or
anything inherited
from
it) is a special case, since
the compiler doesn't require
an exception
specification
for these types.
The
output is:
Exception
in thread "main"
java.lang.RuntimeException:
From f()
at
NeverCaught.f(NeverCaught.java:9)
at
NeverCaught.g(NeverCaught.java:12)
at
NeverCaught.main(NeverCaught.java:15)
So
the answer is: If a
RuntimeException
gets
all the way out
to
main(
) without
being caught, printStackTrace(
) is
called for that
exception
as the program exits.
Keep
in mind that you can
only ignore RuntimeExceptions
in your
coding,
since all other handling is
carefully enforced by the
compiler. The
reasoning
is that a RuntimeException
represents
a programming
error:
1.
An
error you cannot catch
(receiving a null
reference
handed to
your
method by a client programmer,
for example) .
Chapter
10: Error Handling with
Exceptions
551

2.
An
error that you, as a
programmer, should have
checked for in
your
code (such as ArrayIndexOutOfBoundsException
where
you
should have paid attention
to the size of the
array).
You
can see what a tremendous
benefit it is to have exceptions in
this
case,
since they help in the
debugging process.
It's
interesting to notice that
you cannot classify Java
exception handling
as
a single-purpose tool. Yes, it is
designed to handle those
pesky run-time
errors
that will occur because of
forces outside your code's
control, but it's
also
essential for certain types
of programming bugs that the
compiler
cannot
detect.
Performing
cleanup
with
finally
There's
often some piece of code
that you want to execute
whether or not
an
exception is thrown within a
try block.
This usually pertains to
some
operation
other than memory recovery
(since that's taken care of
by the
garbage
collector). To achieve this
effect, you use a finally
clause3 at
the
end
of all the exception
handlers. The full picture
of an exception
handling
section is thus:
try
{
//
The guarded region: Dangerous activities
//
that might throw A, B, or C
}
catch(A a1) {
//
Handler for situation A
}
catch(B b1) {
//
Handler for situation B
}
catch(C c1) {
//
Handler for situation C
}
finally
{
//
Activities that happen every time
3
C++ exception handling
does not have the
finally
clause
because it relies on
destructors
to
accomplish this sort of
cleanup.
552
Thinking
in Java

}
To
demonstrate that the
finally
clause
always runs, try this
program:
//:
c10:FinallyWorks.java
//
The finally clause is always executed.
class
ThreeException extends Exception {}
public
class FinallyWorks {
static
int count = 0;
public
static void main(String[] args) {
while(true)
{
try
{
//
Post-increment is zero first time:
if(count++
== 0)
throw
new ThreeException();
System.out.println("No
exception");
}
catch(ThreeException e) {
System.err.println("ThreeException");
}
finally {
System.err.println("In
finally clause");
if(count
== 2) break; // out of "while"
}
}
}
}
///:~
This
program also gives a hint
for how you can
deal with the fact
that
exceptions
in Java (like exceptions in
C++) do not allow you to
resume
back
to where the exception was
thrown, as discussed earlier. If
you place
your
try block
in a loop, you can establish
a condition that must be
met
before
you continue the program.
You can also add a
static
counter
or
some
other device to allow the
loop to try several
different approaches
before
giving up. This way
you can build a greater
level of robustness
into
your
programs.
The
output is:
ThreeException
In
finally clause
No
exception
Chapter
10: Error Handling with
Exceptions
553

In
finally clause
Whether
an exception is thrown or not,
the finally
clause
is always
executed.
What's
finally
for?
In
a language without garbage
collection and
without
automatic
destructor
calls4,
finally
is
important because it allows
the programmer
to
guarantee the release of
memory regardless of what
happens in the try
block.
But Java has garbage
collection, so releasing memory is
virtually
never
a problem. Also, it has no
destructors to call. So when do
you need
to
use finally
in
Java?
finally
is
necessary when you need to
set something other
than
memory
back
to its original state. This
is some kind of cleanup like
an open file or
network
connection, something you've
drawn on the screen, or even
a
switch
in the outside world, as
modeled in the following
example:
//:
c10:OnOffSwitch.java
//
Why use finally?
class
Switch {
boolean
state = false;
boolean
read() { return state; }
void
on() { state = true; }
void
off() { state = false; }
}
class
OnOffException1 extends Exception {}
class
OnOffException2 extends Exception {}
public
class OnOffSwitch {
static
Switch sw = new Switch();
static
void f() throws
OnOffException1,
OnOffException2 {}
public
static void main(String[] args) {
4
A destructor is a
function that's always
called when an object
becomes unused. You
always
know exactly where and
when the destructor gets called. C++
has automatic
destructor
calls, but Delphi's Object Pascal
versions 1 and 2 do not (which
changes the
meaning
and use of the concept of a
destructor for that
language).
554
Thinking
in Java

try
{
sw.on();
//
Code that can throw exceptions...
f();
sw.off();
}
catch(OnOffException1 e) {
System.err.println("OnOffException1");
sw.off();
}
catch(OnOffException2 e) {
System.err.println("OnOffException2");
sw.off();
}
}
}
///:~
The
goal here is to make sure
that the switch is off
when main(
) is
completed,
so sw.off(
) is
placed at the end of the
try block and at
the
end
of each exception handler.
But it's possible that an
exception could be
thrown
that isn't caught here, so
sw.off( )
would
be missed. However,
with
finally
you
can place the cleanup
code from a try block in
just one
place:
//:
c10:WithFinally.java
//
Finally Guarantees cleanup.
public
class WithFinally {
static
Switch sw = new Switch();
public
static void main(String[] args) {
try
{
sw.on();
//
Code that can throw exceptions...
OnOffSwitch.f();
}
catch(OnOffException1 e) {
System.err.println("OnOffException1");
}
catch(OnOffException2 e) {
System.err.println("OnOffException2");
}
finally {
sw.off();
}
}
}
///:~
Chapter
10: Error Handling with
Exceptions
555

Here
the sw.off(
) has
been moved to just one
place, where it's
guaranteed
to run no matter what
happens.
Even
in cases in which the
exception is not caught in
the current set of
catch
clauses,
finally
will
be executed before the
exception handling
mechanism
continues its search for a
handler at the next higher
level:
//:
c10:AlwaysFinally.java
//
Finally is always executed.
class
FourException extends Exception {}
public
class AlwaysFinally {
public
static void main(String[] args) {
System.out.println(
"Entering
first try block");
try
{
System.out.println(
"Entering
second try block");
try
{
throw
new FourException();
}
finally {
System.out.println(
"finally
in 2nd try block");
}
}
catch(FourException e) {
System.err.println(
"Caught
FourException in 1st try block");
}
finally {
System.err.println(
"finally
in 1st try block");
}
}
}
///:~
The
output for this program
shows you what
happens:
Entering
first try block
Entering
second try block
finally
in 2nd try block
Caught
FourException in 1st try block
finally
in 1st try block
556
Thinking
in Java

The
finally
statement
will also be executed in
situations in which break
and
continue
statements
are involved. Note that,
along with the
labeled
break
and
labeled continue,
finally
eliminates
the need for a goto
statement
in Java.
Pitfall:
the lost exception
In
general, Java's exception
implementation is quite outstanding,
but
unfortunately
there's a flaw. Although
exceptions are an indication of
a
crisis
in your program and should
never be ignored, it's
possible for an
exception
to simply be lost. This
happens with a particular
configuration
using
a finally
clause:
//:
c10:LostMessage.java
//
How an exception can be lost.
class
VeryImportantException extends Exception {
public
String toString() {
return
"A very important exception!";
}
}
class
HoHumException extends Exception {
public
String toString() {
return
"A trivial exception";
}
}
public
class LostMessage {
void
f() throws VeryImportantException {
throw
new VeryImportantException();
}
void
dispose() throws HoHumException {
throw
new HoHumException();
}
public
static void main(String[] args)
throws
Exception {
LostMessage
lm = new LostMessage();
try
{
lm.f();
Chapter
10: Error Handling with
Exceptions
557

}
finally {
lm.dispose();
}
}
}
///:~
The
output is:
Exception
in thread "main" A trivial exception
at
LostMessage.dispose(LostMessage.java:21)
at
LostMessage.main(LostMessage.java:29)
You
can see that there's no
evidence of the VeryImportantException,
which
is simply replaced by the
HoHumException
in
the finally
clause.
This is a rather serious
pitfall, since it means that
an exception can
be
completely lost, and in a
far more subtle and
difficult-to-detect fashion
than
the example above. In
contrast, C++ treats the
situation in which a
second
exception is thrown before
the first one is handled as
a dire
programming
error. Perhaps a future
version of Java will repair
this
problem
(on the other hand,
you will typically wrap
any method that
throws
an exception, such as dispose(
),
inside a try-catch
clause).
Exception
restrictions
When
you override a method, you
can throw only the
exceptions that have
been
specified in the base-class
version of the method. This
is a useful
restriction,
since it means that code
that works with the
base class will
automatically
work with any object
derived from the base
class (a
fundamental
OOP concept, of course),
including exceptions.
This
example demonstrates the
kinds of restrictions imposed
(at compile-
time)
for exceptions:
//:
c10:StormyInning.java
//
Overridden methods may throw only the
//
exceptions specified in their base-class
//
versions, or exceptions derived from the
//
base-class exceptions.
class
BaseballException extends Exception {}
class
Foul extends BaseballException {}
558
Thinking
in Java

class
Strike extends BaseballException {}
abstract
class Inning {
Inning()
throws BaseballException {}
void
event () throws BaseballException {
//
Doesn't actually have to throw anything
}
abstract
void atBat() throws Strike, Foul;
void
walk() {} // Throws nothing
}
class
StormException extends Exception {}
class
RainedOut extends StormException {}
class
PopFoul extends Foul {}
interface
Storm {
void
event() throws RainedOut;
void
rainHard() throws RainedOut;
}
public
class StormyInning extends Inning
implements
Storm {
//
OK to add new exceptions for
//
constructors, but you must deal
//
with the base constructor
exceptions:
StormyInning()
throws RainedOut,
BaseballException
{}
StormyInning(String
s) throws Foul,
BaseballException
{}
//
Regular methods must conform to base class:
//!
void walk() throws PopFoul {} //Compile error
//
Interface CANNOT add exceptions to existing
//
methods from the base class:
//!
public void event() throws RainedOut {}
//
If the method doesn't already exist in the
//
base class, the exception is OK:
public
void rainHard() throws RainedOut {}
//
You can choose to not throw any exceptions,
//
even if base version does:
public
void event() {}
//
Overridden methods can throw
Chapter
10: Error Handling with
Exceptions
559

//
inherited exceptions:
void
atBat() throws PopFoul {}
public
static void main(String[] args) {
try
{
StormyInning
si = new StormyInning();
si.atBat();
}
catch(PopFoul e) {
System.err.println("Pop
foul");
}
catch(RainedOut e) {
System.err.println("Rained
out");
}
catch(BaseballException e) {
System.err.println("Generic
error");
}
//
Strike not thrown in derived version.
try
{
//
What happens if you upcast?
Inning
i = new StormyInning();
i.atBat();
//
You must catch the exceptions from the
//
base-class version of the method:
}
catch(Strike e) {
System.err.println("Strike");
}
catch(Foul e) {
System.err.println("Foul");
}
catch(RainedOut e) {
System.err.println("Rained
out");
}
catch(BaseballException e) {
System.err.println(
"Generic
baseball exception");
}
}
}
///:~
In
Inning,
you can see that
both the constructor and
the event(
)
method
say they will throw an
exception, but they never
do. This is legal
because
it allows you to force the
user to catch any exceptions
that might
be
added in overridden versions of
event(
).
The same idea holds
for
abstract
methods,
as seen in atBat(
).
The
interface
Storm is
interesting because it contains
one method
(event(
))
that is defined in Inning,
and one method that
isn't. Both
560
Thinking
in Java

methods
throw a new type of
exception, RainedOut.
When
StormyInning
extends Inning and
implements
Storm,
you'll see
that
the event(
) method
in Storm
cannot
change
the exception
interface
of event(
) in
Inning.
Again, this makes sense
because
otherwise
you'd never know if you
were catching the correct
thing when
working
with the base class. Of
course, if a method described in
an
interface
is
not in the base class,
such as rainHard(
),
then there's no
problem
if it throws exceptions.
The
restriction on exceptions does
not apply to constructors.
You can see
in
StormyInning
that
a constructor can throw
anything it wants,
regardless
of what the base-class
constructor throws. However,
since a
base-class
constructor must always be
called one way or another
(here,
the
default constructor is called
automatically), the
derived-class
constructor
must declare any base-class
constructor exceptions in
its
exception
specification. Note that a
derived-class constructor cannot
catch
exceptions
thrown by its base-class
constructor.
The
reason StormyInning.walk(
) will
not compile is that it
throws an
exception,
while Inning.walk(
) does
not. If this was allowed,
then you
could
write code that called
Inning.walk( )
and
that didn't have to
handle
any exceptions, but then
when you substituted an
object of a class
derived
from Inning,
exceptions would be thrown so
your code would
break.
By forcing the derived-class
methods to conform to the
exception
specifications
of the base-class methods,
substitutability of objects is
maintained.
The
overridden event(
) method
shows that a derived-class
version of a
method
may choose not to throw
any exceptions, even if the
base-class
version
does. Again, this is fine
since it doesn't break any
code that is
written--assuming
the base-class version
throws exceptions. Similar
logic
applies
to atBat(
),
which throws PopFoul,
an exception that is
derived
from
Foul thrown
by the base-class version of
atBat(
).
This way, if
someone
writes code that works
with Inning
and
calls atBat(
),
they
must
catch the Foul
exception.
Since PopFoul
is
derived from Foul,
the
exception
handler will also catch
PopFoul.
The
last point of interest is in
main(
).
Here you can see
that if you're
dealing
with exactly a StormyInning
object,
the compiler forces you
to
Chapter
10: Error Handling with
Exceptions
561

catch
only the exceptions that
are specific to that class,
but if you upcast to
the
base type then the
compiler (correctly) forces
you to catch the
exceptions
for the base type.
All these constraints
produce much more
robust
exception-handling code5.
It's
useful to realize that
although exception specifications
are enforced by
the
compiler during inheritance,
the exception specifications
are not part
of
the type of a method, which
is comprised of only the
method name and
argument
types. Therefore, you cannot
overload methods based
on
exception
specifications. In addition, just
because an exception
specification
exists in a base-class version of a
method doesn't mean
that
it
must exist in the
derived-class version of the
method. This is quite
different
from inheritance rules,
where a method in the base
class must
also
exist in the derived class.
Put another way, the
"exception
specification
interface" for a particular
method may narrow
during
inheritance
and overriding, but it may
not widen--this is precisely
the
opposite
of the rule for the
class interface during
inheritance.
Constructors
When
writing code with
exceptions, it's particularly
important that you
always
ask, "If an exception
occurs, will this be
properly cleaned up?"
Most
of the time you're fairly
safe, but in constructors
there's a problem.
The
constructor puts the object
into a safe starting state,
but it might
perform
some operation--such as opening a
file--that doesn't get
cleaned
up
until the user is finished
with the object and
calls a special
cleanup
method.
If you throw an exception
from inside a constructor,
these
cleanup
behaviors might not occur
properly. This means that
you must be
especially
diligent while you write
your constructor.
Since
you've just learned about
finally,
you might think that it is
the
correct
solution. But it's not
quite that simple, because
finally
performs
the
cleanup code every
time, even in
the situations in which you
don't
want
the cleanup code executed
until the cleanup method
runs. Thus, if
5
ISO C++ added
similar constraints that require
derived-method exceptions to be
the
same
as, or derived from, the
exceptions thrown by the base-class
method. This is one
case
in
which C++ is actually able to check
exception specifications at
compile-time.
562
Thinking
in Java

you
do perform cleanup in finally,
you must set some
kind of flag when
the
constructor finishes normally so
that you don't do anything
in the
finally
block
if the flag is set. Because
this isn't particularly
elegant (you
are
coupling your code from
one place to another), it's
best if you try to
avoid
performing this kind of
cleanup in finally
unless
you are forced
to.
In
the following example, a
class called InputFile
is
created that opens a
file
and allows you to read it
one line (converted into a
String)
at a time.
It
uses the classes FileReader
and
BufferedReader
from
the Java
standard
I/O library that will be
discussed in Chapter 11, but
which are
simple
enough that you probably
won't have any trouble
understanding
their
basic use:
//:
c10:Cleanup.java
//
Paying attention to exceptions
//
in constructors.
import
java.io.*;
class
InputFile {
private
BufferedReader in;
InputFile(String
fname) throws Exception {
try
{
in
=
new
BufferedReader(
new
FileReader(fname));
//
Other code that might throw exceptions
}
catch(FileNotFoundException e) {
System.err.println(
"Could
not open " + fname);
//
Wasn't open, so don't close it
throw
e;
}
catch(Exception e) {
//
All other exceptions must close it
try
{
in.close();
}
catch(IOException e2) {
System.err.println(
"in.close()
unsuccessful");
}
throw
e; // Rethrow
}
finally {
Chapter
10: Error Handling with
Exceptions
563

//
Don't close it here!!!
}
}
String
getLine() {
String
s;
try
{
s
= in.readLine();
}
catch(IOException e) {
System.err.println(
"readLine()
unsuccessful");
s
= "failed";
}
return
s;
}
void
cleanup() {
try
{
in.close();
}
catch(IOException e2) {
System.err.println(
"in.close()
unsuccessful");
}
}
}
public
class Cleanup {
public
static void main(String[] args) {
try
{
InputFile
in =
new
InputFile("Cleanup.java");
String
s;
int
i = 1;
while((s
= in.getLine()) != null)
System.out.println(""+
i++ + ": " + s);
in.cleanup();
}
catch(Exception e) {
System.err.println(
"Caught
in main, e.printStackTrace()");
e.printStackTrace(System.err);
}
}
}
///:~
564
Thinking
in Java

The
constructor for InputFile
takes
a String
argument,
which is the
name
of the file you want to
open. Inside a try
block,
it creates a
FileReader
using
the file name. A FileReader
isn't
particularly useful
until
you turn around and
use it to create a BufferedReader
that
you
can
actually talk to--notice
that one of the benefits of
InputFile
is
that it
combines
these two actions.
If
the FileReader
constructor
is unsuccessful, it throws a
FileNotFoundException,
which must be caught
separately because
that's
the one case in which
you don't want to close
the file since it
wasn't
successfully
opened. Any other
catch
clauses must close the
file because it
was
opened
by the time those catch
clauses are entered. (Of
course, this is
trickier
if more than one method
can throw a FileNotFoundException.
In
that case, you might
want to break things into
several try
blocks.)
The
close(
) method
might throw an exception so it is
tried and caught
even
though
it's within the block of
another catch
clause--it's
just another pair
of
curly braces to the Java
compiler. After performing
local operations,
the
exception is rethrown, which is
appropriate because this
constructor
failed,
and you wouldn't want
the calling method to assume
that the
object
had been properly created
and was valid.
In
this example, which doesn't
use the aforementioned
flagging
technique,
the finally
clause
is definitely not
the
place to close(
) the
file,
since that would close it
every time the constructor
completed. Since
we
want the file to be open
for the useful lifetime of
the InputFile
object
this
would not be
appropriate.
The
getLine(
) method
returns a String
containing
the next line in
the
file.
It calls readLine(
), which
can throw an exception, but
that
exception
is caught so getLine(
) doesn't
throw any exceptions. One
of
the
design issues with
exceptions is whether to handle an
exception
completely
at this level, to handle it
partially and pass the
same exception
(or
a different one) on, or
whether to simply pass it
on. Passing it on,
when
appropriate, can certainly
simplify coding. The
getLine(
) method
becomes:
String
getLine() throws IOException {
return
in.readLine();
}
Chapter
10: Error Handling with
Exceptions
565

But
of course, the caller is now
responsible for handling
any
IOException
that
might arise.
The
cleanup(
) method
must be called by the user
when finished using
the
InputFile
object.
This will release the
system resources (such as
file
handles)
that are used by the
BufferedReader
and/or
FileReader
objects6.
You don't want to do this
until you're finished with
the
InputFile
object,
at the point you're going to
let it go. You might
think of
putting
such functionality into a
finalize(
) method,
but as mentioned in
Chapter
4 you can't always be sure
that finalize(
) will
be called (even if
you
can
be
sure that it will be called,
you don't know when).
This is one of
the
downsides to Java: all
cleanup--other than memory
cleanup--doesn't
happen
automatically, so you must
inform the client programmer
that
they
are responsible, and
possibly guarantee that
cleanup occurs using
finalize(
).
In
Cleanup.java
an
InputFile
is
created to open the same
source file
that
creates the program, the
file is read in a line at a
time, and line
numbers
are added. All exceptions
are caught generically in
main(
),
although
you could choose greater
granularity.
One
of the benefits of this
example is to show you why
exceptions are
introduced
at this point in the
book--you can't do basic I/O
without using
exceptions.
Exceptions are so integral to
programming in Java,
especially
because
the compiler enforces them,
that you can accomplish
only so
much
without knowing how to work
with them.
Exception
matching
When
an exception is thrown, the
exception handling system
looks
through
the "nearest" handlers in
the order they are
written. When it
finds
a match, the exception is
considered handled, and no
further
searching
occurs.
6
In C++, a
destructor
would
handle this for you.
566
Thinking
in Java

Matching
an exception doesn't require a
perfect match between
the
exception
and its handler. A
derived-class object will
match a handler for
the
base class, as shown in this
example:
//:
c10:Human.java
//
Catching exception hierarchies.
class
Annoyance extends Exception {}
class
Sneeze extends Annoyance {}
public
class Human {
public
static void main(String[] args) {
try
{
throw
new Sneeze();
}
catch(Sneeze s) {
System.err.println("Caught
Sneeze");
}
catch(Annoyance a) {
System.err.println("Caught
Annoyance");
}
}
}
///:~
The
Sneeze
exception
will be caught by the first
catch
clause
that it
matches--which
is the first one, of course.
However, if you remove
the
first
catch clause, leaving
only:
try
{
throw
new Sneeze();
}
catch(Annoyance a) {
System.err.println("Caught
Annoyance");
}
The
code will still work
because it's catching the
base class of Sneeze.
Put
another
way, catch(Annoyance
e) will
catch an Annoyance
or
any
class
derived from it. This is
useful because if you decide
to add more
derived
exceptions to a method, then
the client programmer's code
will
not
need changing as long as the
client catches the base
class exceptions.
If
you try to "mask" the
derived-class exceptions by putting
the base-class
catch
clause first, like
this:
try
{
Chapter
10: Error Handling with
Exceptions
567

throw
new Sneeze();
}
catch(Annoyance a) {
System.err.println("Caught
Annoyance");
}
catch(Sneeze s) {
System.err.println("Caught
Sneeze");
}
the
compiler will give you an
error message, since it sees
that the Sneeze
catch-clause
can never be reached.
Exception
guidelines
Use
exceptions to:
1.
Fix
the problem and call
the method that caused
the exception
again.
2.
Patch
things up and continue
without retrying the
method.
3.
Calculate
some alternative result
instead of what the method
was
supposed
to produce.
4.
Do
whatever you can in the
current context and rethrow
the same
exception
to a higher context.
5.
Do
whatever you can in the
current context and throw a
different
exception
to a higher context.
6.
Terminate
the program.
7.
Simplify.
(If your exception scheme
makes things more
complicated,
then it is painful and
annoying to use.)
8.
Make
your library and program
safer. (This is a
short-term
investment
for debugging, and a
long-term investment
(for
application
robustness.)
Summary
Improved
error recovery is one of the
most powerful ways that
you can
increase
the robustness of your code.
Error recovery is a
fundamental
concern
for every program you
write, but it's especially
important in Java,
568
Thinking
in Java

where
one of the primary goals is
to create program components
for
others
to use. To
create a robust system, each
component must be
robust.
The
goals for exception handling
in Java are to simplify the
creation of
large,
reliable programs using less
code than currently
possible, and with
more
confidence that your
application doesn't have an
unhandled error.
Exceptions
are not terribly difficult
to learn, and are one of
those features
that
provide immediate and
significant benefits to your
project.
Fortunately,
Java enforces all aspects of
exceptions so it's guaranteed
that
they
will be used consistently by
both library designers and
client
programmers.
Exercises
Solutions
to selected exercises can be
found in the electronic
document The
Thinking in Java
Annotated
Solution Guide, available
for a small fee from
.
1.
Create
a class with a main(
) that
throws an object of
class
Exception
inside
a try
block.
Give the constructor
for
Exception
a
String
argument.
Catch the exception inside
a
catch
clause
and print the String
argument.
Add a finally
clause
and
print a message to prove you
were there.
2.
Create
your own exception class
using the extends
keyword.
Write
a constructor for this class
that takes a String
argument
and
stores it inside the object
with a String
reference.
Write a
method
that prints out the
stored String.
Create a try-catch
clause
to exercise your new
exception.
3.
Write
a class with a method that
throws an exception of the
type
created
in Exercise 2. Try compiling it
without an exception
specification
to see what the compiler
says. Add the
appropriate
exception
specification. Try out your
class and its exception
inside
a
try-catch clause.
4.
Define
an object reference and
initialize it to null.
Try to call a
method
through this reference. Now
wrap the code in a try-catch
clause
to catch the
exception.
Chapter
10: Error Handling with
Exceptions
569

5.
Create
a class with two methods,
f( ) and
g( ).
In g(
),
throw an
exception
of a new type that you
define. In f(
),
call g(
),
catch its
exception
and, in the catch
clause,
throw a different exception
(of
a
second type that you
define). Test your code in
main(
).
6.
Create
three new types of
exceptions. Write a class
with a method
that
throws all three. In
main(
),
call the method but
only use a
single
catch
clause
that will catch all
three types of
exceptions.
7.
Write
code to generate and catch
an
ArrayIndexOutOfBoundsException.
8.
Create
your own resumption-like
behavior using a while
loop
that
repeats
until an exception is no longer
thrown.
9.
Create
a three-level hierarchy of exceptions.
Now create a base-
class
A with
a method that throws an
exception at the base of
your
hierarchy.
Inherit B
from
A and
override the method so it
throws
an
exception at level two of
your hierarchy. Repeat by
inheriting
class
C from
B.
In main(
),
create a C
and
upcast it to A,
then call
the
method.
10.
Demonstrate
that a derived-class constructor
cannot catch
exceptions
thrown by its base-class
constructor.
11.
Show
that OnOffSwitch.java
can
fail by throwing a
RuntimeException
inside
the try
block.
12.
Show
that WithFinally.java
doesn't
fail by throwing a
RuntimeException
inside
the try
block.
13.
Modify
Exercise 6 by adding a finally
clause.
Verify your finally
clause
is executed, even if a NullPointerException
is
thrown.
14.
Create
an example where you use a
flag to control whether
cleanup
code
is called, as described in the
second paragraph after
the
heading
"Constructors."
15.
Modify
StormyInning.java
by
adding an UmpireArgument
exception
type, and methods that
throw this exception. Test
the
modified
hierarchy.
570
Thinking
in Java

16.
Remove
the first catch clause in
Human.java
and
verify that the
code
still compiles and runs
properly.
17.
Add
a second level of exception
loss to LostMessage.java
so
that
the
HoHumException
is
itself replaced by a third
exception.
18.
In
Chapter 5, find the two
programs called Assert.java
and
modify
these to throw their own
type of exception instead
of
printing
to System.err.
This exception should be an
inner class
that
extends RuntimeException.
19.
Add
an appropriate set of exceptions
to
c08:GreenhouseControls.java.
Chapter
10: Error Handling with
Exceptions
571

11:
The Java
I/O
System
Creating
a good input/output (I/O)
system is one of the
more
difficult tasks for the
language designer.
This
is evidenced by the number of
different approaches. The
challenge
seems
to be in covering all eventualities.
Not only are there
different
sources
and sinks of I/O that
you want to communicate with
(files, the
console,
network connections), but
you need to talk to them in
a wide
variety
of ways (sequential, random-access,
buffered, binary, character,
by
lines,
by words, etc.).
The
Java library designers
attacked this problem by
creating lots of
classes.
In fact, there are so many
classes for Java's I/O
system that it can
be
intimidating at first (ironically,
the Java I/O design
actually prevents
an
explosion of classes). There
was also a significant
change in the I/O
library
after Java 1.0, when
the original byte-oriented
library was
supplemented
with char-oriented,
Unicode-based I/O classes. As a
result
there
are a fair number of classes
to learn before you
understand enough
of
Java's I/O picture that
you can use it properly. In
addition, it's rather
important
to understand the evolution
history of the I/O library,
even if
your
first reaction is "don't
bother me with history, just
show me how to
use
it!" The problem is that
without the historical
perspective you will
rapidly
become confused with some of
the classes and when
you should
and
shouldn't use them.
This
chapter will give you an
introduction to the variety of
I/O classes in
the
standard Java library and
how to use them.
573

The
File
class
Before
getting into the classes
that actually read and
write data to
streams,
we'll look a utility
provided with the library to
assist you in
handling
file directory
issues.
The
File class
has a deceiving name--you
might think it refers to a
file,
but
it doesn't. It can represent
either the name
of
a particular file or
the
names
of
a set of files in a directory. If
it's a set of files, you
can ask for
the
set
with the list(
) method,
and this returns an array of
String.
It makes
sense
to return an array rather
than one of the flexible
container classes
because
the number of elements is
fixed, and if you want a
different
directory
listing you just create a
different File
object.
In fact, "FilePath"
would
have been a better name
for the class. This
section shows an
example
of the use of this class,
including the associated
FilenameFilter
interface.
A
directory lister
Suppose
you'd like to see a
directory listing. The
File object
can be listed
in
two ways. If you call
list( )
with
no arguments, you'll get the
full list
that
the File
object
contains. However, if you
want a restricted
list--for
example,
if you want all of the
files with an extension of
.java--then
you
use
a "directory filter," which is a
class that tells how to
select the File
objects
for display.
Here's
the code for the
example. Note that the
result has been
effortlessly
sorted
(alphabetically) using the
java.utils.Array.sort(
) method
and
the
AlphabeticComparator
defined
in Chapter 9:
//:
c11:DirList.java
//
Displays directory listing.
import
java.io.*;
import
java.util.*;
import
com.bruceeckel.util.*;
public
class DirList {
public
static void main(String[] args) {
File
path = new File(".");
String[]
list;
574
Thinking
in Java

if(args.length
== 0)
list
= path.list();
else
list
= path.list(new
DirFilter(args[0]));
Arrays.sort(list,
new
AlphabeticComparator());
for(int
i = 0; i < list.length; i++)
System.out.println(list[i]);
}
}
class
DirFilter implements FilenameFilter {
String
afn;
DirFilter(String
afn) { this.afn = afn; }
public
boolean accept(File dir, String name) {
//
Strip path information:
String
f = new File(name).getName();
return
f.indexOf(afn) != -1;
}
}
///:~
The
DirFilter
class
"implements" the interface
FilenameFilter.
It's
useful
to see how simple the
FilenameFilter
interface is:
public
interface FilenameFilter {
boolean
accept(File dir, String name);
}
It
says all that this
type of object does is
provide a method
called
accept(
).
The whole reason behind
the creation of this class
is to provide
the
accept( )
method
to the list(
) method
so that list(
) can
"call back"
accept(
) to
determine which file names
should be included in the
list.
Thus,
this technique is often
referred to as a callback
or
sometimes a
functor
(that
is, DirFilter
is
a functor because its only
job is to hold a
method)
or the Command
Pattern. Because
list( )
takes
a
FilenameFilter
object
as its argument, it means
that you can pass
an
object
of any class that implements
FilenameFilter
to
choose (even at
run-time)
how the list(
) method
will behave. The purpose of
a callback is
to
provide flexibility in the
behavior of code.
Chapter
11: The Java I/O
System
575

DirFilter
shows
that just because an
interface
contains
only a set of
methods,
you're not restricted to
writing only those methods.
(You must
at
least provide definitions
for all the methods in an
interface, however.)
In
this case, the DirFilter
constructor
is also created.
The
accept( )
method
must accept a File
object
representing the
directory
that a particular file is
found in, and a String
containing
the
name
of that file. You might
choose to use or ignore
either of these
arguments,
but you will probably at
least use the file
name. Remember
that
the list(
) method
is calling accept(
) for
each of the file names
in
the
directory object to see
which one should be
included--this is indicated
by
the boolean
result
returned by accept(
).
To
make sure the element
you're working with is only
the file name
and
contains
no path information, all you
have to do is take the
String
object
and
create a File
object
out of it, then call
getName(
),
which strips away
all
the path information (in a
platform-independent way). Then
accept(
)
uses
the String
class
indexOf(
) method
to see if the search string
afn
appears
anywhere in the name of the
file. If afn
is
found within the
string,
the
return value is the starting
index of afn,
but if it's not found
the return
value
is -1. Keep in mind that
this is a simple string
search and does
not
have
"glob" expression wildcard
matching--such as "fo?.b?r*"--which
is
much
more difficult to
implement.
The
list( )
method
returns an array. You can
query this array for
its
length
and then move through it
selecting the array
elements. This
ability
to
easily pass an array in and
out of a method is a
tremendous
improvement
over the behavior of C and
C++.
Anonymous
inner classes
This
example is ideal for
rewriting using an anonymous
inner class
(described
in Chapter 8). As a first
cut, a method filter(
) is
created that
returns
a reference to a FilenameFilter:
//:
c11:DirList2.java
//
Uses anonymous inner classes.
import
java.io.*;
import
java.util.*;
import
com.bruceeckel.util.*;
576
Thinking
in Java

public
class DirList2 {
public
static FilenameFilter
filter(final
String afn) {
//
Creation of anonymous inner class:
return
new FilenameFilter() {
String
fn = afn;
public
boolean accept(File dir, String n) {
//
Strip path information:
String
f = new File(n).getName();
return
f.indexOf(fn) != -1;
}
};
// End of anonymous inner class
}
public
static void main(String[] args) {
File
path = new File(".");
String[]
list;
if(args.length
== 0)
list
= path.list();
else
list
= path.list(filter(args[0]));
Arrays.sort(list,
new
AlphabeticComparator());
for(int
i = 0; i < list.length; i++)
System.out.println(list[i]);
}
}
///:~
Note
that the argument to
filter( )
must
be final.
This is required by
the
anonymous
inner class so that it can
use an object from outside
its scope.
This
design is an improvement because
the FilenameFilter
class
is now
tightly
bound to DirList2.
However, you can take
this approach one
step
further
and define the anonymous
inner class as an argument to
list(
),
in
which
case it's even
smaller:
//:
c11:DirList3.java
//
Building the anonymous inner class "in-place."
import
java.io.*;
import
java.util.*;
import
com.bruceeckel.util.*;
public
class DirList3 {
Chapter
11: The Java I/O
System
577

public
static void main(final String[] args) {
File
path = new File(".");
String[]
list;
if(args.length
== 0)
list
= path.list();
else
list
= path.list(new FilenameFilter() {
public
boolean
accept(File
dir, String n) {
String
f = new File(n).getName();
return
f.indexOf(args[0]) != -1;
}
});
Arrays.sort(list,
new
AlphabeticComparator());
for(int
i = 0; i < list.length; i++)
System.out.println(list[i]);
}
}
///:~
The
argument to main(
) is
now final,
since the anonymous inner
class
uses
args[0]
directly.
This
shows you how anonymous
inner classes allow the
creation of quick-
and-dirty
classes to solve problems.
Since everything in Java
revolves
around
classes, this can be a
useful coding technique. One
benefit is that it
keeps
the code that solves a
particular problem isolated
together in one
spot.
On the other hand, it is not
always as easy to read, so
you must use it
judiciously.
Checking
for and creating
directories
The
File class
is more than just a
representation for an existing
file or
directory.
You can also use a
File object
to create a new directory or
an
entire
directory path if it doesn't
exist. You can also
look at the
characteristics
of files (size, last
modification date, read/write),
see
whether
a File
object
represents a file or a directory,
and delete a file.
This
program shows some of the
other methods available with
the File
class
(see the HTML documentation
from java.sun.com
for
the full set):
578
Thinking
in Java

//:
c11:MakeDirectories.java
//
Demonstrates the use of the File class to
//
create directories and manipulate files.
import
java.io.*;
public
class MakeDirectories {
private
final static String usage =
"Usage:MakeDirectories
path1 ...\n" +
"Creates
each path\n" +
"Usage:MakeDirectories
-d path1 ...\n" +
"Deletes
each path\n" +
"Usage:MakeDirectories
-r path1 path2\n" +
"Renames
from path1 to path2\n";
private
static void usage() {
System.err.println(usage);
System.exit(1);
}
private
static void fileData(File f) {
System.out.println(
"Absolute
path: " + f.getAbsolutePath() +
"\n
Can read: " + f.canRead() +
"\n
Can write: " + f.canWrite() +
"\n
getName: " + f.getName() +
"\n
getParent: " + f.getParent() +
"\n
getPath: " + f.getPath() +
"\n
length: " + f.length() +
"\n
lastModified: " +
f.lastModified());
if(f.isFile())
System.out.println("it's
a file");
else
if(f.isDirectory())
System.out.println("it's
a directory");
}
public
static void main(String[] args) {
if(args.length
< 1) usage();
if(args[0].equals("-r"))
{
if(args.length
!= 3) usage();
File
old
= new File(args[1]),
rname
= new File(args[2]);
old.renameTo(rname);
fileData(old);
Chapter
11: The Java I/O
System
579

fileData(rname);
return;
// Exit main
}
int
count = 0;
boolean
del = false;
if(args[0].equals("-d"))
{
count++;
del
= true;
}
for(
; count < args.length; count++) {
File
f = new File(args[count]);
if(f.exists())
{
System.out.println(f
+ " exists");
if(del)
{
System.out.println("deleting..."
+ f);
f.delete();
}
}
else
{ // Doesn't exist
if(!del)
{
f.mkdirs();
System.out.println("created
" + f);
}
}
fileData(f);
}
}
}
///:~
In
fileData(
) you
can see various file
investigation methods used
to
display
information about the file
or directory path.
The
first method that's
exercised by main(
) is
renameTo(
),
which
allows
you to rename (or move) a
file to an entirely new path
represented
by
the argument, which is
another File
object.
This also works
with
directories
of any length.
If
you experiment with the
above program, you'll find
that you can make
a
directory
path of any complexity
because mkdirs(
) will
do all the work
for
you.
580
Thinking
in Java

Input
and output
I/O
libraries often use the
abstraction of a stream,
which represents any
data
source or sink as an object
capable of producing or receiving
pieces
of
data. The stream hides
the details of what happens
to the data inside
the
actual I/O device.
The
Java library classes for
I/O are divided by input
and output, as you
can
see by looking at the online
Java class hierarchy with
your Web
browser.
By inheritance, everything derived
from the InputStream
or
Reader
classes
have basic methods called
read( )
for
reading a single
byte
or array of bytes. Likewise,
everything derived from
OutputStream
or
Writer
classes
have basic methods called
write( )
for
writing a single
byte
or array of bytes. However,
you won't generally use
these methods;
they
exist so that other classes
can use them--these other
classes provide
a
more useful interface. Thus,
you'll rarely create your
stream object by
using
a single class, but instead
will layer multiple objects
together to
provide
your desired functionality.
The fact that you
create more than
one
object
to create a single resulting
stream is the primary reason
that Java's
stream
library is confusing.
It's
helpful to categorize the
classes by their functionality. In
Java 1.0, the
library
designers started by deciding
that all classes that
had anything to
do
with input would be
inherited from InputStream
and
all classes that
were
associated with output would
be inherited from OutputStream.
Types
of InputStream
InputStream's
job is to represent classes
that produce input
from
different
sources. These sources can
be:
1.
An
array of bytes.
2.
A
String
object.
3.
A
file.
4.
A
"pipe," which works like a
physical pipe: you put
things in one
end
and they come out
the other.
Chapter
11: The Java I/O
System
581

5.
A
sequence of other streams, so
you can collect them
together into
a
single stream.
6.
Other
sources, such as an Internet
connection. (This will
be
discussed
in a later chapter.)
Each
of these has an associated
subclass of InputStream.
In addition,
the
FilterInputStream
is
also a type of InputStream,
to provide a
base
class for "decorator"
classes that attach
attributes or useful
interfaces
to
input streams. This is
discussed later.
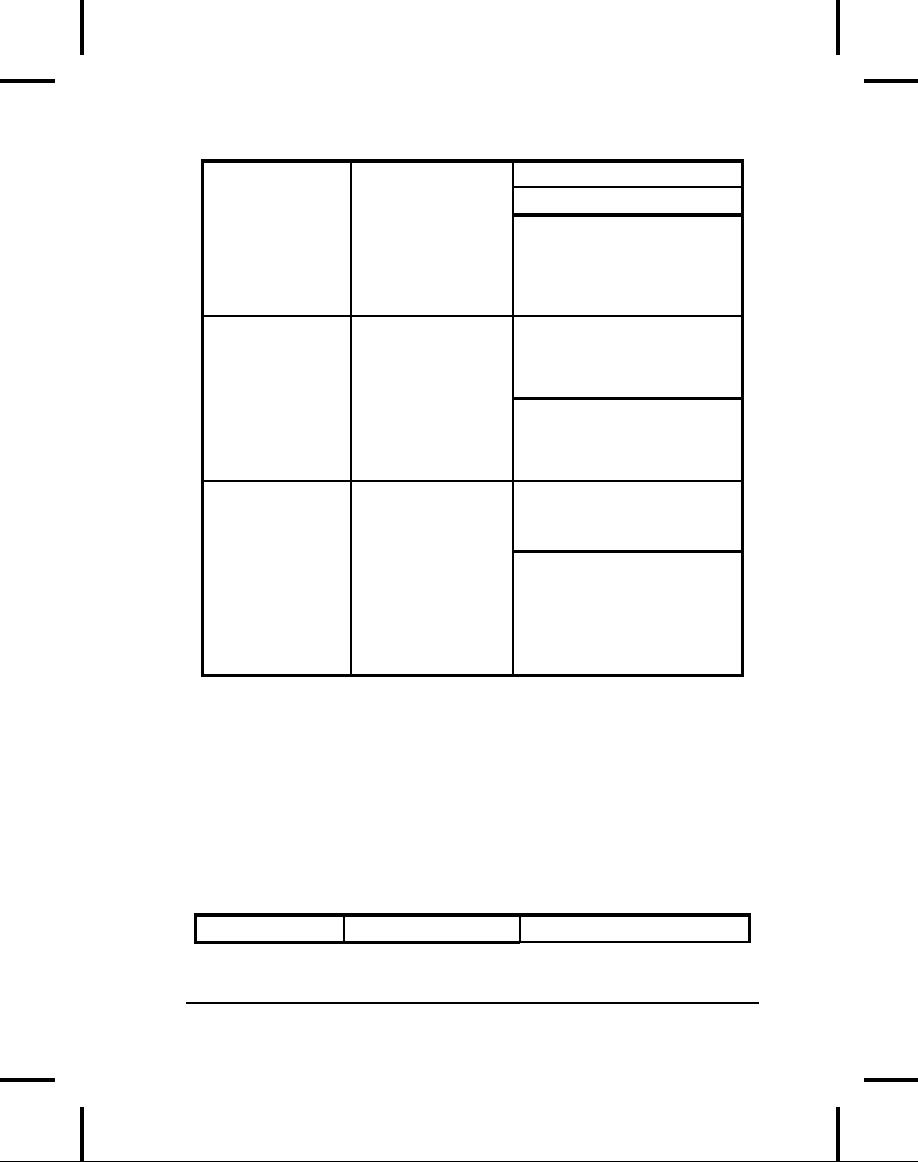
Table
11-1. Types of InputStream
Constructor
Arguments
Class
Function
How
to use it
ByteArray-
Allows
a buffer in
The
buffer from which to
InputStream
extract
the bytes.
memory
to be used
as
an
As
a source of data.
Connect
InputStream
it
to a FilterInputStream
object
to provide a useful
interface.
StringBuffer-
Converts
a String
A
String.
The underlying
InputStream
into
an
implementation
actually
InputStream
uses
a StringBuffer.
As
a source of data.
Connect
it
to a FilterInputStream
object
to provide a useful
interface.
File-
For
reading
A
String
representing
the
InputStream
information
from
file
name, or a File
or
a
file
FileDescriptor
object.
As
a source of data.
Connect
it
to a FilterInputStream
object
to provide a useful
interface.
Piped-
Produces
the data
PipedOutputStream
InputStream
that's
being
written
to the
582
Thinking
in Java
Class
Function
Constructor
Arguments
How
to use it
associated
As
a source of data in
PipedOutput-
multithreading.
Connect it
Stream.
to
a FilterInputStream
Implements
the
object
to provide a useful
"piping"
concept.
interface.
Sequence-
Converts
two or
Two
InputStream
objects
InputStream
more
or
an Enumeration
for
a
InputStream
container
of InputStream
objects.
objects
into a
single
As
a source of data.
Connect
InputStream.
it
to a FilterInputStream
object
to provide a useful
interface.
Filter-
Abstract
class
See
Table 11-3.
InputStream
which
is an
interface
for
decorators
that
See
Table 11-3.
provide
useful
functionality
to the
other
InputStream
classes.
See Table
11-3.
Types
of OutputStream
This
category includes the
classes that decide where
your output will
go:
an
array of bytes (no String,
however; presumably you can
create one
using
the array of bytes), a file,
or a "pipe."
In
addition, the FilterOutputStream
provides
a base class for
"decorator"
classes that attach
attributes or useful interfaces to
output
streams.
This is discussed
later.
Table
11-2. Types of OutputStream
Class
Function
Constructor
Arguments
Chapter
11: The Java I/O
System
583
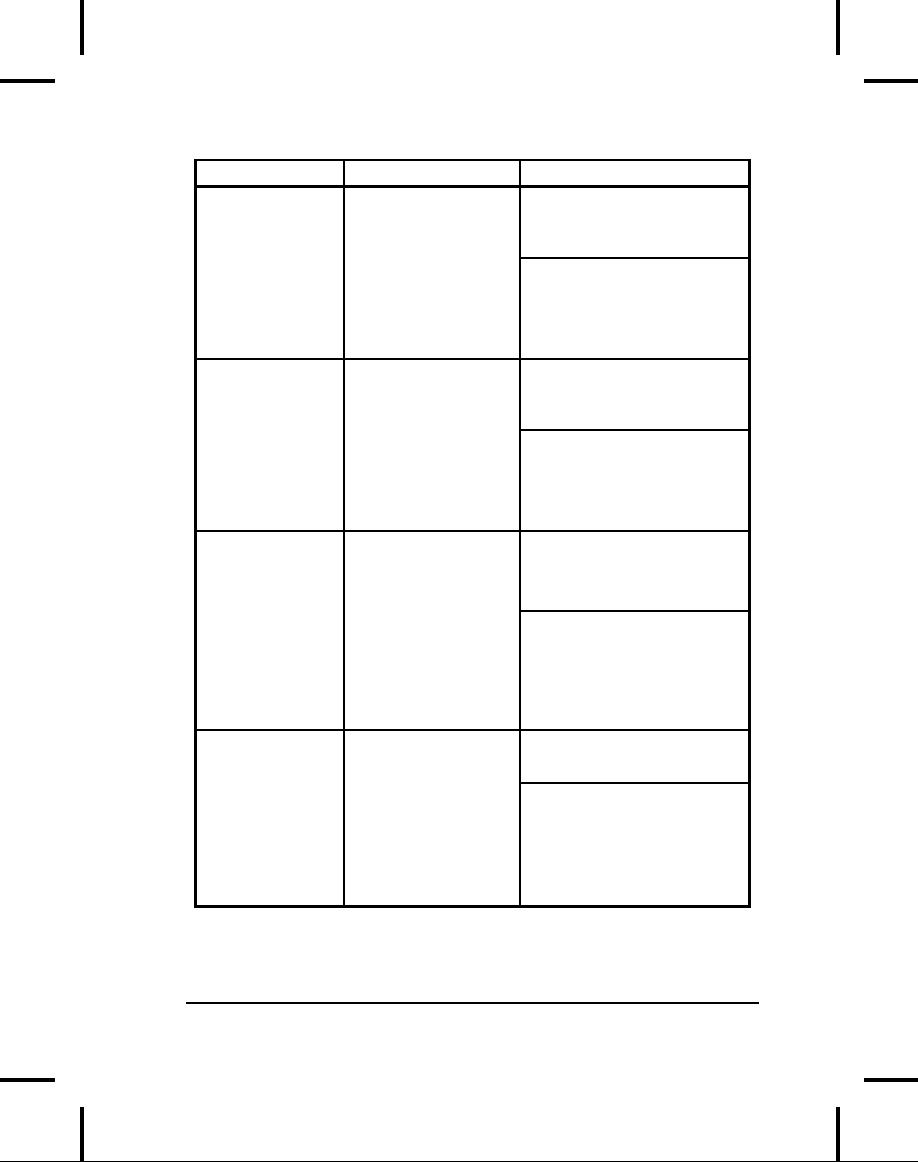
How
to use it
ByteArray-
Creates
a buffer in
Optional
initial size of the
OutputStream
buffer.
memory.
All the
data
that you send to
the
stream is placed
To
designate the
destination
in
this buffer.
of
your data. Connect it to
a
FilterOutputStream
object
to provide a useful
interface.
File-
For
sending
A
String representing
the
OutputStream
information
to a file.
file
name, or a File
or
FileDescriptor
object.
To
designate the
destination
of
your data. Connect it to
a
FilterOutputStream
object
to provide a useful
interface.
Piped-
Any
information you
PipedInputStream
OutputStream
write
to this
automatically
ends
up
as input for the
associated
To
designate the
destination
PipedInput-
of
your data for
Stream.
multithreading.
Connect it
Implements
the
to
a FilterOutputStream
"piping"
concept.
object
to provide a useful
interface.
Filter-
Abstract
class which
See
Table 11-4.
OutputStream
is
an interface for
decorators
that
See
Table 11-4.
provide
useful
functionality
to the
other
OutputStream
classes.
See Table 11-
4.
584
Thinking
in Java

Adding
attributes
and
useful interfaces
The
use of layered objects to
dynamically and transparently
add
responsibilities
to individual objects is referred to as
the Decorator
pattern.
(Patterns1 are the subject of
Thinking
in Patterns with Java,
downloadable
at .)
The decorator pattern
specifies
that
all objects that wrap
around your initial object
have the same
interface.
This makes the basic
use of the decorators
transparent--you
send
the same message to an
object whether it's been
decorated or not.
This
is the reason for the
existence of the "filter"
classes in the Java
I/O
library:
the abstract "filter" class
is the base class for
all the decorators.
(A
decorator
must have the same
interface as the object it
decorates, but the
decorator
can also extend the
interface, which occurs in
several of the
"filter"
classes).
Decorators
are often used when
simple subclassing results in a
large
number
of subclasses in order to satisfy
every possible combination
that is
needed--so
many subclasses that it
becomes impractical. The
Java I/O
library
requires many different
combinations of features, which is
why the
decorator
pattern is used. There is a
drawback to the decorator
pattern,
however.
Decorators give you much
more flexibility while
you're writing a
program
(since you can easily
mix and match attributes),
but they add
complexity
to your code. The reason
that the Java I/O
library is awkward
to
use is that you must
create many classes--the
"core" I/O type plus
all
the
decorators--in order to get
the single I/O object
that you want.
The
classes that provide the
decorator interface to control a
particular
InputStream
or
OutputStream
are
the FilterInputStream
and
FilterOutputStream--which
don't have very intuitive
names.
FilterInputStream
and
FilterOutputStream
are
abstract classes that
are
derived from the base
classes of the I/O library,
InputStream
and
OutputStream,
which is the key requirement
of the decorator (so that
it
1
Design
Patterns, Erich Gamma
et
al.,
Addison-Wesley 1995.
Chapter
11: The Java I/O
System
585

provides
the common interface to all
the objects that are
being
decorated).
Reading
from an InputStream
with
FilterInputStream
The
FilterInputStream
classes
accomplish two significantly
different
things.
DataInputStream
allows
you to read different types
of primitive
data
as well as String
objects.
(All the methods start
with "read," such as
readByte(
),
readFloat(
),
etc.) This, along with
its companion
DataOutputStream,
allows you to move primitive
data from one
place
to
another via a stream. These
"places" are determined by
the classes in
Table
11-1.
The
remaining classes modify the
way an InputStream
behaves
internally:
whether it's buffered or
unbuffered, if it keeps track of
the lines
it's
reading (allowing you to ask
for line numbers or set
the line number),
and
whether you can push
back a single character. The
last two classes
look
a lot like support for
building a compiler (that
is, they were added
to
support
the construction of the Java
compiler), so you probably
won't use
them
in general programming.
You'll
probably need to buffer your
input almost every time,
regardless of
the
I/O device you're connecting
to, so it would have made
more sense for
the
I/O library to make a
special case (or simply a
method call) for
unbuffered
input rather than buffered
input.
Table
11-3. Types of
FilterInputStream
Constructor
Class
Function
Arguments
How
to use it
Data-
Used
in concert with
InputStream
InputStream
DataOutputStream,
so
you can read
primitives
(int,
char,
Contains
a full
long,
etc.) from a
interface
to allow you
stream
in a portable
to
read primitive types.
fashion.
586
Thinking
in Java

Buffered-
Use
this to prevent a
InputStream,
with
InputStream
physical
read every time
optional
buffer size.
you
want more data.
This
doesn't provide an
You're
saying "Use a
interface
per
se,
just a
buffer."
requirement
that a
buffer
be used. Attach
an
interface object.
LineNumber-
Keeps
track of line
InputStream
InputStream
numbers
in the input
stream;
you can call
getLineNumber(
)
This
just adds line
and
setLineNumber(
numbering,
so you'll
int).
probably
attach an
interface
object.
Pushback-
Has
a one byte push-
InputStream
InputStream
back
buffer so that you
can
push back the
last
character
read.
Generally
used in the
scanner
for a compiler
and
probably included
because
the Java
compiler
needed it. You
probably
won't use this.
Writing
to an OutputStream
with
FilterOutputStream
The
complement to DataInputStream
is
DataOutputStream,
which
formats
each of the primitive types
and String
objects
onto a stream in
such
a way that any DataInputStream,
on any machine, can read
them.
All
the methods start with
"write," such as writeByte(
),
writeFloat(
),
etc.
The
original intent of PrintStream
was
to print all of the
primitive data
types
and String
objects
in a viewable format. This is
different from
DataOutputStream,
whose goal is to put data
elements on a stream in a
way
that DataInputStream
can
portably reconstruct
them.
Chapter
11: The Java I/O
System
587

The
two important methods in
PrintStream
are
print( )
and
println(
),
which are overloaded to
print all the various
types. The
difference
between print(
) and
println( )
is
that the latter adds
a
newline
when it's done.
PrintStream
can
be problematic because it traps
all IOExceptions
(You
must explicitly test the
error status with checkError(
),
which
returns
true if
an error has occurred).
Also, PrintStream
doesn't
internationalize
properly and doesn't handle
line breaks in a
platform
independent
way (these problems are
solved with PrintWriter).
BufferedOutputStream
is
a modifier and tells the
stream to use
buffering
so you don't get a physical
write every time you
write to the
stream.
You'll probably always want
to use this with files,
and possibly
console
I/O.
Table
11-4. Types of
FilterOutputStream
Class
Function
Constructor
Arguments
How
to use it
Data-
Used
in concert with
OutputStream
OutputStream
DataInputStream
so
you
can write
primitives
(int, char,
Contains
full
long,
etc.) to a stream
interface
to allow you
in
a portable fashion.
to
write primitive
types.
PrintStream
For
producing
OutputStream,
formatted
output.
with
optional
While
boolean
indicating
DataOutputStream
that
the buffer is
handles
the storage
of
flushed
with every
newline.
data,
PrintStream
handles
display.
Should
be the "final"
wrapping
for your
OutputStream
object.
You'll
probably
use this a
lot.
588
Thinking
in Java
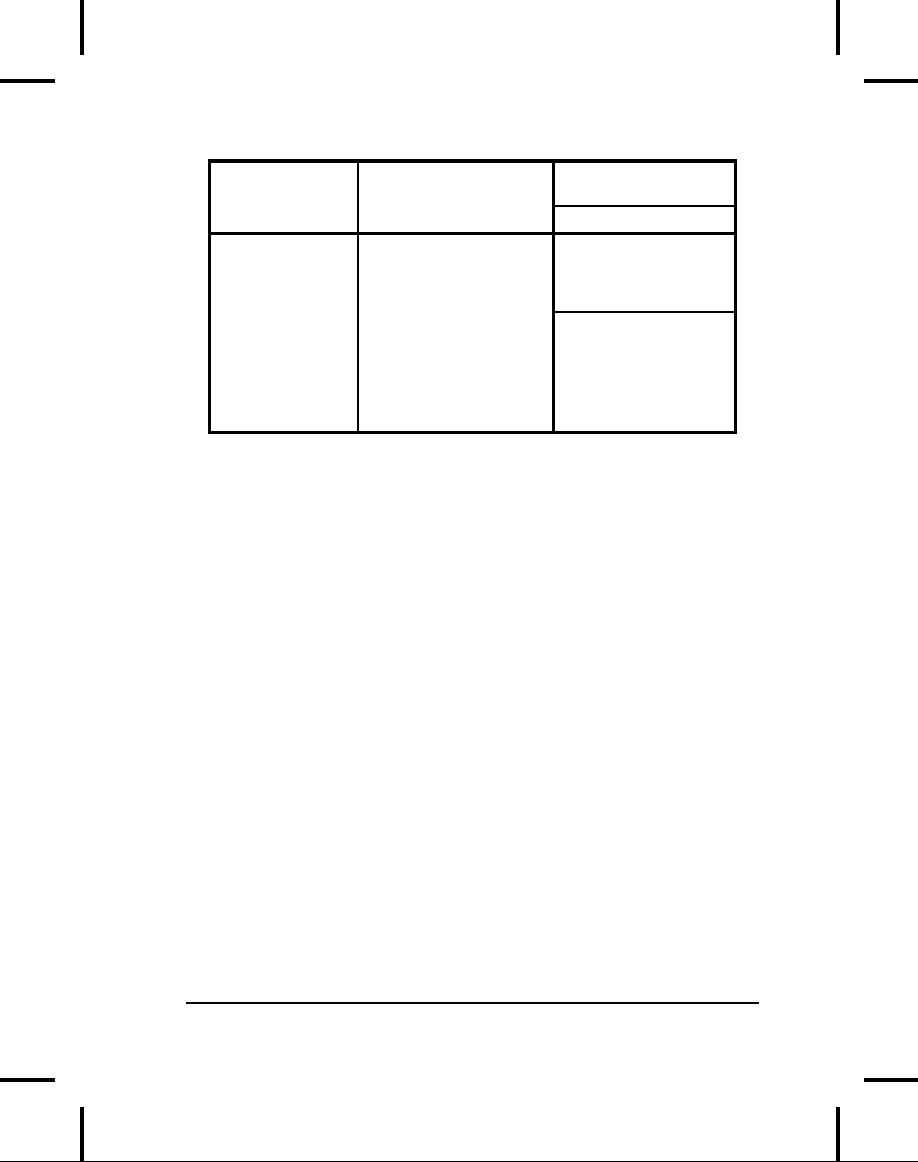
Class
Function
Constructor
Arguments
How
to use it
Buffered-
Use
this to prevent a
OutputStream,
OutputStream
physical
write every
with
optional buffer
time
you send a piece
size.
of
data. You're saying
"Use
a buffer." You can
This
doesn't provide
call
flush( )
to
flush
an
interface per
se,
the
buffer.
just
a requirement
that
a buffer is used.
Attach
an interface
object.
Readers
& Writers
Java
1.1 made some significant
modifications to the fundamental
I/O
stream
library (Java 2, however,
did not make
fundamental
modifications).
When you see the
Reader
and
Writer
classes
your first
thought
(like mine) might be that
these were meant to replace
the
InputStream
and
OutputStream
classes.
But that's not the
case.
Although
some aspects of the original
streams library are
deprecated (if
you
use them you will
receive a warning from the
compiler), the
InputStream
and
OutputStream
classes
still provide
valuable
functionality
in the form of byte-oriented
I/O, while the Reader
and
Writer
classes
provide Unicode-compliant,
character-based I/O. In
addition:
1.
Java
1.1 added new classes
into the InputStream
and
OutputStream
hierarchy,
so it's obvious those
classes weren't
being
replaced.
2.
There
are times when you
must use classes from
the "byte"
hierarchy
in
combination with
classes in the "character"
hierarchy.
To
accomplish this there are
"bridge" classes:
InputStreamReader
converts
an InputStream
to
a Reader
and
OutputStreamWriter
converts
an OutputStream
to
a
Writer.
Chapter
11: The Java I/O
System
589
The
most important reason for
the Reader
and
Writer
hierarchies
is for
internationalization.
The old I/O stream
hierarchy supports only
8-bit
byte
streams and doesn't handle
the 16-bit Unicode
characters well.
Since
Unicode
is used for internationalization
(and Java's native char is
16-bit
Unicode),
the Reader
and
Writer
hierarchies
were added to support
Unicode
in all I/O operations. In
addition, the new libraries
are designed
for
faster operations than the
old.
As
is the practice in this
book, I will attempt to
provide an overview of
the
classes,
but assume that you
will use online
documentation to determine
all
the details, such as the
exhaustive list of
methods.
Sources
and sinks of data
Almost
all of the original Java
I/O stream classes have
corresponding
Reader
and
Writer
classes
to provide native Unicode
manipulation.
However,
there are some places
where the byte-oriented
InputStreams
and
OutputStreams
are the correct solution; in
particular, the
java.util.zip
libraries
are byte-oriented
rather than char-oriented.
So
the
most sensible approach to
take is to try
to
use the Reader
and
Writer
classes
whenever you can, and
you'll discover the
situations when
you
have to use the byte-oriented
libraries because your code
won't
compile.
Here
is a table that shows the
correspondence between the
sources and
sinks
of information (that is,
where the data physically
comes from or
goes
to) in the two
hierarchies.
Sources
& Sinks:
Corresponding
Java 1.1 class
Java
1.0 class
InputStream
Reader
converter:
InputStreamReader
OutputStream
Writer
converter:
OutputStreamWriter
FileInputStream
FileReader
FileOutputStream
FileWriter
StringBufferInputStream
StringReader
590
Thinking
in Java
(no
corresponding class)
StringWriter
ByteArrayInputStream
CharArrayReader
ByteArrayOutputStream
CharArrayWriter
PipedInputStream
PipedReader
PipedOutputStream
PipedWriter
In
general, you'll find that
the interfaces for the
two different
hierarchies
are
similar if not
identical.
Modifying
stream behavior
For
InputStreams
and OutputStreams,
streams were adapted
for
particular
needs using "decorator"
subclasses of FilterInputStream
and
FilterOutputStream.
The
Reader
and
Writer
class
hierarchies
continue
the use of this idea--but
not exactly.
In
the following table, the
correspondence is a rougher
approximation
than
in the previous table. The
difference is because of the
class
organization:
while BufferedOutputStream
is
a subclass of
FilterOutputStream,
BufferedWriter
is
not
a
subclass of
FilterWriter
(which,
even though it is abstract,
has no subclasses and
so
appears to have been put in
either as a placeholder or simply so
you
wouldn't
wonder where it was).
However, the interfaces to
the classes are
quite
a close match.
Filters:
Corresponding
Java 1.1 class
Java
1.0 class
FilterInputStream
FilterReader
FilterOutputStream
FilterWriter
(abstract
class with
no
subclasses)
BufferedInputStream
BufferedReader
(also
has readLine(
))
BufferedOutputStream
BufferedWriter
DataInputStream
Use
DataInputStream
(Except
when you need to
use
readLine(
),
when you should
use
a
BufferedReader)
Chapter
11: The Java I/O
System
591
Filters:
Corresponding
Java 1.1 class
Java
1.0 class
PrintStream
PrintWriter
LineNumberInputStream
LineNumberReader
StreamTokenizer
StreamTokenizer
(use
constructor that takes
a
Reader
instead)
PushBackInputStream
PushBackReader
There's
one direction that's quite
clear: Whenever you want to
use
readLine(
),
you shouldn't do it with a
DataInputStream
any
more
(this
is met with a deprecation
message at compile-time), but
instead use
a
BufferedReader.
Other than this, DataInputStream
is
still a
"preferred"
member of the I/O
library.
To
make the transition to using
a PrintWriter
easier,
it has constructors
that
take any OutputStream
object,
as well as Writer
objects.
However,
PrintWriter
has
no more support for
formatting than PrintStream
does;
the interfaces are virtually
the same.
The
PrintWriter
constructor
also has an option to
perform automatic
flushing,
which happens after every
println( )
if
the constructor flag
is
set.
Unchanged
Classes
Some
classes were left unchanged
between Java 1.0 and
Java 1.1:
Java
1.0 classes without
corresponding
Java 1.1 classes
DataOutputStream
File
RandomAccessFile
SequenceInputStream
DataOutputStream,
in particular, is used without
change, so for
storing
and
retrieving data in a transportable
format you use the
InputStream
and
OutputStream
hierarchies.
592
Thinking
in Java

Off
by itself:
RandomAccessFile
RandomAccessFile
is
used for files containing
records of known size
so
that
you can move from
one record to another using
seek(
),
then read or
change
the records. The records
don't have to be the same
size; you just
have
to be able to determine how
big they are and
where they are
placed
in
the file.
At
first it's a little bit
hard to believe that
RandomAccessFile
is
not part
of
the InputStream
or
OutputStream
hierarchy.
However, it has no
association
with those hierarchies other
than that it happens
to
implement
the DataInput
and
DataOutput
interfaces
(which are also
implemented
by DataInputStream
and
DataOutputStream).
It
doesn't
even use any of the
functionality of the existing
InputStream
or
OutputStream
classes--it's
a completely separate class,
written from
scratch,
with all of its own
(mostly native) methods. The
reason for this
may
be that RandomAccessFile
has
essentially different behavior
than
the
other I/O types, since
you can move forward
and backward within a
file.
In any event, it stands
alone, as a direct descendant of
Object.
Essentially,
a RandomAccessFile
works
like a DataInputStream
pasted
together with a DataOutputStream,
along with the
methods
getFilePointer(
) to
find out where you
are in the file, seek( )
to
move
to
a new point in the file,
and length(
) to
determine the maximum
size
of
the file. In addition, the
constructors require a second
argument
(identical
to fopen(
) in
C) indicating whether you
are just randomly
reading
("r")
or reading and writing
("rw").
There's no support for
write-
only
files, which could suggest
that RandomAccessFile
might
have
worked
well if it were inherited
from DataInputStream.
The
seeking methods are
available only in RandomAccessFile,
which
works
for files only. BufferedInputStream
does
allow you to mark(
)
a
position (whose value is
held in a single internal
variable) and reset(
)
to
that position, but this is
limited and not very
useful.
Chapter
11: The Java I/O
System
593

Typical
uses of I/O
streams
Although
you can combine the
I/O stream classes in many
different ways,
you'll
probably just use a few
combinations. The following
example can be
used
as a basic reference; it shows
the creation and use of
typical I/O
configurations.
Note that each configuration
begins with a
commented
number
and title that corresponds
to the heading for the
appropriate
explanation
that follows in the
text.
//:
c11:IOStreamDemo.java
//
Typical I/O stream configurations.
import
java.io.*;
public
class IOStreamDemo {
//
Throw exceptions to console:
public
static void main(String[] args)
throws
IOException {
//
1. Reading input by lines:
BufferedReader
in =
new
BufferedReader(
new
FileReader("IOStreamDemo.java"));
String
s, s2 = new String();
while((s
= in.readLine())!= null)
s2
+= s + "\n";
in.close();
//
1b. Reading standard input:
BufferedReader
stdin =
new
BufferedReader(
new
InputStreamReader(System.in));
System.out.print("Enter
a line:");
System.out.println(stdin.readLine());
//
2. Input from memory
StringReader
in2 = new StringReader(s2);
int
c;
while((c
= in2.read()) != -1)
594
Thinking
in Java

System.out.print((char)c);
//
3. Formatted memory input
try
{
DataInputStream
in3 =
new
DataInputStream(
new
ByteArrayInputStream(s2.getBytes()));
while(true)
System.out.print((char)in3.readByte());
}
catch(EOFException e) {
System.err.println("End
of stream");
}
//
4. File output
try
{
BufferedReader
in4 =
new
BufferedReader(
new
StringReader(s2));
PrintWriter
out1 =
new
PrintWriter(
new
BufferedWriter(
new
FileWriter("IODemo.out")));
int
lineCount = 1;
while((s
= in4.readLine()) != null )
out1.println(lineCount++
+ ": " + s);
out1.close();
}
catch(EOFException e) {
System.err.println("End
of stream");
}
//
5. Storing & recovering data
try
{
DataOutputStream
out2 =
new
DataOutputStream(
new
BufferedOutputStream(
new
FileOutputStream("Data.txt")));
out2.writeDouble(3.14159);
out2.writeChars("That
was pi\n");
out2.writeBytes("That
was pi\n");
out2.close();
DataInputStream
in5 =
Chapter
11: The Java I/O
System
595

new
DataInputStream(
new
BufferedInputStream(
new
FileInputStream("Data.txt")));
BufferedReader
in5br =
new
BufferedReader(
new
InputStreamReader(in5));
//
Must use DataInputStream for data:
System.out.println(in5.readDouble());
//
Can now use the "proper" readLine():
System.out.println(in5br.readLine());
//
But the line comes out funny.
//
The one created with writeBytes is OK:
System.out.println(in5br.readLine());
}
catch(EOFException e) {
System.err.println("End
of stream");
}
//
6. Reading/writing random access files
RandomAccessFile
rf =
new
RandomAccessFile("rtest.dat", "rw");
for(int
i = 0; i < 10; i++)
rf.writeDouble(i*1.414);
rf.close();
rf
=
new
RandomAccessFile("rtest.dat", "rw");
rf.seek(5*8);
rf.writeDouble(47.0001);
rf.close();
rf
=
new
RandomAccessFile("rtest.dat", "r");
for(int
i = 0; i < 10; i++)
System.out.println(
"Value
" + i + ": " +
rf.readDouble());
rf.close();
}
}
///:~
Here
are the descriptions for
the numbered sections of the
program:
596
Thinking
in Java

Input
streams
Parts
1 through 4 demonstrate the
creation and use of input
streams. Part
4
also shows the simple
use of an output
stream.
1.
Buffered input file
To
open a file for character
input, you use a FileInputReader
with
a
String
or
a File
object
as the file name. For
speed, you'll want that
file to
be
buffered so you give the
resulting reference to the
constructor for a
BufferedReader.
Since BufferedReader
also
provides the
readLine(
) method,
this is your final object
and the interface you
read
from.
When you reach the
end of the file, readLine(
) returns
null so
that
is used to break out of the
while loop.
The
String s2
is
used to accumulate the
entire contents of the
file
(including
newlines that must be added
since readLine(
) strips
them
off).
s2 is
then used in the later
portions of this program.
Finally, close(
)
is
called to close the file.
Technically, close(
) will
be called when
finalize(
) runs,
and this is supposed to
happen (whether or not
garbage
collection
occurs) as the program
exits. However, this has
been
inconsistently
implemented, so the only
safe approach is to explicitly
call
close(
) for
files.
Section
1b shows how you can
wrap System.in
for
reading console
input.
System.in
is
a DataInputStream
and
BufferedReader
needs
a
Reader
argument,
so InputStreamReader
is
brought in to perform
the
translation.
2.
Input from memory
This
section takes the String s2
that
now contains the entire
contents of
the
file and uses it to create a
StringReader.
Then read(
) is
used to
read
each character one at a time
and send it out to the
console. Note that
read(
) returns
the next byte as an
int and
thus it must be cast to a
char
to
print properly.
3.
Formatted memory input
To
read "formatted" data, you
use a DataInputStream,
which is a byte-
oriented
I/O class (rather than
char oriented).
Thus you must use
all
Chapter
11: The Java I/O
System
597

InputStream
classes
rather than Reader
classes.
Of course, you can
read
anything (such as a file) as
bytes using InputStream
classes,
but
here
a String
is
used. To convert the
String
to
an array of bytes, which
is
what
is appropriate for a ByteArrayInputStream,
String
has
a
getBytes(
) method
to do the job. At that
point, you have an
appropriate
InputStream
to
hand to DataInputStream.
If
you read the characters
from a DataInputStream
one
byte at a time
using
readByte(
),
any byte value is a
legitimate result so the
return
value
cannot be used to detect the
end of input. Instead, you
can use the
available(
) method
to find out how many
more characters are
available.
Here's
an example that shows how to
read a file one byte at a
time:
//:
c11:TestEOF.java
//
Testing for the end of file
//
while reading a byte at a time.
import
java.io.*;
public
class TestEOF {
//
Throw exceptions to console:
public
static void main(String[] args)
throws
IOException {
DataInputStream
in =
new
DataInputStream(
new
BufferedInputStream(
new
FileInputStream("TestEof.java")));
while(in.available()
!= 0)
System.out.print((char)in.readByte());
}
}
///:~
Note
that available(
) works
differently depending on what
sort of
medium
you're reading from; it's
literally "the number of
bytes that can be
read
without
blocking." With a
file this means the
whole file, but with
a
different
kind of stream this might
not be true, so use it
thoughtfully.
You
could also detect the
end of input in cases like
these by catching an
exception.
However, the use of
exceptions for control flow
is considered a
misuse
of that feature.
598
Thinking
in Java

4.
File output
This
example also shows how to
write data to a file. First,
a FileWriter
is
created
to connect to the file.
You'll virtually always want
to buffer the
output
by wrapping it in a BufferedWriter
(try
removing this
wrapping
to
see the impact on the
performance--buffering tends to
dramatically
increase
performance of I/O operations).
Then for the formatting
it's
turned
into a PrintWriter.
The data file created
this way is readable
as
an
ordinary text file.
As
the lines are written to
the file, line numbers
are added. Note
that
LineNumberInputStream
is
not
used,
because it's a silly class
and you
don't
need it. As shown here,
it's trivial to keep track
of your own line
numbers.
When
the input stream is
exhausted, readLine(
) returns
null.
You'll see
an
explicit close(
) for
out1,
because if you don't call
close( )
for
all your
output
files, you might discover
that the buffers don't
get flushed so
they're
incomplete.
Output
streams
The
two primary kinds of output
streams are separated by the
way they
write
data: one writes it for
human consumption, and the
other writes it
to
be reacquired by a DataInputStream.
The RandomAccessFile
stands
alone, although its data
format is compatible with
the
DataInputStream
and
DataOutputStream.
5.
Storing and recovering
data
A
PrintWriter
formats
data so it's readable by a
human. However, to
output
data so that it can be
recovered by another stream,
you use a
DataOutputStream
to
write the data and a
DataInputStream
to
recover
the data. Of course, these
streams could be anything,
but here a
file
is used, buffered for both
reading and writing.
DataOutputStream
and
DataInputStream
are
byte-oriented
and thus require
the
InputStreams
and OutputStreams.
If
you use a DataOutputStream
to
write the data, then
Java guarantees
that
you can accurately recover
the data using a DataInputStream--
Chapter
11: The Java I/O
System
599

regardless
of what different platforms
write and read the
data. This is
incredibly
valuable, as anyone knows
who has spent time
worrying about
platform-specific
data issues. That problem
vanishes if you have Java
on
both
platforms2.
Note
that the character string is
written using both writeChars(
) and
writeBytes(
).
When you run the
program, you'll discover
that
writeChars(
) outputs
16-bit Unicode characters.
When you read
the
line
using readLine(
),
you'll see that there is a
space between each
character,
because of the extra byte
inserted by Unicode. Since
there is no
complementary
"readChars" method in DataInputStream,
you're stuck
pulling
these characters off one at
a time with readChar(
).
So for ASCII,
it's
easier to write the
characters as bytes followed by a
newline; then use
readLine(
) to
read back the bytes as a
regular ASCII line.
The
writeDouble(
) stores
the double
number
to the stream and
the
complementary
readDouble(
) recovers
it (there are similar
methods for
reading
and writing the other
types). But for any of
the reading methods
to
work correctly, you must
know the exact placement of
the data item in
the
stream, since it would be
equally possible to read the
stored double
as
a simple sequence of bytes, or as a
char,
etc. So you must either
have a
fixed
format for the data in
the file or extra
information must be stored
in
the
file that you parse to
determine where the data is
located.
6.
Reading and writing random
access files
As
previously noted, the
RandomAccessFile
is
almost totally
isolated
from
the rest of the I/O
hierarchy, save for the
fact that it implements
the
DataInput
and
DataOutput
interfaces.
So you cannot combine it
with
any
of the aspects of the
InputStream
and
OutputStream
subclasses.
Even
though it might make sense
to treat a ByteArrayInputStream
as
a
random access element, you
can use RandomAccessFile
to
only open
a
file. You must assume a
RandomAccessFile
is
properly buffered
since
you
cannot add that.
2
XML is another
way to solve the problem of moving data
across different
computing
platforms,
and does not depend on
having Java on all
platforms. However, Java
tools exist
that
support XML.
600
Thinking
in Java

The
one option you have is in
the second constructor
argument: you can
open
a RandomAccessFile
to
read ("r")
or read and write ("rw").
Using
a RandomAccessFile
is
like using a combined
DataInputStream
and
DataOutputStream
(because
it implements
the
equivalent interfaces). In addition,
you can see that
seek( )
is
used to
move
about in the file and
change one of the
values.
A
bug?
If
you look at section 5,
you'll see that the
data is written before
the
text.
That's
because a problem was
introduced in Java 1.1 (and
persists in Java
2)
that sure seems like a
bug to me, but I reported it
and the bug people
at
JavaSoft
said that this is the
way it is supposed to work
(however, the
problem
did not
occur
in Java 1.0, which makes me
suspicious). The
problem
is shown in the following
code:
//:
c11:IOProblem.java
//
Java 1.1 and higher I/O Problem.
import
java.io.*;
public
class IOProblem {
//
Throw exceptions to console:
public
static void main(String[] args)
throws
IOException {
DataOutputStream
out =
new
DataOutputStream(
new
BufferedOutputStream(
new
FileOutputStream("Data.txt")));
out.writeDouble(3.14159);
out.writeBytes("That
was the value of pi\n");
out.writeBytes("This
is pi/2:\n");
out.writeDouble(3.14159/2);
out.close();
DataInputStream
in =
new
DataInputStream(
new
BufferedInputStream(
new
FileInputStream("Data.txt")));
BufferedReader
inbr =
new
BufferedReader(
Chapter
11: The Java I/O
System
601

new
InputStreamReader(in));
//
The doubles written BEFORE the line of text
//
read back correctly:
System.out.println(in.readDouble());
//
Read the lines of text:
System.out.println(inbr.readLine());
System.out.println(inbr.readLine());
//
Trying to read the doubles after the line
//
produces an end-of-file exception:
System.out.println(in.readDouble());
}
}
///:~
It
appears that anything you
write after a call to
writeBytes(
) is
not
recoverable.
The answer is apparently the
same as the answer to the
old
vaudeville
joke: "Doc, it hurts when I
do this!" "Don't do
that!"
Piped
streams
The
PipedInputStream,
PipedOutputStream,
PipedReader
and
PipedWriter
have
been mentioned only briefly
in this chapter. This
is
not
to suggest that they aren't
useful, but their value is
not apparent until
you
begin to understand multithreading,
since the piped streams
are used
to
communicate between threads.
This is covered along with
an example
in
Chapter 14.
Standard
I/O
The
term standard
I/O refers
to the Unix concept (which
is reproduced in
some
form in Windows and many
other operating systems) of a
single
stream
of information that is used by a
program. All the program's
input
can
come from standard
input, all
its output can go to
standard
output,
and
all of its error messages
can be sent to standard
error. The
value of
standard
I/O is that programs can
easily be chained together
and one
program's
standard output can become
the standard input for
another
program.
This is a powerful
tool.
602
Thinking
in Java

Reading
from standard input
Following
the standard I/O model,
Java has System.in,
System.out,
and
System.err.
Throughout this book you've
seen how to write to
standard
output using System.out,
which
is already prewrapped as a
PrintStream
object.
System.err
is
likewise a PrintStream,
but
System.in
is
a raw InputStream,
with no wrapping. This means
that
while
you can use System.out
and
System.err
right
away, System.in
must
be wrapped before you can
read from it.
Typically,
you'll want to read input a
line at a time using
readLine(
),
so
you'll
want to wrap System.in
in
a BufferedReader.
To do this, you
must
convert System.in
to
a Reader
using
InputStreamReader.
Here's
an example that simply
echoes each line that
you type in:
//:
c11:Echo.java
//
How to read from standard input.
import
java.io.*;
public
class Echo {
public
static void main(String[] args)
throws
IOException {
BufferedReader
in =
new
BufferedReader(
new
InputStreamReader(System.in));
String
s;
while((s
= in.readLine()).length() != 0)
System.out.println(s);
//
An empty line terminates the program
}
}
///:~
The
reason for the exception
specification is that readLine(
) can
throw
an
IOException.
Note that System.in
should
usually be buffered, as
with
most streams.
Chapter
11: The Java I/O
System
603

Changing
System.out to
a
PrintWriter
System.out
is
a PrintStream,
which is an OutputStream.
PrintWriter
has
a constructor that takes an
OutputStream
as
an
argument.
Thus, if you want you
can convert System.out
into
a
PrintWriter
using
that constructor:
//:
c11:ChangeSystemOut.java
//
Turn System.out into a PrintWriter.
import
java.io.*;
public
class ChangeSystemOut {
public
static void main(String[] args) {
PrintWriter
out =
new
PrintWriter(System.out, true);
out.println("Hello,
world");
}
}
///:~
It's
important to use the
two-argument version of the
PrintWriter
constructor
and to set the second
argument to true
in
order to enable
automatic
flushing, otherwise you may
not see the
output.
Redirecting
standard I/O
The
Java System
class
allows you to redirect the
standard input,
output,
and
error I/O streams using
simple static method
calls:
setIn(InputStream)
setOut(PrintStream)
setErr(PrintStream)
Redirecting
output is especially useful if
you suddenly start creating
a
large
amount of output on your
screen and it's scrolling
past faster than
you
can read it.3 Redirecting input is
valuable for a
command-line
3
Chapter 13
shows an even more convenient
solution for this: a GUI
program with a
scrolling
text area.
604
Thinking
in Java

program
in which you want to test a
particular user-input
sequence
repeatedly.
Here's a simple example that
shows the use of these
methods:
//:
c11:Redirecting.java
//
Demonstrates standard I/O
redirection.
import
java.io.*;
class
Redirecting {
//
Throw exceptions to console:
public
static void main(String[] args)
throws
IOException {
BufferedInputStream
in =
new
BufferedInputStream(
new
FileInputStream(
"Redirecting.java"));
PrintStream
out =
new
PrintStream(
new
BufferedOutputStream(
new
FileOutputStream("test.out")));
System.setIn(in);
System.setOut(out);
System.setErr(out);
BufferedReader
br =
new
BufferedReader(
new
InputStreamReader(System.in));
String
s;
while((s
= br.readLine()) != null)
System.out.println(s);
out.close();
// Remember this!
}
}
///:~
This
program attaches standard
input to a file, and
redirects standard
output
and standard error to
another file.
I/O
redirection manipulates streams of
bytes, not streams of
characters,
thus
InputStreams
and OutputStreams
are used rather
than
Readers
and Writers.
Chapter
11: The Java I/O
System
605

Compression
The
Java I/O library contains
classes to support reading
and writing
streams
in a compressed format. These
are wrapped around existing
I/O
classes
to provide compression
functionality.
These
classes are not derived
from the Reader
and
Writer
classes,
but
instead
are part of the InputStream
and
OutputStream
hierarchies.
This
is because the compression
library works with bytes,
not characters.
However,
you might sometimes be
forced to mix the two
types of streams.
(Remember
that you can use
InputStreamReader
and
OutputStreamWriter
to
provide easy conversion
between one type
and
another.)
Compression
class
Function
CheckedInputStream
GetCheckSum(
) produces
checksum
for
any InputStream
(not
just
decompression).
CheckedOutputStream
GetCheckSum(
) produces
checksum
for
any OutputStream
(not
just
compression).
DeflaterOutputStream
Base
class for compression
classes.
ZipOutputStream
A
DeflaterOutputStream
that
compresses
data into the Zip
file format.
GZIPOutputStream
A
DeflaterOutputStream
that
compresses
data into the GZIP
file
format.
InflaterInputStream
Base
class for decompression
classes.
ZipInputStream
An
InflaterInputStream
that
decompresses
data that has been
stored
in
the Zip file
format.
GZIPInputStream
An
InflaterInputStream
that
decompresses
data that has been
stored
in
the GZIP file
format.
Although
there are many compression
algorithms, Zip and GZIP
are
possibly
the most commonly used.
Thus you can easily
manipulate your
606
Thinking
in Java

compressed
data with the many
tools available for reading
and writing
these
formats.
Simple
compression with GZIP
The
GZIP interface is simple and
thus is probably more
appropriate when
you
have a single stream of data
that you want to compress
(rather than a
container
of dissimilar pieces of data).
Here's an example that
compresses
a
single file:
//:
c11:GZIPcompress.java
//
Uses GZIP compression to compress a file
//
whose name is passed on the command line.
import
java.io.*;
import
java.util.zip.*;
public
class GZIPcompress {
//
Throw exceptions to console:
public
static void main(String[] args)
throws
IOException {
BufferedReader
in =
new
BufferedReader(
new
FileReader(args[0]));
BufferedOutputStream
out =
new
BufferedOutputStream(
new
GZIPOutputStream(
new
FileOutputStream("test.gz")));
System.out.println("Writing
file");
int
c;
while((c
= in.read()) != -1)
out.write(c);
in.close();
out.close();
System.out.println("Reading
file");
BufferedReader
in2 =
new
BufferedReader(
new
InputStreamReader(
new
GZIPInputStream(
new
FileInputStream("test.gz"))));
String
s;
while((s
= in2.readLine()) != null)
Chapter
11: The Java I/O
System
607
System.out.println(s);
}
}
///:~
The
use of the compression
classes is straightforward--you simply
wrap
your
output stream in a GZIPOutputStream
or
ZipOutputStream
and
your input stream in a
GZIPInputStream
or
ZipInputStream.
All
else
is ordinary I/O reading and
writing. This is an example of
mixing the
char-oriented
streams with the byte-oriented
streams: in
uses
the
Reader
classes,
whereas GZIPOutputStream's
constructor can
accept
only
an OutputStream
object,
not a Writer
object.
When the file is
opened,
the GZIPInputStream
is
converted to a Reader.
Multifile
storage with Zip
The
library that supports the
Zip format is much more
extensive. With it
you
can easily store multiple
files, and there's even a
separate class to
make
the process of reading a Zip
file easy. The library
uses the standard
Zip
format so that it works
seamlessly with all the
tools currently
downloadable
on the Internet. The
following example has the
same form
as
the previous example, but it
handles as many command-line
arguments
as
you want. In addition, it
shows the use of the
Checksum
classes
to
calculate
and verify the checksum
for the file. There
are two Checksum
types:
Adler32
(which
is faster) and CRC32
(which
is slower but
slightly
more
accurate).
//:
c11:ZipCompress.java
//
Uses Zip compression to compress any
//
number of files given on the command line.
import
java.io.*;
import
java.util.*;
import
java.util.zip.*;
public
class ZipCompress {
//
Throw exceptions to console:
public
static void main(String[] args)
throws
IOException {
FileOutputStream
f =
new
FileOutputStream("test.zip");
CheckedOutputStream
csum =
new
CheckedOutputStream(
608
Thinking
in Java

f,
new Adler32());
ZipOutputStream
out =
new
ZipOutputStream(
new
BufferedOutputStream(csum));
out.setComment("A
test of Java Zipping");
//
No corresponding getComment(),
though.
for(int
i = 0; i < args.length; i++) {
System.out.println(
"Writing
file " + args[i]);
BufferedReader
in =
new
BufferedReader(
new
FileReader(args[i]));
out.putNextEntry(new
ZipEntry(args[i]));
int
c;
while((c
= in.read()) != -1)
out.write(c);
in.close();
}
out.close();
//
Checksum valid only after the file
//
has been closed!
System.out.println("Checksum:
" +
csum.getChecksum().getValue());
//
Now extract the files:
System.out.println("Reading
file");
FileInputStream
fi =
new
FileInputStream("test.zip");
CheckedInputStream
csumi =
new
CheckedInputStream(
fi,
new Adler32());
ZipInputStream
in2 =
new
ZipInputStream(
new
BufferedInputStream(csumi));
ZipEntry
ze;
while((ze
= in2.getNextEntry()) != null) {
System.out.println("Reading
file " + ze);
int
x;
while((x
= in2.read()) != -1)
System.out.write(x);
}
System.out.println("Checksum:
" +
Chapter
11: The Java I/O
System
609

csumi.getChecksum().getValue());
in2.close();
//
Alternative way to open and read
//
zip files:
ZipFile
zf = new ZipFile("test.zip");
Enumeration
e = zf.entries();
while(e.hasMoreElements())
{
ZipEntry
ze2 = (ZipEntry)e.nextElement();
System.out.println("File:
" + ze2);
//
... and extract the data as before
}
}
}
///:~
For
each file to add to the
archive, you must call
putNextEntry( )
and
pass
it a ZipEntry
object.
The ZipEntry
object
contains an extensive
interface
that allows you to get
and set all the
data available on
that
particular
entry in your Zip file:
name, compressed and
uncompressed
sizes,
date, CRC checksum, extra
field data, comment,
compression
method,
and whether it's a directory
entry. However, even though
the Zip
format
has a way to set a password,
this is not supported in
Java's Zip
library.
And although CheckedInputStream
and
CheckedOutputStream
support
both Adler32
and
CRC32
checksums,
the ZipEntry
class
supports only an interface
for CRC. This
is
a restriction of the underlying
Zip format, but it might
limit you from
using
the faster Adler32.
To
extract files, ZipInputStream
has
a getNextEntry(
) method
that
returns
the next ZipEntry
if
there is one. As a more
succinct alternative,
you
can read the file
using a ZipFile
object,
which has a method
entries(
) to
return an Enumeration
to
the ZipEntries.
In
order to read the checksum
you must somehow have
access to the
associated
Checksum
object.
Here, a reference to
the
CheckedOutputStream
and
CheckedInputStream
objects
is
retained,
but you could also
just hold onto a reference
to the Checksum
object.
A
baffling method in Zip
streams is setComment(
).
As shown above,
you
can set a comment when
you're writing a file, but
there's no way to
610
Thinking
in Java

recover
the comment in the ZipInputStream.
Comments appear to be
supported
fully on an entry-by-entry basis
only via ZipEntry.
Of
course, you are not
limited to files when using
the GZIP
or
Zip
libraries--you
can compress anything,
including data to be sent
through a
network
connection.
Java
ARchives (JARs)
The
Zip format is also used in
the JAR (Java ARchive)
file format, which
is
a way to collect a group of
files into a single
compressed file, just
like
Zip.
However, like everything
else in Java, JAR files
are cross-platform so
you
don't need to worry about
platform issues. You can
also include audio
and
image files as well as class
files.
JAR
files are particularly
helpful when you deal
with the Internet.
Before
JAR
files, your Web browser
would have to make repeated
requests of a
Web
server in order to download
all of the files that
make up an applet. In
addition,
each of these files was
uncompressed. By combining all of
the
files
for a particular applet into
a single JAR file, only
one server request
is
necessary and the transfer
is faster because of compression.
And each
entry
in a JAR file can be
digitally signed for
security (refer to the
Java
documentation
for details).
A
JAR file consists of a
single file containing a
collection of zipped
files
along
with a "manifest" that
describes them. (You can
create your own
manifest
file; otherwise the
jar program
will do it for you.) You
can find
out
more about JAR manifests in
the JDK HTML
documentation.
The
jar utility
that comes with Sun's
JDK automatically compresses
the
files
of your choice. You invoke
it on the command
line:
jar
[options] destination [manifest]
inputfile(s)
The
options are simply a
collection of letters (no
hyphen or any other
indicator
is necessary). Unix/Linux users
will note the similarity to
the
tar
options.
These are:
c
Creates
a new or empty
archive.
t
Lists
the table of
contents.
Chapter
11: The Java I/O
System
611
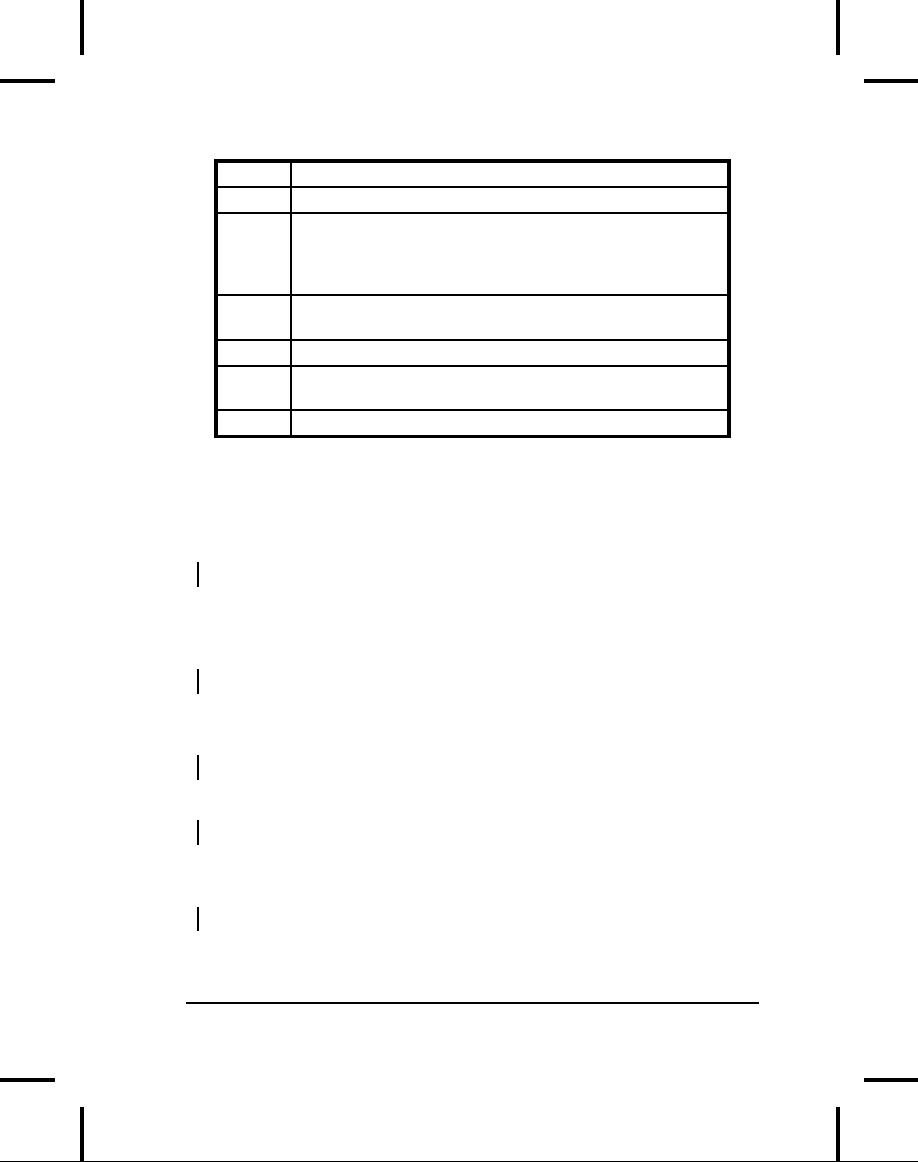
x
Extracts
all files.
x
file
Extracts
the named file.
f
Says:
"I'm going to give you
the name of the file." If
you
don't
use this, jar assumes
that its input will
come from
standard
input, or, if it is creating a
file, its output will
go
to
standard output.
m
Says
that the first argument
will be the name of the
user-
created
manifest file.
v
Generates
verbose output describing
what jar is doing.
0
Only
store the files; doesn't
compress the files (use
to
create
a JAR file that you
can put in your
classpath).
M
Don't
automatically create a manifest
file.
If
a subdirectory is included in the
files to be put into the
JAR file, that
subdirectory
is automatically added, including
all of its
subdirectories,
etc.
Path information is also
preserved.
Here
are some typical ways to
invoke jar:
jar
cf myJarFile.jar *.class
This
creates a JAR file called
myJarFile.jar
that
contains all of the
class
files
in the current directory,
along with an automatically
generated
manifest
file.
jar
cmf myJarFile.jar myManifestFile.mf
*.class
Like
the previous example, but
adding a user-created manifest
file called
myManifestFile.mf.
jar
tf myJarFile.jar
Produces
a table of contents of the
files in myJarFile.jar.
jar
tvf myJarFile.jar
Adds
the "verbose" flag to give
more detailed information
about the files
in
myJarFile.jar.
jar
cvf myApp.jar audio classes image
612
Thinking
in Java

Assuming
audio,
classes,
and
image are
subdirectories, this
combines
all
of the subdirectories into
the file myApp.jar.
The "verbose" flag is
also
included to give extra
feedback while the jar program
is working.
If
you create a JAR file
using the 0
option,
that file can be placed in
your
CLASSPATH:
CLASSPATH="lib1.jar;lib2.jar;"
Then
Java can search lib1.jar
and
lib2.jar
for
class files.
The
jar tool
isn't as useful as a zip
utility.
For example, you can't
add or
update
files to an existing JAR
file; you can create
JAR files only
from
scratch.
Also, you can't move
files into a JAR file,
erasing them as they
are
moved.
However, a JAR file created
on one platform will be
transparently
readable
by the jar
tool
on any other platform (a
problem that
sometimes
plagues
zip utilities).
As
you will see in Chapter
13, JAR files are
also used to package
JavaBeans.
Object
serialization
Java's
object
serialization allows
you to take any object
that implements
the
Serializable
interface
and turn it into a sequence
of bytes that can
later
be fully restored to regenerate
the original object. This is
even true
across
a network, which means that
the serialization
mechanism
automatically
compensates for differences in
operating systems. That
is,
you
can create an object on a
Windows machine, serialize
it, and send it
across
the network to a Unix
machine where it will be
correctly
reconstructed.
You don't have to worry
about the data
representations on
the
different machines, the byte
ordering, or any other
details.
By
itself, object serialization is
interesting because it allows
you to
implement
lightweight
persistence. Remember
that persistence means
an
object's
lifetime is not determined by
whether a program is
executing--the
object
lives in
between invocations of
the program. By taking
a
serializable
object and writing it to
disk, then restoring that
object when
the
program is reinvoked, you're
able to produce the effect
of persistence.
The
reason it's called
"lightweight" is that you
can't simply define
an
Chapter
11: The Java I/O
System
613

object
using some kind of
"persistent" keyword and let
the system take
care
of the details (although
this might happen in the
future). Instead, you
must
explicitly serialize and
deserialize the objects in
your program.
Object
serialization was added to
the language to support two
major
features.
Java's remote
method invocation (RMI)
allows objects that
live
on
other machines to behave as if
they live on your machine.
When
sending
messages to remote objects,
object serialization is necessary
to
transport
the arguments and return
values. RMI is discussed in
Chapter
15.
Object
serialization is also necessary
for JavaBeans, described in
Chapter
13.
When a Bean is used, its
state information is generally
configured at
design-time.
This state information must
be stored and later
recovered
when
the program is started;
object serialization performs
this task.
Serializing
an object is quite simple, as
long as the object
implements the
Serializable
interface
(this interface is just a
flag and has no
methods).
When
serialization was added to
the language, many standard
library
classes
were changed to make them
serializable, including all of
the
wrappers
for the primitive types,
all of the container
classes, and many
others.
Even Class
objects
can be serialized. (See
Chapter 12 for the
implications
of this.)
To
serialize an object, you
create some sort of
OutputStream
object
and
then
wrap it inside an ObjectOutputStream
object.
At this point you
need
only call writeObject(
) and
your object is serialized
and sent to
the
OutputStream.
To reverse the process, you
wrap an InputStream
inside
an ObjectInputStream
and
call readObject(
).
What comes
back
is, as usual, a reference to an
upcast Object,
so you must downcast
to
set things straight.
A
particularly clever aspect of
object serialization is that it
not only saves
an
image of your object but it
also follows all the
references contained in
your
object and saves those
objects,
and follows all the
references in each
of
those objects, etc. This is
sometimes referred to as the
"web of objects"
that
a single object can be
connected to, and it
includes arrays of
references
to objects as well as member
objects. If you had to
maintain
your
own object serialization
scheme, maintaining the code
to follow all
these
links would be a bit
mind-boggling. However, Java
object
614
Thinking
in Java

serialization
seems to pull it off
flawlessly, no doubt using an
optimized
algorithm
that traverses the web of
objects. The following
example tests
the
serialization mechanism by making a
"worm" of linked objects,
each
of
which has a link to the
next segment in the worm as
well as an array of
references
to objects of a different class,
Data:
//:
c11:Worm.java
//
Demonstrates object serialization.
import
java.io.*;
class
Data implements Serializable {
private
int i;
Data(int
x) { i = x; }
public
String toString() {
return
Integer.toString(i);
}
}
public
class Worm implements Serializable {
//
Generate a random int value:
private
static int r() {
return
(int)(Math.random() * 10);
}
private
Data[] d = {
new
Data(r()), new Data(r()), new Data(r())
};
private
Worm next;
private
char c;
//
Value of i == number of segments
Worm(int
i, char x) {
System.out.println("
Worm constructor: " + i);
c
= x;
if(--i
> 0)
next
= new Worm(i, (char)(x + 1));
}
Worm()
{
System.out.println("Default
constructor");
}
public
String toString() {
String
s = ":" + c + "(";
for(int
i = 0; i < d.length; i++)
Chapter
11: The Java I/O
System
615

s
+= d[i].toString();
s
+= ")";
if(next
!= null)
s
+= next.toString();
return
s;
}
//
Throw exceptions to console:
public
static void main(String[] args)
throws
ClassNotFoundException, IOException
{
Worm
w = new Worm(6, 'a');
System.out.println("w
= " + w);
ObjectOutputStream
out =
new
ObjectOutputStream(
new
FileOutputStream("worm.out"));
out.writeObject("Worm
storage");
out.writeObject(w);
out.close();
// Also flushes output
ObjectInputStream
in =
new
ObjectInputStream(
new
FileInputStream("worm.out"));
String
s = (String)in.readObject();
Worm
w2 = (Worm)in.readObject();
System.out.println(s
+ ", w2 = " + w2);
ByteArrayOutputStream
bout =
new
ByteArrayOutputStream();
ObjectOutputStream
out2 =
new
ObjectOutputStream(bout);
out2.writeObject("Worm
storage");
out2.writeObject(w);
out2.flush();
ObjectInputStream
in2 =
new
ObjectInputStream(
new
ByteArrayInputStream(
bout.toByteArray()));
s
= (String)in2.readObject();
Worm
w3 = (Worm)in2.readObject();
System.out.println(s
+ ", w3 = " + w3);
}
}
///:~
616
Thinking
in Java

To
make things interesting, the
array of Data
objects
inside Worm
are
initialized
with random numbers. (This
way you don't suspect
the
compiler
of keeping some kind of
meta-information.) Each Worm
segment
is labeled with a char
that's
automatically generated in
the
process
of recursively generating the
linked list of Worms.
When you
create
a Worm,
you tell the constructor
how long you want it to
be. To
make
the next
reference
it calls the Worm
constructor
with a length of
one
less, etc. The final
next
reference
is left as null,
indicating the end of
the
Worm.
The
point of all this was to
make something reasonably
complex that
couldn't
easily be serialized. The
act of serializing, however, is
quite
simple.
Once the ObjectOutputStream
is
created from some
other
stream,
writeObject(
) serializes
the object. Notice the
call to
writeObject(
) for
a String,
as well. You can also
write all the
primitive
data
types using the same
methods as DataOutputStream
(they
share
the
same interface).
There
are two separate code
sections that look similar.
The first writes
and
reads a file and the
second, for variety, writes
and reads a
ByteArray.
You can read and
write an object using
serialization to any
DataInputStream
or
DataOutputStream
including,
as you will see in
the
Chapter 15, a network. The
output from one run
was:
Worm
constructor: 6
Worm
constructor: 5
Worm
constructor: 4
Worm
constructor: 3
Worm
constructor: 2
Worm
constructor: 1
w
= :a(262):b(100):c(396):d(480):e(316):f(398)
Worm
storage, w2 =
:a(262):b(100):c(396):d(480):e(316):f(398)
Worm
storage, w3 =
:a(262):b(100):c(396):d(480):e(316):f(398)
You
can see that the
deserialized object really
does contain all of the
links
that
were in the original
object.
Chapter
11: The Java I/O
System
617
Note
that no constructor, not
even the default
constructor, is called in
the
process
of deserializing a Serializable
object.
The entire object is
restored
by recovering data from the
InputStream.
Object
serialization is byte-oriented,
and thus uses the
InputStream
and
OutputStream
hierarchies.
Finding
the class
You
might wonder what's
necessary for an object to be
recovered from its
serialized
state. For example, suppose
you serialize an object and
send it
as
a file or through a network to
another machine. Could a
program on the
other
machine reconstruct the
object using only the
contents of the file?
The
best way to answer this
question is (as usual) by
performing an
experiment.
The following file goes in
the subdirectory for this
chapter:
//:
c11:Alien.java
//
A serializable class.
import
java.io.*;
public
class Alien implements Serializable {
}
///:~
The
file that creates and
serializes an Alien
object
goes in the same
directory:
//:
c11:FreezeAlien.java
//
Create a serialized output file.
import
java.io.*;
public
class FreezeAlien {
//
Throw exceptions to console:
public
static void main(String[] args)
throws
IOException {
ObjectOutput
out =
new
ObjectOutputStream(
new
FileOutputStream("X.file"));
Alien
zorcon = new Alien();
out.writeObject(zorcon);
}
}
///:~
618
Thinking
in Java

Rather
than catching and handling
exceptions, this program
takes the
quick
and dirty approach of
passing the exceptions out
of main(
),
so
they'll
be reported on the command
line.
Once
the program is compiled and
run, copy the resulting
X.file
to
a
subdirectory
called xfiles,
where the following code
goes:
//:
c11:xfiles:ThawAlien.java
//
Try to recover a serialized file without the
//
class of object that's stored in that file.
import
java.io.*;
public
class ThawAlien {
public
static void main(String[] args)
throws
IOException, ClassNotFoundException
{
ObjectInputStream
in =
new
ObjectInputStream(
new
FileInputStream("X.file"));
Object
mystery = in.readObject();
System.out.println(mystery.getClass());
}
}
///:~
This
program opens the file
and reads in the object
mystery
successfully.
However,
as soon as you try to find
out anything about the
object--which
requires
the Class
object
for Alien--the
Java Virtual Machine
(JVM)
cannot
find Alien.class
(unless
it happens to be in the Classpath,
which
it
shouldn't be in this example).
You'll get a ClassNotFoundException.
(Once
again, all evidence of alien
life vanishes before proof
of its existence
can
be verified!)
If
you expect to do much after
you've recovered an object
that has been
serialized,
you must make sure
that the JVM can
find the associated
.class
file
either in the local class
path or somewhere on the
Internet.
Controlling
serialization
As
you can see, the
default serialization mechanism is
trivial to use. But
what
if you have special needs?
Perhaps you have special
security issues
and
you don't want to serialize
portions of your object, or
perhaps it just
Chapter
11: The Java I/O
System
619

doesn't
make sense for one
subobject to be serialized if that
part needs to
be
created anew when the
object is recovered.
You
can control the process of
serialization by implementing
the
Externalizable
interface
instead of the Serializable
interface.
The
Externalizable
interface
extends the Serializable
interface
and adds
two
methods, writeExternal(
) and
readExternal(
), that
are
automatically
called for your object
during serialization
and
deserialization
so that you can perform
your special
operations.
The
following example shows
simple implementations of
the
Externalizable
interface
methods. Note that Blip1
and
Blip2 are
nearly
identical
except for a subtle
difference (see if you can
discover it by
looking
at the code):
//:
c11:Blips.java
//
Simple use of Externalizable & a pitfall.
import
java.io.*;
import
java.util.*;
class
Blip1 implements Externalizable {
public
Blip1() {
System.out.println("Blip1
Constructor");
}
public
void writeExternal(ObjectOutput out)
throws
IOException {
System.out.println("Blip1.writeExternal");
}
public
void readExternal(ObjectInput in)
throws
IOException, ClassNotFoundException
{
System.out.println("Blip1.readExternal");
}
}
class
Blip2 implements Externalizable {
Blip2()
{
System.out.println("Blip2
Constructor");
}
public
void writeExternal(ObjectOutput out)
throws
IOException {
System.out.println("Blip2.writeExternal");
620
Thinking
in Java

}
public
void readExternal(ObjectInput in)
throws
IOException, ClassNotFoundException
{
System.out.println("Blip2.readExternal");
}
}
public
class Blips {
//
Throw exceptions to console:
public
static void main(String[] args)
throws
IOException, ClassNotFoundException
{
System.out.println("Constructing
objects:");
Blip1
b1 = new Blip1();
Blip2
b2 = new Blip2();
ObjectOutputStream
o =
new
ObjectOutputStream(
new
FileOutputStream("Blips.out"));
System.out.println("Saving
objects:");
o.writeObject(b1);
o.writeObject(b2);
o.close();
//
Now get them back:
ObjectInputStream
in =
new
ObjectInputStream(
new
FileInputStream("Blips.out"));
System.out.println("Recovering
b1:");
b1
= (Blip1)in.readObject();
//
OOPS! Throws an exception:
//!
System.out.println("Recovering b2:");
//!
b2 = (Blip2)in.readObject();
}
}
///:~
The
output for this program
is:
Constructing
objects:
Blip1
Constructor
Blip2
Constructor
Saving
objects:
Blip1.writeExternal
Blip2.writeExternal
Recovering
b1:
Chapter
11: The Java I/O
System
621
Blip1
Constructor
Blip1.readExternal
The
reason that the Blip2 object
is not recovered is that
trying to do so
causes
an exception. Can you see
the difference between
Blip1
and
Blip2?
The constructor for
Blip1
is
public,
while the constructor
for
Blip2
is
not, and that causes
the exception upon recovery.
Try making
Blip2's
constructor public
and
removing the //!
comments
to see the
correct
results.
When
b1 is
recovered, the Blip1
default
constructor is called. This
is
different
from recovering a Serializable
object,
in which the object
is
constructed
entirely from its stored
bits, with no constructor
calls. With
an
Externalizable
object,
all the normal default
construction behavior
occurs
(including the initializations at
the point of field
definition), and
then
readExternal(
) is
called. You need to be aware
of this--in
particular,
the fact that all
the default construction
always takes
place--to
produce
the correct behavior in your
Externalizable
objects.
Here's
an example that shows what
you must do to fully store
and retrieve
an
Externalizable
object:
//:
c11:Blip3.java
//
Reconstructing an externalizable
object.
import
java.io.*;
import
java.util.*;
class
Blip3 implements Externalizable {
int
i;
String
s; // No initialization
public
Blip3() {
System.out.println("Blip3
Constructor");
//
s, i not initialized
}
public
Blip3(String x, int a) {
System.out.println("Blip3(String
x, int a)");
s
= x;
i
= a;
//
s & i initialized only in nondefault
//
constructor.
}
622
Thinking
in Java

public
String toString() { return s + i; }
public
void writeExternal(ObjectOutput out)
throws
IOException {
System.out.println("Blip3.writeExternal");
//
You must do this:
out.writeObject(s);
out.writeInt(i);
}
public
void readExternal(ObjectInput in)
throws
IOException, ClassNotFoundException
{
System.out.println("Blip3.readExternal");
//
You must do this:
s
= (String)in.readObject();
i
=in.readInt();
}
public
static void main(String[] args)
throws
IOException, ClassNotFoundException
{
System.out.println("Constructing
objects:");
Blip3
b3 = new Blip3("A String ", 47);
System.out.println(b3);
ObjectOutputStream
o =
new
ObjectOutputStream(
new
FileOutputStream("Blip3.out"));
System.out.println("Saving
object:");
o.writeObject(b3);
o.close();
//
Now get it back:
ObjectInputStream
in =
new
ObjectInputStream(
new
FileInputStream("Blip3.out"));
System.out.println("Recovering
b3:");
b3
= (Blip3)in.readObject();
System.out.println(b3);
}
}
///:~
The
fields s
and
i are
initialized only in the
second constructor, but not
in
the
default constructor. This
means that if you don't
initialize s
and
i in
readExternal(
),
it will be null
(since
the storage for the
object gets
wiped
to zero in the first step of
object creation). If you
comment out the
two
lines of code following the
phrases "You must do this"
and run the
Chapter
11: The Java I/O
System
623

program,
you'll see that when
the object is recovered,
s is
null and
i is
zero.
If
you are inheriting from an
Externalizable
object,
you'll typically call
the
base-class versions of writeExternal(
) and
readExternal(
) to
provide
proper storage and retrieval
of the base-class
components.
So
to make things work
correctly you must not
only write the
important
data
from the object during
the writeExternal(
) method
(there is no
default
behavior that writes any of
the member objects for
an
Externalizable
object),
but you must also
recover that data in
the
readExternal(
) method.
This can be a bit confusing
at first because the
default
construction behavior for an
Externalizable
object
can make it
seem
like some kind of storage
and retrieval takes place
automatically. It
does
not.
The
transient keyword
When
you're controlling serialization,
there might be a
particular
subobject
that you don't want
Java's serialization mechanism
to
automatically
save and restore. This is
commonly the case if
that
subobject
represents sensitive information
that you don't want
to
serialize,
such as a password. Even if
that information is private
in
the
object,
once it's serialized it's
possible for someone to
access it by reading
a
file or intercepting a network
transmission.
One
way to prevent sensitive
parts of your object from
being serialized is
to
implement your class as
Externalizable,
as shown previously.
Then
nothing
is automatically serialized and
you can explicitly serialize
only the
necessary
parts inside writeExternal(
).
If
you're working with a
Serializable
object,
however, all
serialization
happens
automatically. To control this,
you can turn off
serialization on a
field-by-field
basis using the transient
keyword,
which says "Don't
bother
saving or restoring this--I'll
take care of it."
For
example, consider a Login
object
that keeps information about
a
particular
login session. Suppose that,
once you verify the
login, you want
to
store the data, but
without the password. The
easiest way to do this
is
624
Thinking
in Java

by
implementing Serializable
and
marking the password
field
as
transient.
Here's what it looks
like:
//:
c11:Logon.java
//
Demonstrates the "transient"
keyword.
import
java.io.*;
import
java.util.*;
class
Logon implements Serializable {
private
Date date = new Date();
private
String username;
private
transient String password;
Logon(String
name, String pwd) {
username
= name;
password
= pwd;
}
public
String toString() {
String
pwd =
(password
== null) ? "(n/a)" : password;
return
"logon info: \n
"+
"username:
" + username +
"\n
date:
" + date +
"\n
password:
" + pwd;
}
public
static void main(String[] args)
throws
IOException, ClassNotFoundException
{
Logon
a = new Logon("Hulk",
"myLittlePony");
System.out.println(
"logon a = " + a);
ObjectOutputStream
o =
new
ObjectOutputStream(
new
FileOutputStream("Logon.out"));
o.writeObject(a);
o.close();
//
Delay:
int
seconds = 5;
long
t = System.currentTimeMillis()
+
seconds * 1000;
while(System.currentTimeMillis()
< t)
;
//
Now get them back:
ObjectInputStream
in =
Chapter
11: The Java I/O
System
625

new
ObjectInputStream(
new
FileInputStream("Logon.out"));
System.out.println(
"Recovering
object at " + new Date());
a
= (Logon)in.readObject();
System.out.println(
"logon a = " + a);
}
}
///:~
You
can see that the
date
and
username
fields
are ordinary (not
transient),
and thus are automatically
serialized. However,
the
password
is
transient,
and so is not stored to
disk; also the
serialization
mechanism makes no attempt to
recover it. The output
is:
logon
a = logon info:
username:
Hulk
date:
Sun Mar 23 18:25:53 PST 1997
password:
myLittlePony
Recovering
object at Sun Mar 23 18:25:59 PST 1997
logon
a = logon info:
username:
Hulk
date:
Sun Mar 23 18:25:53 PST 1997
password:
(n/a)
When
the object is recovered, the
password
field
is null.
Note that
toString(
) must
check for a null
value
of password
because
if you try
to
assemble a String
object
using the overloaded
`+'
operator, and that
operator
encounters a null
reference,
you'll get a
NullPointerException.
(Newer
versions of Java might
contain code to
avoid
this problem.)
You
can also see that
the date
field
is stored to and recovered
from disk
and
not generated anew.
Since
Externalizable
objects
do not store any of their
fields by default,
the
transient
keyword
is for use with Serializable
objects
only.
An
alternative to Externalizable
If
you're not keen on
implementing the Externalizable
interface,
there's
another
approach. You can implement
the Serializable
interface
and
add
(notice
I say "add" and not
"override" or "implement")
methods
626
Thinking
in Java

called
writeObject(
) and
readObject(
) that
will automatically be
called
when the object is
serialized and deserialized,
respectively. That
is,
if
you provide these two
methods they will be used
instead of the
default
serialization.
The
methods must have these
exact signatures:
private
void
writeObject(ObjectOutputStream
stream)
throws
IOException;
private
void
readObject(ObjectInputStream
stream)
throws
IOException,
ClassNotFoundException
From
a design standpoint, things
get really weird here.
First of all, you
might
think that because these
methods are not part of a
base class or the
Serializable
interface,
they ought to be defined in
their own
interface(s).
But
notice that they are
defined as private,
which means they are to
be
called
only by other members of
this class. However, you
don't actually
call
them from other members of
this class, but instead
the
writeObject(
) and
readObject(
) methods
of the
ObjectOutputStream
and
ObjectInputStream
objects
call your
object's
writeObject(
) and
readObject(
) methods.
(Notice my
tremendous
restraint in not launching
into a long diatribe about
using the
same
method names here. In a
word: confusing.) You might
wonder how
the
ObjectOutputStream
and
ObjectInputStream
objects
have
access
to private
methods
of your class. We can only
assume that this is
part
of the serialization
magic.
In
any event, anything defined
in an interface
is
automatically public
so
if
writeObject(
) and
readObject(
) must
be private,
then they can't
be
part of an interface.
Since you must follow
the signatures exactly,
the
effect
is the same as if you're
implementing an interface.
It
would appear that when
you call
ObjectOutputStream.writeObject(
),
the Serializable
object
that
you
pass it to is interrogated (using
reflection, no doubt) to see if
it
implements
its own writeObject(
).
If so, the normal
serialization
Chapter
11: The Java I/O
System
627

process
is skipped and the writeObject(
) is
called. The same sort
of
situation
exists for readObject(
).
There's
one other twist. Inside
your writeObject(
),
you can choose to
perform
the default writeObject(
) action
by calling
defaultWriteObject(
).
Likewise, inside readObject(
) you
can call
defaultReadObject(
).
Here is a simple example
that demonstrates how
you
can control the storage
and retrieval of a Serializable
object:
//:
c11:SerialCtl.java
//
Controlling serialization by adding your
own
//
writeObject() and readObject()
methods.
import
java.io.*;
public
class SerialCtl implements Serializable {
String
a;
transient
String b;
public
SerialCtl(String aa, String bb) {
a
= "Not Transient: " + aa;
b
= "Transient: " + bb;
}
public
String toString() {
return
a + "\n" + b;
}
private
void
writeObject(ObjectOutputStream
stream)
throws
IOException {
stream.defaultWriteObject();
stream.writeObject(b);
}
private
void
readObject(ObjectInputStream
stream)
throws
IOException, ClassNotFoundException
{
stream.defaultReadObject();
b
= (String)stream.readObject();
}
public
static void main(String[] args)
throws
IOException, ClassNotFoundException
{
SerialCtl
sc =
new
SerialCtl("Test1", "Test2");
System.out.println("Before:\n"
+ sc);
628
Thinking
in Java

ByteArrayOutputStream
buf =
new
ByteArrayOutputStream();
ObjectOutputStream
o =
new
ObjectOutputStream(buf);
o.writeObject(sc);
//
Now get it back:
ObjectInputStream
in =
new
ObjectInputStream(
new
ByteArrayInputStream(
buf.toByteArray()));
SerialCtl
sc2 = (SerialCtl)in.readObject();
System.out.println("After:\n"
+ sc2);
}
}
///:~
In
this example, one String
field
is ordinary and the other is
transient,
to
prove that the
non-transient
field
is saved by the
defaultWriteObject(
) method
and the transient
field
is saved and
restored
explicitly. The fields are
initialized inside the
constructor rather
than
at the point of definition to
prove that they are
not being initialized
by
some automatic mechanism
during deserialization.
If
you are going to use
the default mechanism to
write the non-transient
parts
of your object, you must
call defaultWriteObject(
) as
the first
operation
in writeObject(
) and
defaultReadObject(
) as
the first
operation
in readObject(
).
These are strange method
calls. It would
appear,
for example, that you
are calling defaultWriteObject(
) for
an
ObjectOutputStream
and
passing it no arguments, and
yet it somehow
turns
around and knows the
reference to your object and
how to write all
the
non-transient
parts.
Spooky.
The
storage and retrieval of the
transient
objects
uses more familiar
code.
And yet, think about
what happens here. In
main(
),
a SerialCtl
object
is created, and then it's
serialized to an ObjectOutputStream.
(Notice
in this case that a buffer
is used instead of a file--it's
all the same
to
the ObjectOutputStream.)
The serialization occurs in
the line:
o.writeObject(sc);
The
writeObject(
) method
must be examining sc
to
see if it has its
own
writeObject(
) method.
(Not by checking the
interface--there isn't
one--
Chapter
11: The Java I/O
System
629

or
the class type, but by
actually hunting for the
method using
reflection.)
If
it does, it uses that. A
similar approach holds true
for readObject(
).
Perhaps
this was the only
practical way that they
could solve the
problem,
but
it's certainly
strange.
Versioning
It's
possible that you might
want to change the version
of a serializable
class
(objects of the original
class might be stored in a
database, for
example).
This is supported but you'll
probably do it only in special
cases,
and
it requires an extra depth of
understanding that we will
not attempt
to
achieve here. The JDK
HTML documents downloadable
from
java.sun.com
cover
this topic quite
thoroughly.
You
will also notice in the
JDK HTML documentation many
comments
that
begin with:
Warning:
Serialized
objects of this class will not be
compatible with
future
Swing releases. The current
serialization support is
appropriate
for short term storage or RMI
between applications. ...
This
is because the versioning
mechanism is too simple to
work reliably in
all
situations, especially with
JavaBeans. They're working on a
correction
for
the design, and that's
what the warning is
about.
Using
persistence
It's
quite appealing to use
serialization technology to store
some of the
state
of your program so that you
can easily restore the
program to the
current
state later. But before
you can do this, some
questions must be
answered.
What happens if you
serialize two objects that
both have a
reference
to a third object? When you
restore those two objects
from their
serialized
state, do you get only
one occurrence of the third
object? What
if
you serialize your two
objects to separate files
and deserialize them
in
different
parts of your code?
Here's
an example that shows the
problem:
//:
c11:MyWorld.java
import
java.io.*;
import
java.util.*;
630
Thinking
in Java

class
House implements Serializable {}
class
Animal implements Serializable {
String
name;
House
preferredHouse;
Animal(String
nm, House h) {
name
= nm;
preferredHouse
= h;
}
public
String toString() {
return
name + "[" + super.toString() +
"],
" + preferredHouse + "\n";
}
}
public
class MyWorld {
public
static void main(String[] args)
throws
IOException, ClassNotFoundException
{
House
house = new House();
ArrayList
animals = new ArrayList();
animals.add(
new
Animal("Bosco the dog", house));
animals.add(
new
Animal("Ralph the hamster", house));
animals.add(
new
Animal("Fronk the cat", house));
System.out.println("animals:
" + animals);
ByteArrayOutputStream
buf1 =
new
ByteArrayOutputStream();
ObjectOutputStream
o1 =
new
ObjectOutputStream(buf1);
o1.writeObject(animals);
o1.writeObject(animals);
// Write a 2nd set
//
Write to a different stream:
ByteArrayOutputStream
buf2 =
new
ByteArrayOutputStream();
ObjectOutputStream
o2 =
new
ObjectOutputStream(buf2);
o2.writeObject(animals);
Chapter
11: The Java I/O
System
631
Table of Contents:
- Introduction to Objects:The progress of abstraction, An object has an interface
- Everything is an Object:You manipulate objects with references, Your first Java program
- Controlling Program Flow:Using Java operators, Execution control, true and false
- Initialization & Cleanup:Method overloading, Member initialization
- Hiding the Implementation:the library unit, Java access specifiers, Interface and implementation
- Reusing Classes:Composition syntax, Combining composition and inheritance
- Polymorphism:Upcasting revisited, The twist, Designing with inheritance
- Interfaces & Inner Classes:Extending an interface with inheritance, Inner class identifiers
- Holding Your Objects:Container disadvantage, List functionality, Map functionality
- Error Handling with Exceptions:Basic exceptions, Catching an exception
- The Java I/O System:The File class, Compression, Object serialization, Tokenizing input
- Run-time Type Identification:The need for RTTI, A class method extractor
- Creating Windows & Applets:Applet restrictions, Running applets from the command line
- Multiple Threads:Responsive user interfaces, Sharing limited resources, Runnable revisited
- Distributed Computing:Network programming, Servlets, CORBA, Enterprise JavaBeans
- A: Passing & Returning Objects:Aliasing, Making local copies, Cloning objects
- B: The Java Native Interface (JNI):Calling a native method, the JNIEnv argument
- Java Programming Guidelines:Design, Implementation
- Resources:Software, Books, My own list of books
- Index