 |

a.getClass().getName());
for(int i = 0; i
< tests.length; i++) {
Collections2.fill(a,
Collections2.countries.reset(),
tests[i].size);
System.out.print(tests[i].name);
long
t1 = System.currentTimeMillis();
tests[i].test(a,
reps);
long
t2 = System.currentTimeMillis();
System.out.println(":
" + (t2 - t1));
}
}
public
static void testArray(int reps) {
System.out.println("Testing
array as List");
//
Can only do first two tests on an array:
for(int
i = 0; i < 2; i++) {
String[]
sa = new String[tests[i].size];
Arrays2.fill(sa,
Collections2.countries.reset());
List
a = Arrays.asList(sa);
System.out.print(tests[i].name);
long
t1 = System.currentTimeMillis();
tests[i].test(a,
reps);
long
t2 = System.currentTimeMillis();
System.out.println(":
" + (t2 - t1));
}
}
public
static void main(String[] args) {
int
reps = 50000;
//
Or, choose the number of repetitions
//
via the command line:
if(args.length
> 0)
reps
= Integer.parseInt(args[0]);
System.out.println(reps
+ " repetitions");
testArray(reps);
test(new
ArrayList(), reps);
test(new
LinkedList(), reps);
test(new
Vector(), reps);
}
}
///:~
504
Thinking
in Java

The
inner class Tester
is
abstract,
to provide a base class for
the specific
tests.
It contains a String
to
be printed when the test
starts, a size
parameter
to be used by the test for
quantity of elements or repetitions
of
tests,
a constructor to initialize the
fields, and an abstract
method
test(
) that
does the work. All
the different types of tests
are collected in
one
place, the array tests,
which is initialized with
different anonymous
inner
classes that inherit from
Tester.
To add or remove tests,
simply add
or
remove an inner class
definition from the array,
and everything else
happens
automatically.
To
compare array access to
container access (primarily
against
ArrayList),
a special test is created
for arrays by wrapping one
as a List
using
Arrays.asList(
).
Note that only the
first two tests can
be
performed
in this case, because you
cannot insert or remove
elements
from
an array.
The
List that's
handed to test(
) is
first filled with elements,
then each
test
in the tests
array
is timed. The results will
vary from machine to
machine;
they are intended to give
only an order of
magnitude
comparison
between the performance of
the different containers.
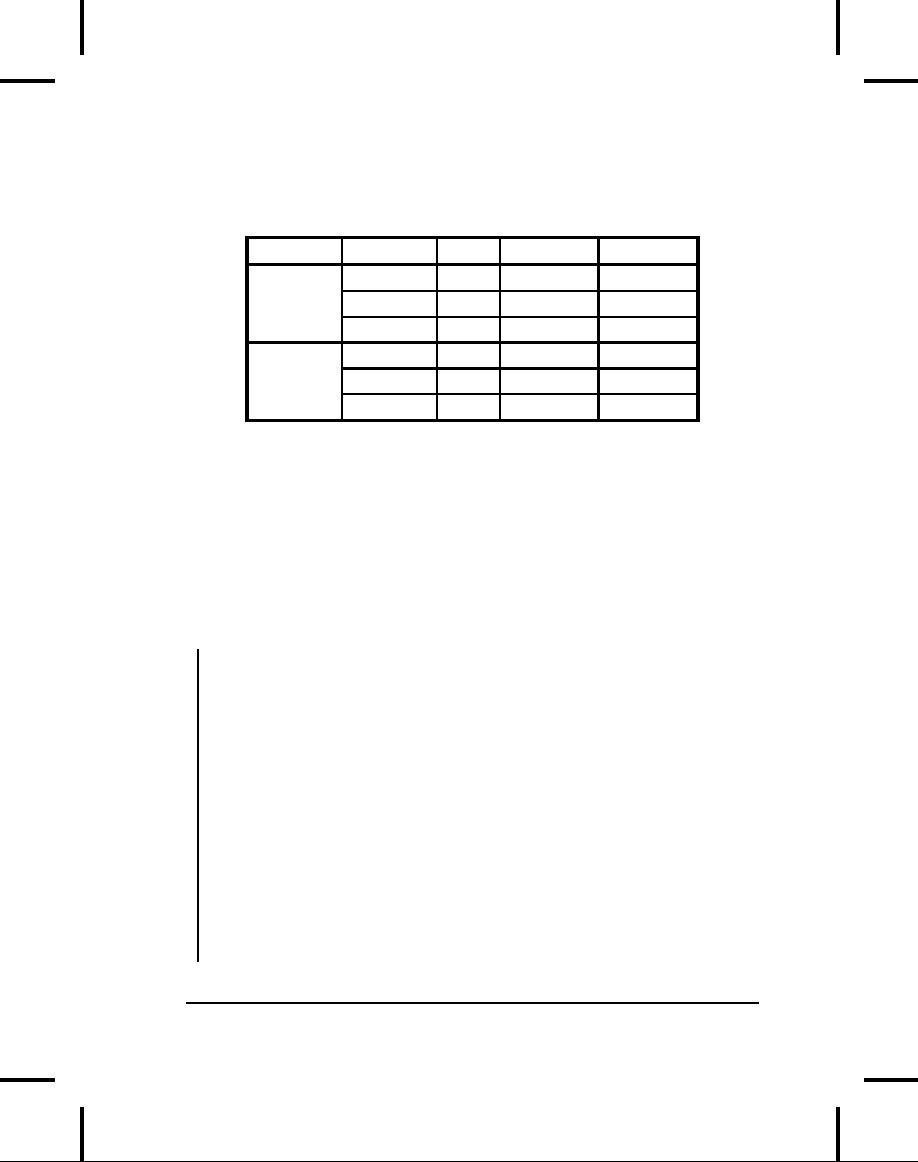
Here is
a
summary of one run:
Type
Get
Iteration
Insert
Remove
array
1430
3850
na
na
ArrayList
3070
12200
500
46850
LinkedList
16320
9110
110
60
Vector
4890
16250
550
46850
As
expected, arrays are faster
than any container for
random-access
lookups
and iteration. You can
see that random accesses
(get(
))
are
cheap
for ArrayLists
and expensive for LinkedLists.
(Oddly, iteration
is
faster
for
a LinkedList
than
an ArrayList,
which is a bit
counterintuitive.)
On the other hand,
insertions and removals from
the
middle
of a list are dramatically
cheaper for a LinkedList
than
for an
ArrayList--especially
removals.
Vector
is
generally not as fast
as
ArrayList,
and it should be avoided;
it's only in the library
for legacy
code
support (the only reason it
works in this program is
because it was
adapted
to be a List
in
Java 2). The best
approach is probably to
choose
Chapter
9: Holding Your
Objects
505

an
ArrayList
as
your default, and to change
to a LinkedList
if
you
discover
performance problems due to
many insertions and
removals
from
the middle of the list.
And of course, if you are
working with a fixed-
sized
group of elements, use an
array.
Choosing
between Sets
You
can choose between a
TreeSet
and
a HashSet,
depending on the
size
of the Set
(if
you need to produce an
ordered sequence from a
Set,
use
TreeSet).
The following test program
gives an indication of
this
trade-off:
//:
c09:SetPerformance.java
import
java.util.*;
import
com.bruceeckel.util.*;
public
class SetPerformance {
private
abstract static class Tester {
String
name;
Tester(String
name) { this.name = name; }
abstract
void test(Set s, int size, int reps);
}
private
static Tester[] tests = {
new
Tester("add") {
void
test(Set s, int size, int reps) {
for(int
i = 0; i < reps; i++) {
s.clear();
Collections2.fill(s,
Collections2.countries.reset(),size);
}
}
},
new
Tester("contains") {
void
test(Set s, int size, int reps) {
for(int
i = 0; i < reps; i++)
for(int
j = 0; j < size; j++)
s.contains(Integer.toString(j));
}
},
new
Tester("iteration") {
void
test(Set s, int size, int reps) {
506
Thinking
in Java

for(int
i = 0; i < reps * 10; i++) {
Iterator
it = s.iterator();
while(it.hasNext())
it.next();
}
}
},
};
public
static void
test(Set
s, int size, int reps) {
System.out.println("Testing
" +
s.getClass().getName()
+ " size " + size);
Collections2.fill(s,
Collections2.countries.reset(),
size);
for(int
i = 0; i < tests.length; i++) {
System.out.print(tests[i].name);
long
t1 = System.currentTimeMillis();
tests[i].test(s,
size, reps);
long
t2 = System.currentTimeMillis();
System.out.println(":
" +
((double)(t2
- t1)/(double)size));
}
}
public
static void main(String[] args) {
int
reps = 50000;
//
Or, choose the number of repetitions
//
via the command line:
if(args.length
> 0)
reps
= Integer.parseInt(args[0]);
//
Small:
test(new
TreeSet(), 10, reps);
test(new
HashSet(), 10, reps);
//
Medium:
test(new
TreeSet(), 100, reps);
test(new
HashSet(), 100, reps);
//
Large:
test(new
TreeSet(), 1000, reps);
test(new
HashSet(), 1000, reps);
}
}
///:~
Chapter
9: Holding Your
Objects
507
The
following table shows the
results of one run. (Of
course, this will be
different
according to the computer
and JVM you are
using; you should
run
the test yourself as
well):
Type
Test
size
Add
Contains
Iteration
10
138.0
115.0
187.0
TreeSet
100
189.5
151.1
206.5
1000
150.6
177.4
40.04
10
55.0
82.0
192.0
HashSet
100
45.6
90.0
202.2
1000
36.14
106.5
39.39
The
performance of HashSet
is
generally superior to TreeSet
for
all
operations
(but in particular addition
and lookup, the two
most important
operations).
The only reason TreeSet
exists
is because it maintains
its
elements
in sorted order, so you only
use it when you need a
sorted Set.
Choosing
between Maps
When
choosing between implementations of
Map,
the size of the Map is
what
most strongly affects
performance, and the
following test
program
gives
an indication of this
trade-off:
//:
c09:MapPerformance.java
//
Demonstrates performance differences in
Maps.
import
java.util.*;
import
com.bruceeckel.util.*;
public
class MapPerformance {
private
abstract static class Tester {
String
name;
Tester(String
name) { this.name = name; }
abstract
void test(Map m, int size, int reps);
}
private
static Tester[] tests = {
new
Tester("put") {
void
test(Map m, int size, int reps) {
for(int
i = 0; i < reps; i++) {
m.clear();
508
Thinking
in Java

Collections2.fill(m,
Collections2.geography.reset(),
size);
}
}
},
new
Tester("get") {
void
test(Map m, int size, int reps) {
for(int
i = 0; i < reps; i++)
for(int
j = 0; j < size; j++)
m.get(Integer.toString(j));
}
},
new
Tester("iteration") {
void
test(Map m, int size, int reps) {
for(int
i = 0; i < reps * 10; i++) {
Iterator
it = m.entrySet().iterator();
while(it.hasNext())
it.next();
}
}
},
};
public
static void
test(Map
m, int size, int reps) {
System.out.println("Testing
" +
m.getClass().getName()
+ " size " + size);
Collections2.fill(m,
Collections2.geography.reset(),
size);
for(int
i = 0; i < tests.length; i++) {
System.out.print(tests[i].name);
long
t1 = System.currentTimeMillis();
tests[i].test(m,
size, reps);
long
t2 = System.currentTimeMillis();
System.out.println(":
" +
((double)(t2
- t1)/(double)size));
}
}
public
static void main(String[] args) {
int
reps = 50000;
//
Or, choose the number of repetitions
//
via the command line:
Chapter
9: Holding Your
Objects
509
if(args.length
> 0)
reps
= Integer.parseInt(args[0]);
//
Small:
test(new
TreeMap(), 10, reps);
test(new
HashMap(), 10, reps);
test(new
Hashtable(), 10, reps);
//
Medium:
test(new
TreeMap(), 100, reps);
test(new
HashMap(), 100, reps);
test(new
Hashtable(), 100, reps);
//
Large:
test(new
TreeMap(), 1000, reps);
test(new
HashMap(), 1000, reps);
test(new
Hashtable(), 1000, reps);
}
}
///:~
Because
the size of the map is
the issue, you'll see
that the timing
tests
divide
the time by the size to
normalize each measurement.
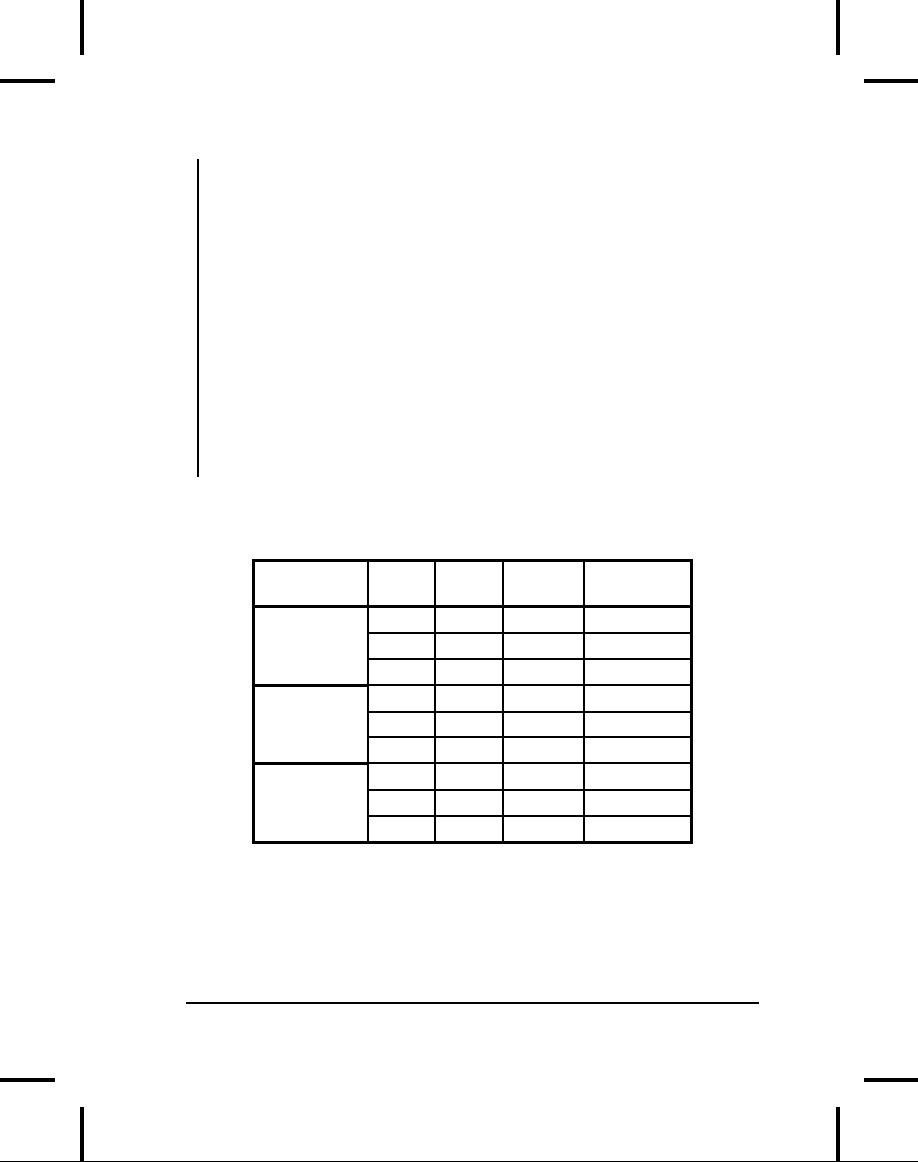
Here is one
set
of results. (Yours will
probably be different.)
Type
Test
Put
Get
Iteration
size
10
143.0
110.0
186.0
TreeMap
100
201.1
188.4
280.1
1000
222.8
205.2
40.7
10
66.0
83.0
197.0
HashMap
100
80.7
135.7
278.5
1000
48.2
105.7
41.4
10
61.0
93.0
302.0
Hashtable
100
90.6
143.3
329.0
1000
54.1
110.95
47.3
As
you might expect, Hashtable
performance
is roughly equivalent to
HashMap.
(You can also see
that HashMap
is
generally a bit
faster.
HashMap
is
intended to replace Hashtable.)
The TreeMap
is
generally
slower than the HashMap,
so why would you use
it? So you
could
use it not as a Map,
but as a way to create an
ordered list. The
510
Thinking
in Java

behavior
of a tree is such that it's
always in order and doesn't
have to be
specially
sorted. Once you fill a
TreeMap,
you can call keySet(
) to
get a
Set
view
of the keys, then toArray( )
to
produce an array of those
keys.
You
can then use the
static
method
Arrays.binarySearch(
)
(discussed
later) to rapidly find
objects in your sorted
array. Of course,
you
would probably only do this
if, for some reason,
the behavior of a
HashMap
was
unacceptable, since HashMap
is
designed to rapidly
find
things.
Also, you can easily
create a HashMap
from
a TreeMap
with
a
single
object creation In the end,
when you're using a
Map your
first
choice
should be HashMap,
and only if you need a
constantly sorted
Map
will
you need TreeMap.
Sorting
and searching
Lists
Utilities
to perform sorting and
searching for Lists
have the same
names
and
signatures as those for
sorting arrays of objects,
but are static
methods
of Collections
instead
of Arrays.
Here's an example,
modified
from
ArraySearching.java:
//:
c09:ListSortSearch.java
//
Sorting and searching Lists with 'Collections.'
import
com.bruceeckel.util.*;
import
java.util.*;
public
class ListSortSearch {
public
static void main(String[] args) {
List
list = new ArrayList();
Collections2.fill(list,
Collections2.capitals,
25);
System.out.println(list
+ "\n");
Collections.shuffle(list);
System.out.println("After
shuffling: "+list);
Collections.sort(list);
System.out.println(list
+ "\n");
Object
key = list.get(12);
int
index =
Collections.binarySearch(list,
key);
Chapter
9: Holding Your
Objects
511
System.out.println("Location
of " + key +
"
is " + index + ", list.get(" +
index
+ ") = " + list.get(index));
AlphabeticComparator
comp =
new
AlphabeticComparator();
Collections.sort(list,
comp);
System.out.println(list
+ "\n");
key
= list.get(12);
index
=
Collections.binarySearch(list,
key, comp);
System.out.println("Location
of " + key +
"
is " + index + ", list.get(" +
index
+ ") = " + list.get(index));
}
}
///:~
The
use of these methods is
identical to the ones in
Arrays,
but you're
using
a List
instead
of an array. Just like
searching and sorting
with
arrays,
if you sort using a
Comparator
you
must binarySearch(
)
using
the same Comparator.
This
program also demonstrates
the shuffle(
) method
in Collections,
which
randomizes the order of a
List.
Utilities
There
are a number of other useful
utilities in the Collections
class:
enumeration(Collection)
Produces
an old-style
Enumeration
for
the argument.
max(Collection)
Produces
the maximum or
minimum
element in the
min(Collection)
argument
using the natural
comparison
method of the
objects
in the Collection.
max(Collection,
Comparator)
Produces
the maximum or
minimum
element in the
min(Collection,
Comparator)
Collection
using
the
Comparator.
reverse(
)
Reverses
all the elements in
512
Thinking
in Java
place.
copy(List
dest, List src)
Copies
elements from src to
dest.
fill(List
list, Object o)
Replaces
all the elements of
list
with
o.
nCopies(int
n, Object o)
Returns
an immutable List
of
size
n whose references all
point
to
o.
Note
that min(
) and
max( )
work
with Collection
objects,
not with
Lists,
so you don't need to worry
about whether the Collection
should
be
sorted or not. (As mentioned
earlier, you do
need
to sort(
) a
List or
an
array before performing a
binarySearch(
).)
Making
a Collection or
Map
unmodifiable
Often
it is convenient to create a read-only
version of a Collection
or
Map.
The Collections
class
allows you to do this by
passing the original
container
into a method that hands
back a read-only version.
There are
four
variations on this method,
one each for Collection
(if
you don't
want
to treat a Collection
as
a more specific type),
List,
Set,
and
Map.
This
example shows the proper
way to build read-only
versions of each:
//:
c09:ReadOnly.java
//
Using the Collections.unmodifiable methods.
import
java.util.*;
import
com.bruceeckel.util.*;
public
class ReadOnly {
static
Collections2.StringGenerator gen =
Collections2.countries;
public
static void main(String[] args) {
Collection
c = new ArrayList();
Collections2.fill(c,
gen, 25); // Insert data
c
= Collections.unmodifiableCollection(c);
System.out.println(c);
// Reading is OK
c.add("one");
// Can't change it
List
a = new ArrayList();
Chapter
9: Holding Your
Objects
513

Collections2.fill(a,
gen.reset(), 25);
a
= Collections.unmodifiableList(a);
ListIterator
lit = a.listIterator();
System.out.println(lit.next());
// Reading OK
lit.add("one");
// Can't change it
Set
s = new HashSet();
Collections2.fill(s,
gen.reset(), 25);
s
= Collections.unmodifiableSet(s);
System.out.println(s);
// Reading OK
//!
s.add("one"); // Can't change it
Map
m = new HashMap();
Collections2.fill(m,
Collections2.geography,
25);
m
= Collections.unmodifiableMap(m);
System.out.println(m);
// Reading OK
//!
m.put("Ralph", "Howdy!");
}
}
///:~
In
each case, you must
fill the container with
meaningful data before
you
make
it read-only. Once it is loaded,
the best approach is to
replace the
existing
reference with the reference
that is produced by
the
"unmodifiable"
call. That way, you
don't run the risk of
accidentally
changing
the contents once you've
made it unmodifiable. On the
other
hand,
this tool also allows
you to keep a modifiable
container as private
within
a class and to return a
read-only reference to that
container from a
method
call. So you can change it
from within the class,
but everyone else
can
only read it.
Calling
the "unmodifiable" method
for a particular type does
not cause
compile-time
checking, but once the
transformation has occurred,
any
calls
to methods that modify the
contents of a particular container
will
produce
an UnsupportedOperationException.
Synchronizing
a Collection or
Map
The
synchronized
keyword
is an important part of the
subject of
multithreading,
a more complicated topic
that will not be
introduced
until
Chapter 14. Here, I shall
note only that the
Collections
class
514
Thinking
in Java

contains
a way to automatically synchronize an
entire container. The
syntax
is similar to the "unmodifiable"
methods:
//:
c09:Synchronization.java
//
Using the Collections.synchronized methods.
import
java.util.*;
public
class Synchronization {
public
static void main(String[] args) {
Collection
c =
Collections.synchronizedCollection(
new
ArrayList());
List
list = Collections.synchronizedList(
new
ArrayList());
Set
s = Collections.synchronizedSet(
new
HashSet());
Map
m = Collections.synchronizedMap(
new
HashMap());
}
}
///:~
In
this case, you immediately
pass the new container
through the
appropriate
"synchronized" method; that
way there's no chance
of
accidentally
exposing the unsynchronized
version.
Fail
fast
The
Java containers also have a
mechanism to prevent more
than one
process
from modifying the contents
of a container. The problem
occurs if
you're
iterating through a container
and some other process
steps in and
inserts,
removes, or changes an object in
that container. Maybe
you've
already
passed that object, maybe
it's ahead of you, maybe
the size of the
container
shrinks after you call
size(
)--there
are many scenarios
for
disaster.
The Java containers library
incorporates a fail-fast
mechanism
that
looks for any changes to
the container other than
the ones your
process
is personally responsible for. If it
detects that someone else
is
modifying
the container, it immediately
produces a
ConcurrentModificationException.
This is the "fail-fast"
aspect--it
doesn't
try to detect a problem
later on using a more
complex algorithm.
Chapter
9: Holding Your
Objects
515

It's
quite easy to see the
fail-fast mechanism in operation--all
you have to
do
is create an iterator and
then add something to the
collection that the
iterator
is pointing to, like
this:
//:
c09:FailFast.java
//
Demonstrates the "fail fast" behavior.
import
java.util.*;
public
class FailFast {
public
static void main(String[] args) {
Collection
c = new ArrayList();
Iterator
it = c.iterator();
c.add("An
object");
//
Causes an exception:
String
s = (String)it.next();
}
}
///:~
The
exception happens because
something is placed in the
container after
the
iterator is acquired from
the container. The
possibility that two
parts
of
the program could be
modifying the same container
produces an
uncertain
state, so the exception
notifies you that you
should change your
code--in
this case, acquire the
iterator after
you
have added all
the
elements
to the container.
Note
that you cannot benefit
from this kind of monitoring
when you're
accessing
the elements of a List
using
get(
).
Unsupported
operations
It's
possible to turn an array
into a List
with
the Arrays.asList(
)
method:
//:
c09:Unsupported.java
//
Sometimes methods defined in the
//
Collection interfaces don't work!
import
java.util.*;
public
class Unsupported {
private
static String[] s = {
"one",
"two", "three", "four", "five",
516
Thinking
in Java

"six",
"seven", "eight", "nine", "ten",
};
static
List a = Arrays.asList(s);
static
List a2 = a.subList(3, 6);
public
static void main(String[] args) {
System.out.println(a);
System.out.println(a2);
System.out.println(
"a.contains("
+ s[0] + ") = " +
a.contains(s[0]));
System.out.println(
"a.containsAll(a2)
= " +
a.containsAll(a2));
System.out.println("a.isEmpty()
= " +
a.isEmpty());
System.out.println(
"a.indexOf("
+ s[5] + ") = " +
a.indexOf(s[5]));
//
Traverse backwards:
ListIterator
lit = a.listIterator(a.size());
while(lit.hasPrevious())
System.out.print(lit.previous()
+ " ");
System.out.println();
//
Set the elements to different values:
for(int
i = 0; i < a.size(); i++)
a.set(i,
"47");
System.out.println(a);
//
Compiles, but won't run:
lit.add("X");
// Unsupported operation
a.clear();
// Unsupported
a.add("eleven");
// Unsupported
a.addAll(a2);
// Unsupported
a.retainAll(a2);
// Unsupported
a.remove(s[0]);
// Unsupported
a.removeAll(a2);
// Unsupported
}
}
///:~
You'll
discover that only a portion
of the Collection
and
List interfaces
are
actually implemented. The
rest of the methods cause
the unwelcome
appearance
of something called an
Chapter
9: Holding Your
Objects
517

UnsupportedOperationException.
You'll learn all about
exceptions
in
the next chapter, but
the short story is that
the Collection
interface--as
well as some of the other
interfaces
in the Java
containers
library--contain "optional" methods,
which might or might
not
be
"supported" in the concrete
class that implements
that
interface.
Calling
an unsupported method causes
an
UnsupportedOperationException
to
indicate a programming
error.
"What?!?"
you say, incredulous. "The
whole point of interfaces
and base
classes
is that they promise these
methods will do something
meaningful!
This
breaks that promise--it says
that not only will
calling some methods
not
perform
a meaningful behavior, they
will stop the program!
Type
safety
was just thrown out
the window!"
It's
not quite that bad.
With a Collection,
List,
Set,
or Map,
the
compiler
still restricts you to
calling only the methods in
that interface,
so
it's not like Smalltalk
(in which you can
call any method for
any object,
and
find out only when
you run the program
whether your call
does
anything).
In addition, most methods
that take a Collection
as
an
argument
only read from that
Collection--all
the "read" methods of
Collection
are
not
optional.
This
approach prevents an explosion of
interfaces in the design.
Other
designs
for container libraries
always seem to end up with a
confusing
plethora
of interfaces to describe each of
the variations on the main
theme
and
are thus difficult to learn.
It's not even possible to
capture all of the
special
cases in interfaces,
because someone can always
invent a new
interface.
The "unsupported operation"
approach achieves an
important
goal
of the Java containers
library: the containers are
simple to learn and
use;
unsupported operations are a
special case that can be
learned later.
For
this approach to work,
however:
1.
The
UnsupportedOperationException
must
be a rare event.
That
is, for most classes
all operations should work,
and only in
special
cases should an operation be
unsupported. This is true
in
the
Java containers library,
since the classes you'll
use 99 percent
of
the time--ArrayList,
LinkedList,
HashSet,
and HashMap,
as
well as the other concrete
implementations--support all of
the
operations.
The design does provide a
"back door" if you want
to
518
Thinking
in Java

create
a new Collection
without
providing meaningful
definitions
for
all the methods in the
Collection
interface, and
yet still fit it
into
the existing library.
2.
When
an operation is
unsupported,
there should be
reasonable
likelihood
that an UnsupportedOperationException
will
appear
at implementation time, rather
than after you've
shipped
the
product to the customer.
After all, it indicates a
programming
error:
you've used an implementation
incorrectly. This point is
less
certain,
and is where the
experimental nature of this
design comes
into
play. Only over time
will we find out how
well it works.
In
the example above, Arrays.asList(
) produces
a List
that
is backed
by
a fixed-size array. Therefore it
makes sense that the
only supported
operations
are the ones that
don't change the size of
the array. If, on
the
other
hand, a new interface
were
required to express this
different kind
of
behavior (called, perhaps,
"FixedSizeList"),
it would throw open
the
door
to complexity and soon you
wouldn't know where to start
when
trying
to use the library.
The
documentation for a method
that takes a Collection,
List,
Set,
or
Map
as
an argument should specify
which of the optional
methods must
be
implemented. For example,
sorting requires the
set( )
and
Iterator.set(
) methods,
but not add(
) and
remove(
).
Java
1.0/1.1 containers
Unfortunately,
a lot of code was written
using the Java 1.0/1.1
containers,
and
even new code is sometimes
written using these classes.
So although
you
should never use the
old containers when writing
new code, you'll
still
need
to be aware of them. However,
the old containers were
quite limited,
so
there's not that much to
say about them. (Since
they are in the past,
I
will
try to refrain from
overemphasizing some of the
hideous design
decisions.)
Vector
& Enumeration
The
only self-expanding sequence in
Java 1.0/1.1 was the
Vector,
and so
it
saw a lot of use. Its
flaws are too numerous to
describe here (see
the
Chapter
9: Holding Your
Objects
519

first
edition of this book,
available on this book's CD
ROM and as a free
download
from ).
Basically, you can think of
it as an
ArrayList
with
long, awkward method names.
In the Java 2
container
library,
Vector
was
adapted so that it could fit
as a Collection
and
a
List,
so in the following example
the Collections2.fill(
) method
is
successfully
used. This turns out to be a
bit perverse, as it may
confuse
some
people into thinking that
Vector
has
gotten better, when it
is
actually
included only to support
pre-Java 2 code.
The
Java 1.0/1.1 version of the
iterator chose to invent a
new name,
"enumeration,"
instead of using a term that
everyone was already
familiar
with.
The Enumeration
interface
is smaller than Iterator,
with only
two
methods, and it uses longer
method names: boolean
hasMoreElements(
) produces
true if
this enumeration contains
more
elements,
and Object
nextElement( ) returns
the next element of
this
enumeration
if there are any more
(otherwise it throws an
exception).
Enumeration
is
only an interface, not an
implementation, and even
new
libraries
sometimes still use the
old Enumeration--which
is unfortunate
but
generally harmless. Even
though you should always
use Iterator
when
you can in your own
code, you must be prepared
for libraries that
want
to hand you an Enumeration.
In
addition, you can produce an
Enumeration
for
any Collection
by
using
the Collections.enumeration(
) method,
as seen in this
example:
//:
c09:Enumerations.java
//
Java 1.0/1.1 Vector and Enumeration.
import
java.util.*;
import
com.bruceeckel.util.*;
class
Enumerations {
public
static void main(String[] args) {
Vector
v = new Vector();
Collections2.fill(
v,
Collections2.countries, 100);
Enumeration
e = v.elements();
while(e.hasMoreElements())
System.out.println(e.nextElement());
520
Thinking
in Java

//
Produce an Enumeration from a
Collection:
e
= Collections.enumeration(new
ArrayList());
}
}
///:~
The
Java 1.0/1.1 Vector
has
only an addElement(
) method,
but fill(
)
uses
the add(
) method
that was pasted on as
Vector
was
turned into a
List.
To produce an Enumeration,
you call elements(
),
then you can
use
it to perform a forward
iteration.
The
last line creates an
ArrayList
and
uses enumeration(
) to
adapt an
Enumeration
from
the ArrayList
Iterator. Thus, if
you have old
code
that
wants an Enumeration,
you can still use
the new containers.
Hashtable
As
you've seen in the
performance comparison in this
chapter, the basic
Hashtable
is
very similar to the
HashMap,
even down to the
method
names.
There's no reason to use
Hashtable
instead
of HashMap
in
new
code.
Stack
The
concept of the stack was
introduced earlier, with the
LinkedList.
What's
rather odd about the
Java 1.0/1.1 Stack
is
that instead of using
a
Vector
as
a building block, Stack
is
inherited
from
Vector.
So it has all
of
the characteristics and
behaviors of a Vector
plus
some extra Stack
behaviors.
It's difficult to know
whether the designers
explicitly decided
that
this was an especially
useful way of doing things,
or whether it was
just
a naive design.
Here's
a simple demonstration of Stack
that
pushes each line from
a
String
array:
//:
c09:Stacks.java
//
Demonstration of Stack Class.
import
java.util.*;
public
class Stacks {
static
String[] months = {
"January",
"February", "March", "April",
Chapter
9: Holding Your
Objects
521

"May",
"June", "July", "August", "September",
"October",
"November", "December" };
public
static void main(String[] args) {
Stack
stk = new Stack();
for(int
i = 0; i < months.length; i++)
stk.push(months[i]
+ " ");
System.out.println("stk
= " + stk);
//
Treating a stack as a Vector:
stk.addElement("The
last line");
System.out.println(
"element
5 = " + stk.elementAt(5));
System.out.println("popping
elements:");
while(!stk.empty())
System.out.println(stk.pop());
}
}
///:~
Each
line in the months
array
is inserted into the
Stack
with
push(
),
and
later fetched from the
top of the stack with a
pop( ).
To make a point,
Vector
operations
are also performed on the
Stack
object.
This is
possible
because, by virtue of inheritance, a
Stack
is a
Vector.
Thus, all
operations
that can be performed on a
Vector
can
also be performed on a
Stack,
such as elementAt(
).
As
mentioned earlier, you
should use a LinkedList
when
you want stack
behavior.
BitSet
A
BitSet
is
used if you want to
efficiently store a lot of
on-off information.
It's
efficient only from the
standpoint of size; if you're
looking for efficient
access,
it is slightly slower than
using an array of some
native type.
In
addition, the minimum size
of the BitSet
is
that of a long:
64 bits.
This
implies that if you're
storing anything smaller,
like 8 bits, a BitSet
will
be wasteful; you're better
off creating your own
class, or just an
array,
to
hold your flags if size is
an issue.
A
normal container expands as
you add more elements,
and the BitSet
does
this as well. The following
example shows how the
BitSet
works:
//:
c09:Bits.java
522
Thinking
in Java

//
Demonstration of BitSet.
import
java.util.*;
public
class Bits {
static
void printBitSet(BitSet b) {
System.out.println("bits:
" + b);
String
bbits = new String();
for(int
j = 0; j < b.size() ; j++)
bbits
+= (b.get(j) ? "1" : "0");
System.out.println("bit
pattern: " + bbits);
}
public
static void main(String[] args) {
Random
rand = new Random();
//
Take the LSB of nextInt():
byte
bt = (byte)rand.nextInt();
BitSet
bb = new BitSet();
for(int
i = 7; i >=0; i--)
if(((1
<< i) & bt) != 0)
bb.set(i);
else
bb.clear(i);
System.out.println("byte
value: " + bt);
printBitSet(bb);
short
st = (short)rand.nextInt();
BitSet
bs = new BitSet();
for(int
i = 15; i >=0; i--)
if(((1
<< i) & st) != 0)
bs.set(i);
else
bs.clear(i);
System.out.println("short
value: " + st);
printBitSet(bs);
int
it = rand.nextInt();
BitSet
bi = new BitSet();
for(int
i = 31; i >=0; i--)
if(((1
<< i) & it) != 0)
bi.set(i);
else
bi.clear(i);
Chapter
9: Holding Your
Objects
523

System.out.println("int
value: " + it);
printBitSet(bi);
//
Test bitsets >= 64 bits:
BitSet
b127 = new BitSet();
b127.set(127);
System.out.println("set
bit 127: " + b127);
BitSet
b255 = new BitSet(65);
b255.set(255);
System.out.println("set
bit 255: " + b255);
BitSet
b1023 = new BitSet(512);
b1023.set(1023);
b1023.set(1024);
System.out.println("set
bit 1023: " + b1023);
}
}
///:~
The
random number generator is
used to create a random
byte,
short,
and
int,
and each one is transformed
into a corresponding bit
pattern in a
BitSet.
This works fine because a
BitSet
is
64 bits, so none of
these
cause
it to increase in size. Then a
BitSet
of
512 bits is created.
The
constructor
allocates storage for twice
that number of bits.
However, you
can
still set bit 1024 or
greater.
Summary
To
review the containers
provided in the standard
Java library:
1.
An
array associates numerical
indices to objects. It holds
objects of
a
known type so that you
don't have to cast the
result when you're
looking
up an object. It can be multidimensional,
and it can hold
primitives.
However, its size cannot be
changed once you create
it.
2.
A
Collection
holds
single elements, while a
Map holds
associated
pairs.
3.
Like
an array, a List
also
associates numerical indices to
objects--
you
can think of arrays and
Lists
as ordered containers. The
List
automatically
resizes itself as you add
more elements. But a
List
can
hold only Object
references, so it won't
hold primitives and
524
Thinking
in Java

you
must always cast the
result when you pull an
Object
reference
out
of a container.
4.
Use
an ArrayList
if
you're doing a lot of random
accesses, and a
LinkedList
if
you will be doing a lot of
insertions and removals
in
the
middle of the list.
5.
The
behavior of queues, deques,
and stacks is provided via
the
LinkedList.
6.
A
Map is
a way to associate not
numbers, but objects
with
other
objects.
The design of a HashMap
is
focused on rapid
access,
while
a TreeMap
keeps
its keys in sorted order,
and thus is not as
fast
as a HashMap.
7.
A
Set
only
accepts one of each type of
object. HashSets
provide
maximally
fast lookups, while
TreeSets
keep the elements in
sorted
order.
8.
There's
no need to use the legacy
classes Vector,
Hashtable
and
Stack
in
new code.
The
containers are tools that
you can use on a day-to-day
basis to make
your
programs simpler, more
powerful, and more
effective.
Exercises
Solutions
to selected exercises can be
found in the electronic
document The
Thinking in Java
Annotated
Solution Guide, available
for a small fee from
.
1.
Create
an array of double
and
fill( )
it
using
RandDoubleGenerator.
Print the results.
2.
Create
a new class called Gerbil
with
an int
gerbilNumber
that's
initialized in the constructor
(similar to the Mouse
example
in
this chapter). Give it a
method called hop(
) that
prints out
which
gerbil number this is,
and that it's hopping.
Create an
ArrayList
and
add a bunch of Gerbil
objects
to the List.
Now
use
the get(
) method
to move through the
List and
call hop(
)
for
each Gerbil.
Chapter
9: Holding Your
Objects
525

3.
Modify
Exercise 2 so you use an
Iterator
to
move through the
List
while
calling hop(
).
4.
Take
the Gerbil
class
in Exercise 2 and put it
into a Map
instead,
associating
the name of the Gerbil
as
a String
(the
key) for each
Gerbil
(the
value) you put in the
table. Get an Iterator
for
the
keySet(
) and
use it to move through the
Map,
looking up the
Gerbil
for
each key and printing
out the key and
telling the
gerbil
to
hop( ).
5.
Create
a List
(try
both ArrayList
and
LinkedList)
and fill it
using
Collections2.countries.
Sort the list and
print it, then
apply
Collections.shuffle(
) to
the list repeatedly,
printing it
each
time so that you can
see how the shuffle(
) method
randomizes
the list differently each
time.
6.
Demonstrate
that you can't add
anything but a Mouse
to
a
MouseList.
7.
Modify
MouseList.java
so
that it inherits from
ArrayList
instead
of using composition. Demonstrate
the problem with
this
approach.
8.
Repair
CatsAndDogs.java
by
creating a Cats
container
(utilizing
ArrayList)
that will only accept
and retrieve Cat
objects.
9.
Create
a container that encapsulates an
array of String,
and that
only
adds Strings
and gets Strings,
so that there are no
casting
issues
during use. If the internal
array isn't big enough
for the next
add,
your container should
automatically resize it. In
main(
),
compare
the performance of your
container with an ArrayList
holding
Strings.
10.
Repeat
Exercise 9 for a container of
int,
and compare the
performance
to an ArrayList
holding
Integer
objects.
In your
performance
comparison, include the
process of incrementing
each
object in the
container.
11.
Using
the utilities in com.bruceeckel.util,
create an array of
each
primitive type and of
String,
then fill each array
using an
526
Thinking
in Java

appropriate
generator, and print each
array using the
appropriate
print(
) method.
12.
Create
a generator that produces
character names from
your
favorite
movies (you can use
Snow
White or Star
Wars as a
fallback),
and loops around to the
beginning when it runs out
of
names.
Use the utilities in
com.bruceeckel.util
to
fill an array,
an
ArrayList,
a LinkedList
and
both types of Set,
then print
each
container.
13.
Create
a class containing two
String
objects,
and make it
Comparable
so
that the comparison only
cares about the
first
String.
Fill an array and an
ArrayList
with
objects of your
class,
using
the geography
generator.
Demonstrate that sorting
works
properly.
Now make a Comparator
that
only cares about
the
second
String
and
demonstrate that sorting
works properly; also
perform
a binary search using your
Comparator.
14.
Modify
Exercise 13 so that an alphabetic
sort is used.
15.
Use
Arrays2.RandStringGenerator
to
fill a TreeSet
but
using
alphabetic
ordering. Print the
TreeSet
to
verify the sort
order.
16.
Create
both an ArrayList
and
a LinkedList,
and fill each
using
the
Collections2.capitals
generator.
Print each list using
an
ordinary
Iterator,
then insert one list
into the other using
a
ListIterator,
inserting at every other
location. Now perform
the
insertion
starting at the end of the
first list and moving
backward.
17.
Write
a method that uses an
Iterator
to
step through a
Collection
and
print the hashCode(
) of
each object in the
container.
Fill all the different
types of Collections
with objects
and
apply your method to each
container.
18.
Repair
the problem in InfiniteRecursion.java.
19.
Create
a class, then make an
initialized array of objects of
your
class.
Fill a List
from
your array. Create a subset
of your List
using
subList(
),
and then remove this
subset from your List
using
removeAll(
).
Chapter
9: Holding Your
Objects
527

20.
Change
Exercise 6 in Chapter 7 to use an
ArrayList
to
hold the
Rodents
and an Iterator
to
move through the sequence
of
Rodents.
Remember that an ArrayList
holds
only Objects
so
you
must use a cast when
accessing individual Rodents.
21.
Following
the Queue.java
example,
create a Deque
class
and
test
it.
22.
Use
a TreeMap
in
Statistics.java.
Now add code that
tests the
performance
difference between HashMap
and
TreeMap
in
that
program.
23.
Produce
a Map
and
a Set
containing
all the countries that
begin
with
`A.'
24.
Using
Collections2.countries,
fill a Set
multiple
times with the
same
data and verify that
the Set
ends
up with only one of
each
instance.
Try this with both
kinds of Set.
25.
Starting
with Statistics.java,
create a program that runs
the test
repeatedly
and looks to see if any
one number tends to
appear
more
than the others in the
results.
26.
Rewrite
Statistics.java
using
a HashSet
of
Counter
objects
(you'll
have to modify Counter
so
that it will work in
the
HashSet).
Which approach seems
better?
27.
Modify
the class in Exercise 13 so
that it will work with
HashSets
and
as a key in HashMaps.
28.
Using
SlowMap.java
for
inspiration, create a SlowSet.
29.
Apply
the tests in Map1.java
to
SlowMap
to
verify that it works.
Fix
anything in SlowMap
that
doesn't work
correctly.
30.
Implement
the rest of the Map interface
for SlowMap.
31.
Modify
MapPerformance.java
to
include tests of SlowMap.
32.
Modify
SlowMap
so
that instead of two
ArrayLists,
it holds a
single
ArrayList
of
MPair objects.
Verify that the
modified
version
works correctly. Using
MapPerformance.java,
test the
528
Thinking
in Java

speed
of your new Map.
Now change the put( )
method
so that it
performs
a sort(
) after
each pair is entered, and
modify get(
) to
use
Collections.binarySearch(
) to
look up the key.
Compare
the
performance of the new
version with the old
ones.
33.
Add
a char
field
to CountedString
that
is also initialized in
the
constructor,
and modify the hashCode(
) and
equals( )
methods
to
include the value of this
char.
34.
Modify
SimpleHashMap
so
that it reports collisions,
and test
this
by adding the same data
set twice so that you
see collisions.
35.
Modify
SimpleHashMap
so
that it reports the number
of
"probes"
necessary when collisions
occur. That is, how
many calls
to
next( )
must
be made on the Iterators
that walk the
LinkedLists
looking for matches?
36.
Implement
the clear(
) and
remove( )
methods
for
SimpleHashMap.
37.
Implement
the rest of the Map interface
for SimpleHashMap.
38.
Add
a private
rehash( ) method to
SimpleHashMap
that
is
invoked
when the load factor
exceeds 0.75. During
rehashing,
double
the number of buckets, then
search for the first
prime
number
greater than that to
determine the new number
of
buckets.
39.
Following
the example in SimpleHashMap.java,
create and test
a
SimpleHashSet.
40.
Modify
SimpleHashMap
to
use ArrayLists
instead of
LinkedLists.
Modify MapPerformance.java
to
compare the
performance
of the two
implementations.
41.
Using
the HTML documentation for
the JDK (downloadable
from
java.sun.com),
look up the HashMap
class.
Create a HashMap,
fill
it with elements, and
determine the load factor.
Test the lookup
speed
with this map, then
attempt to increase the
speed by making
a
new HashMap
with
a larger initial capacity
and copying the
old
Chapter
9: Holding Your
Objects
529

map
into the new one,
running your lookup speed
test again on the
new
map.
42.
In
Chapter 8, locate the
GreenhouseControls.java
example,
which
consists of three files. In
Controller.java,
the class
EventSet
is
just a container. Change the
code to use a
LinkedList
instead
of an EventSet.
This will require more
than
just
replacing EventSet
with
LinkedList;
you'll also need to
use
an
Iterator
to
cycle through the set of
events.
43.
(Challenging).
Write your own hashed
map class, customized for
a
particular
key type: String
for
this example. Do not inherit
it from
Map.
Instead, duplicate the
methods so that the
put( )
and
get(
)
methods
specifically take String
objects,
not Objects,
as keys.
Everything
that involves keys should
not use generic types,
but
instead
work with Strings,
to avoid the cost of
upcasting and
downcasting.
Your goal is to make the
fastest possible
custom
implementation.
Modify MapPerformance.java
to
test your
implementation
vs. a HashMap.
44.
(Challenging).
Find the source code
for List
in
the Java source
code
library that comes with
all Java distributions. Copy
this code
and
make a special version
called intList
that
holds only ints.
Consider
what it would take to make a
special version of List
for
all
the primitive types. Now
consider what happens if you
want to
make
a linked list class that
works with all the
primitive types. If
parameterized
types are ever implemented
in Java, they will
provide
a way to do this work for
you automatically (as well
as
many
other benefits).
530
Thinking
in Java

10:
Error Handling
with
Exceptions
The
basic philosophy of Java is
that "badly formed
code
will
not be run."
The
ideal time to catch an error
is at compile-time, before you
even try to
run
the program. However, not
all errors can be detected
at compile-time.
The
rest of the problems must be
handled at run-time, through
some
formality
that allows the originator
of the error to pass
appropriate
information
to a recipient who will know
how to handle the
difficulty
properly.
In
C and other earlier
languages, there could be
several of these
formalities,
and they were generally
established by convention and
not as
part
of the programming language.
Typically, you returned a
special value
or
set a flag, and the
recipient was supposed to
look at the value or the
flag
and
determine that something was
amiss. However, as the years
passed, it
was
discovered that programmers
who use a library tend to
think of
themselves
as invincible--as in, "Yes,
errors might happen to
others, but
not
in my
code."
So, not too surprisingly,
they wouldn't check for
the error
conditions
(and sometimes the error
conditions were too silly to
check
for1). If
you were
thorough
enough to check for an error
every time you
called
a method, your code could
turn into an unreadable
nightmare.
Because
programmers could still coax
systems out of these
languages they
were
resistant to admitting the
truth: This approach to
handling errors
was
a major limitation to creating
large, robust, maintainable
programs.
The
solution is to take the
casual nature out of error
handling and to
enforce
formality. This actually has
a long history, since
implementations
of
exception
handling go back to
operating systems in the
1960s, and even
1
The C programmer can
look up the return value of
printf(
) for
an example of this.
531

to
BASIC's "on
error goto." But
C++ exception handling was
based on
Ada,
and Java's is based
primarily on C++ (although it
looks even more
like
Object Pascal).
The
word "exception" is meant in
the sense of "I take
exception to that."
At
the point where the
problem occurs you might
not know what to do
with
it, but you do know
that you can't just
continue on merrily; you
must
stop
and somebody, somewhere,
must figure out what to
do. But you
don't
have
enough information in the
current context to fix the
problem. So you
hand
the problem out to a higher
context where someone is
qualified to
make
the proper decision (much
like a chain of
command).
The
other rather significant
benefit of exceptions is that
they clean up
error
handling code. Instead of
checking for a particular
error and dealing
with
it at multiple places in your
program, you no longer need
to check at
the
point of the method call
(since the exception will
guarantee that
someone
catches it). And, you
need to handle the problem
in only one
place,
the so-called exception
handler. This
saves you code, and
it
separates
the code that describes
what you want to do from
the code that
is
executed when things go
awry. In general, reading,
writing, and
debugging
code becomes much clearer
with exceptions than when
using
the
old way of error
handling.
Because
exception handling is enforced by
the Java compiler, there
are
only
so many examples that can be
written in this book without
learning
about
exception handling. This
chapter introduces you to
the code you
need
to write to properly handle
exceptions, and the way
you can generate
your
own exceptions if one of
your methods gets into
trouble.
Basic
exceptions
An
exceptional
condition is a problem
that prevents the
continuation of
the
method or scope that you're
in. It's important to
distinguish an
exceptional
condition from a normal
problem, in which you have
enough
information
in the current context to
somehow cope with the
difficulty.
With
an exceptional condition, you
cannot continue processing
because
you
don't have the information
necessary to deal with the
problem in
the
current
context. All
you can do is jump out of
the current context
and
532
Thinking
in Java

relegate
that problem to a higher
context. This is what
happens when you
throw
an exception.
A
simple example is a divide. If
you're about to divide by
zero, it's worth
checking
to make sure you don't go
ahead and perform the
divide. But
what
does it mean that the
denominator is zero? Maybe
you know, in the
context
of the problem you're trying
to solve in that particular
method,
how
to deal with a zero
denominator. But if it's an
unexpected value, you
can't
deal with it and so must
throw an exception rather
than continuing
along
that path.
When
you throw an exception,
several things happen.
First, the exception
object
is created in the same way
that any Java object is
created: on the
heap,
with new.
Then the current path of
execution (the one you
couldn't
continue)
is stopped and the reference
for the exception object is
ejected
from
the current context. At this
point the exception handling
mechanism
takes
over and begins to look
for an appropriate place to
continue
executing
the program. This
appropriate place is the
exception
handler,
whose
job is to recover from the
problem so the program can
either try
another
tack or just
continue.
As
a simple example of throwing an
exception, consider an
object
reference
called t.
It's possible that you
might be passed a reference
that
hasn't
been initialized, so you
might want to check before
trying to call a
method
using that object reference.
You can send information
about the
error
into a larger context by
creating an object representing
your
information
and "throwing" it out of
your current context. This
is called
throwing
an exception. Here's
what it looks like:
if(t
== null)
throw
new NullPointerException();
This
throws the exception, which
allows you--in the current
context--to
abdicate
responsibility for thinking
about the issue further.
It's just
magically
handled somewhere else.
Precisely where
will
be shown shortly.
Exception
arguments
Like
any object in Java, you
always create exceptions on
the heap using
new,
which allocates storage and
calls a constructor. There
are two
Chapter
10: Error Handling with
Exceptions
533

constructors
in all standard exceptions:
the first is the default
constructor,
and
the second takes a string
argument so you can place
pertinent
information
in the exception:
if(t
== null)
throw
new NullPointerException("t = null");
This
string can later be
extracted using various
methods, as will be
shown
shortly.
The
keyword throw
causes
a number of relatively magical
things to
happen.
Typically, you'll first use
new to
create an object that
represents
the
error condition. You give
the resulting reference to
throw.
The object
is,
in effect, "returned" from
the method, even though
that object type
isn't
normally what the method is
designed to return. A simplistic
way to
think
about exception handling is as an
alternate return
mechanism,
although
you get into trouble if
you take that analogy
too far. You can
also
exit
from ordinary scopes by
throwing an exception. But a
value is
returned,
and the method or scope
exits.
Any
similarity to an ordinary return
from a method ends here,
because
where
you
return is someplace completely
different from where
you
return
for a normal method call.
(You end up in an appropriate
exception
handler
that might be miles
away--many levels lower on
the call stack--
from
where the exception was
thrown.)
In
addition, you can throw
any type of Throwable
object
that you want.
Typically,
you'll throw a different
class of exception for each
different type
of
error. The information about
the error is represented
both inside the
exception
object and implicitly in the
type of exception object
chosen, so
someone
in the bigger context can
figure out what to do with
your
exception.
(Often, the only information
is the type of exception
object, and
nothing
meaningful is stored within
the exception
object.)
Catching
an exception
If
a method throws an exception, it
must assume that exception
is
"caught"
and dealt with. One of
the advantages of Java
exception handling
is
that it allows you to
concentrate on the problem
you're trying to solve
in
one
place, and then deal
with the errors from
that code in another
place.
534
Thinking
in Java

To
see how an exception is
caught, you must first
understand the
concept
of
a guarded
region, which is a
section of code that might
produce
exceptions,
and which is followed by the
code to handle those
exceptions.
The
try
block
If
you're inside a method and
you throw an exception (or
another method
you
call within this method
throws an exception), that
method will exit in
the
process of throwing. If you
don't want a throw
to
exit the method,
you
can set up a special block
within that method to
capture the
exception.
This is called the try
block because
you "try" your
various
method
calls there. The try
block is an ordinary scope,
preceded by the
keyword
try:
try
{
//
Code that might generate exceptions
}
If
you were checking for
errors carefully in a programming
language that
didn't
support exception handling,
you'd have to surround every
method
call
with setup and error
testing code, even if you
call the same
method
several
times. With exception
handling, you put everything
in a try block
and
capture all the exceptions
in one place. This means
your code is a lot
easier
to write and easier to read
because the goal of the
code is not
confused
with the error
checking.
Exception
handlers
Of
course, the thrown exception
must end up someplace. This
"place" is
the
exception
handler, and
there's one for every
exception type you
want
to
catch. Exception handlers
immediately follow the try
block and are
denoted
by the keyword catch:
try
{
//
Code that might generate exceptions
}
catch(Type1 id1) {
//
Handle exceptions of Type1
}
catch(Type2 id2) {
//
Handle exceptions of Type2
}
catch(Type3 id3) {
//
Handle exceptions of Type3
Chapter
10: Error Handling with
Exceptions
535

}
//
etc...
Each
catch clause (exception
handler) is like a little
method that takes
one
and
only one argument of a
particular type. The
identifier (id1,
id2,
and
so
on) can be used inside
the handler, just like a
method argument.
Sometimes
you never use the
identifier because the type
of the exception
gives
you enough information to
deal with the exception,
but the identifier
must
still be there.
The
handlers must appear
directly after the try
block. If an exception is
thrown,
the exception handling
mechanism goes hunting for
the first
handler
with an argument that
matches the type of the
exception. Then it
enters
that catch clause, and
the exception is considered
handled. The
search
for handlers stops once
the catch clause is
finished. Only the
matching
catch clause executes; it's
not like a switch
statement
in which
you
need a break
after
each case
to
prevent the remaining ones
from
executing.
Note
that, within the try
block, a number of different
method calls might
generate
the same exception, but
you need only one
handler.
Termination
vs. resumption
There
are two basic models in
exception handling theory. In
termination
(which
is what Java and C++
support), you assume the
error is so critical
that
there's no way to get back
to where the exception
occurred. Whoever
threw
the exception decided that
there was no way to salvage
the
situation,
and they don't want
to
come back.
The
alternative is called resumption.
It means that the exception
handler
is
expected to do something to rectify
the situation, and then
the faulting
method
is retried, presuming success
the second time. If you
want
resumption,
it means you still hope to
continue execution after
the
exception
is handled. In this case,
your exception is more like
a method
call--which
is how you should set up
situations in Java in which
you want
resumption-like
behavior. (That is, don't
throw an exception; call
a
method
that fixes the problem.)
Alternatively, place your
try block
inside
536
Thinking
in Java

a
while loop
that keeps reentering the
try block
until the result is
satisfactory.
Historically,
programmers using operating
systems that
supported
resumptive
exception handling eventually
ended up using
termination-
like
code and skipping
resumption. So although resumption
sounds
attractive
at first, it isn't quite so
useful in practice. The
dominant reason
is
probably the coupling
that
results: your handler must
often be aware of
where
the exception is thrown from
and contain nongeneric code
specific
to
the throwing location. This
makes the code difficult to
write and
maintain,
especially for large systems
where the exception can
be
generated
from many points.
Creating
your own
exceptions
You're
not stuck using the
existing Java exceptions.
This is important
because
you'll often need to create
your own exceptions to
denote a
special
error that your library is
capable of creating, but
which was not
foreseen
when the Java exception
hierarchy was
created.
To
create your own exception
class, you're forced to
inherit from an
existing
type of exception, preferably
one that is close in meaning
to your
new
exception (this is often not
possible, however). The most
trivial way
to
create a new type of
exception is just to let the
compiler create the
default
constructor for you, so it
requires almost no code at
all:
//:
c10:SimpleExceptionDemo.java
//
Inheriting your own exceptions.
class
SimpleException extends Exception {}
public
class SimpleExceptionDemo {
public
void f() throws SimpleException {
System.out.println(
"Throwing
SimpleException from f()");
throw
new SimpleException ();
}
public
static void main(String[] args) {
Chapter
10: Error Handling with
Exceptions
537

SimpleExceptionDemo
sed =
new
SimpleExceptionDemo();
try
{
sed.f();
}
catch(SimpleException e) {
System.err.println("Caught
it!");
}
}
}
///:~
When
the compiler creates the
default constructor, it which
automatically
(and
invisibly) calls the
base-class default constructor. Of
course, in this
case
you don't get a SimpleException(String)
constructor,
but in
practice
that isn't used much. As
you'll see, the most
important thing
about
an exception is the class
name, so most of the time an
exception like
the
one shown above is
satisfactory.
Here,
the result is printed to the
console standard
error stream by
writing
to
System.err.
This is usually a better
place to send error
information
than
System.out,
which may be redirected. If
you send output to
System.err
it
will not be redirected along
with System.out
so
the user
is
more likely to notice
it.
Creating
an exception class that also
has a constructor that takes
a String
is
also quite simple:
//:
c10:FullConstructors.java
//
Inheriting your own exceptions.
class
MyException extends Exception {
public
MyException() {}
public
MyException(String msg) {
super(msg);
}
}
public
class FullConstructors {
public
static void f() throws MyException {
System.out.println(
"Throwing
MyException from f()");
throw
new MyException();
538
Thinking
in Java

}
public
static void g() throws MyException {
System.out.println(
"Throwing
MyException from g()");
throw
new MyException("Originated in g()");
}
public
static void main(String[] args) {
try
{
f();
}
catch(MyException e) {
e.printStackTrace(System.err);
}
try
{
g();
}
catch(MyException e) {
e.printStackTrace(System.err);
}
}
}
///:~
The
added code is small--the
addition of two constructors
that define the
way
MyException
is
created. In the second
constructor, the
base-class
constructor
with a String
argument
is explicitly invoked by using
the
super
keyword.
The
stack trace information is
sent to System.err
so
that it's more
likely
it
will be noticed in the event
that System.out
has
been redirected.
The
output of the program
is:
Throwing
MyException from f()
MyException
at
FullConstructors.f(FullConstructors.java:16)
at
FullConstructors.main(FullConstructors.java:24)
Throwing
MyException from g()
MyException:
Originated in g()
at
FullConstructors.g(FullConstructors.java:20)
at
FullConstructors.main(FullConstructors.java:29)
You
can see the absence of
the detail message in the
MyException
thrown
from f(
).
Chapter
10: Error Handling with
Exceptions
539

The
process of creating your own
exceptions can be taken
further. You can
add
extra constructors and
members:
//:
c10:ExtraFeatures.java
//
Further embellishment of exception classes.
class
MyException2 extends Exception {
public
MyException2() {}
public
MyException2(String msg) {
super(msg);
}
public
MyException2(String msg, int x) {
super(msg);
i
= x;
}
public
int val() { return i; }
private
int i;
}
public
class ExtraFeatures {
public
static void f() throws MyException2 {
System.out.println(
"Throwing
MyException2 from f()");
throw
new MyException2();
}
public
static void g() throws MyException2 {
System.out.println(
"Throwing
MyException2 from g()");
throw
new MyException2("Originated in g()");
}
public
static void h() throws MyException2 {
System.out.println(
"Throwing
MyException2 from h()");
throw
new MyException2(
"Originated
in h()", 47);
}
public
static void main(String[] args) {
try
{
f();
}
catch(MyException2 e) {
e.printStackTrace(System.err);
540
Thinking
in Java

}
try
{
g();
}
catch(MyException2 e) {
e.printStackTrace(System.err);
}
try
{
h();
}
catch(MyException2 e) {
e.printStackTrace(System.err);
System.err.println("e.val()
= " + e.val());
}
}
}
///:~
A
data member i
has
been added, along with a
method that reads
that
value
and an additional constructor
that sets it. The
output is:
Throwing
MyException2 from f()
MyException2
at
ExtraFeatures.f(ExtraFeatures.java:22)
at
ExtraFeatures.main(ExtraFeatures.java:34)
Throwing
MyException2 from g()
MyException2:
Originated in g()
at
ExtraFeatures.g(ExtraFeatures.java:26)
at
ExtraFeatures.main(ExtraFeatures.java:39)
Throwing
MyException2 from h()
MyException2:
Originated in h()
at
ExtraFeatures.h(ExtraFeatures.java:30)
at
ExtraFeatures.main(ExtraFeatures.java:44)
e.val()
= 47
Since
an exception is just another
kind of object, you can
continue this
process
of embellishing the power of
your exception classes. Keep
in
mind,
however, that all this
dressing-up might be lost on
the client
programmers
using your packages, since
they might simply look
for the
exception
to be thrown and nothing
more. (That's the way
most of the
Java
library exceptions are
used.)
Chapter
10: Error Handling with
Exceptions
541

The
exception specification
In
Java, you're required to
inform the client
programmer, who calls
your
method,
of the exceptions that might
be thrown from your method.
This is
civilized,
because the caller can
know exactly what code to
write to catch
all
potential exceptions. Of course, if
source code is available,
the client
programmer
could hunt through and
look for throw
statements,
but
often
a library doesn't come with
sources. To prevent this
from being a
problem,
Java provides syntax (and
forces
you
to use that syntax) to
allow
you
to politely tell the client
programmer what exceptions
this method
throws,
so the client programmer can
handle them. This is the
exception
specification,
and
it's part of the method
declaration, appearing after
the
argument
list.
The
exception specification uses an
additional keyword, throws,
followed
by
a list of all the potential
exception types. So your
method definition
might
look like this:
void
f() throws TooBig, TooSmall, DivZero { //...
If
you say
void
f() { // ...
it
means that no exceptions are
thrown from the method.
(Except
for
the
exceptions
of type RuntimeException,
which can reasonably be
thrown
anywhere--this
will be described
later.)
You
can't lie about an exception
specification--if your method
causes
exceptions
and doesn't handle them,
the compiler will detect
this and tell
you
that you must either
handle the exception or
indicate with an
exception
specification that it may be
thrown from your method.
By
enforcing
exception specifications from
top to bottom, Java
guarantees
that
exception correctness can be
ensured at
compile-time2.
2
This is a significant
improvement over C++ exception handling, which doesn't
catch
violations
of exception specifications until
run time, when it's not very
useful.
542
Thinking
in Java

There
is one place you can
lie: you can claim to
throw an exception
that
you
really don't. The compiler
takes your word for
it, and forces the
users
of
your method to treat it as if it
really does throw that
exception. This has
the
beneficial effect of being a
placeholder for that
exception, so you can
actually
start throwing the exception
later without requiring
changes to
existing
code. It's also important
for creating abstract
base
classes and
interfaces
whose derived classes or
implementations may need to
throw
exceptions.
Catching
any exception
It
is possible to create a handler
that catches any type of
exception. You do
this
by catching the base-class
exception type Exception
(there
are other
types
of base exceptions, but
Exception
is
the base that's pertinent
to
virtually
all programming
activities):
catch(Exception
e) {
System.err.println("Caught
an exception");
}
This
will catch any exception, so
if you use it you'll want to
put it at the
end
of
your list of handlers to
avoid preempting any
exception handlers
that
might otherwise follow
it.
Since
the Exception
class
is the base of all the
exception classes that
are
important
to the programmer, you don't
get much specific
information
about
the exception, but you
can call the methods
that come from its
base
type
Throwable:
String
getMessage( )
String
getLocalizedMessage( )
Gets
the detail message, or a
message adjusted for this
particular locale.
String
toString( )
Returns
a short description of the
Throwable, including the
detail
message
if there is one.
void
printStackTrace( )
void
printStackTrace(PrintStream)
void
printStackTrace(PrintWriter)
Prints
the Throwable and the
Throwable's call stack
trace. The call
stack
Chapter
10: Error Handling with
Exceptions
543

shows
the sequence of method calls
that brought you to the
point at which
the
exception was thrown. The
first version prints to
standard error, the
second
and third prints to a stream
of your choice (in Chapter
11, you'll
understand
why there are two
types of streams).
Throwable
fillInStackTrace( )
Records
information within this
Throwable
object
about the current
state
of the stack frames. Useful
when an application is rethrowing
an
error
or exception (more about
this shortly).
In
addition, you get some
other methods from Throwable's
base type
Object
(everybody's
base type). The one
that might come in handy
for
exceptions
is getClass(
),
which returns an object
representing the
class
of
this object. You can in
turn query this Class
object
for its name
with
getName(
) or
toString(
).
You can also do more
sophisticated things
with
Class
objects
that aren't necessary in
exception handling. Class
objects
will be studied later in
this book.
Here's
an example that shows the
use of the basic Exception
methods:
//:
c10:ExceptionMethods.java
//
Demonstrating the Exception Methods.
public
class ExceptionMethods {
public
static void main(String[] args) {
try
{
throw
new Exception("Here's my
Exception");
}
catch(Exception e) {
System.err.println("Caught
Exception");
System.err.println(
"e.getMessage():
" + e.getMessage());
System.err.println(
"e.getLocalizedMessage():
" +
e.getLocalizedMessage());
System.err.println("e.toString():
" + e);
System.err.println("e.printStackTrace():");
e.printStackTrace(System.err);
}
}
}
///:~
544
Thinking
in Java

The
output for this program
is:
Caught
Exception
e.getMessage():
Here's my Exception
e.getLocalizedMessage():
Here's my Exception
e.toString():
java.lang.Exception:
Here's
my Exception
e.printStackTrace():
java.lang.Exception:
Here's my Exception
at
ExceptionMethods.main(ExceptionMethods.java:7)
java.lang.Exception:
Here's
my Exception
at
ExceptionMethods.main(ExceptionMethods.java:7)
You
can see that the
methods provide successively
more information--
each
is effectively a superset of the
previous one.
Rethrowing
an exception
Sometimes
you'll want to rethrow the
exception that you just
caught,
particularly
when you use Exception
to
catch any exception. Since
you
already
have the reference to the
current exception, you can
simply
rethrow
that reference:
catch(Exception
e) {
System.err.println("An
exception was thrown");
throw
e;
}
Rethrowing
an exception causes the
exception to go to the
exception
handlers
in the next-higher context.
Any further catch
clauses
for the
same
try block
are still ignored. In
addition, everything about
the
exception
object is preserved, so the
handler at the higher
context that
catches
the specific exception type
can extract all the
information from
that
object.
If
you simply rethrow the
current exception, the
information that you
print
about that exception in
printStackTrace(
) will
pertain to the
exception's
origin, not the place
where you rethrow it. If
you want to
install
new stack trace information,
you can do so by
calling
fillInStackTrace(
),
which returns an exception
object that it creates
by
Chapter
10: Error Handling with
Exceptions
545
Table of Contents:
- Introduction to Objects:The progress of abstraction, An object has an interface
- Everything is an Object:You manipulate objects with references, Your first Java program
- Controlling Program Flow:Using Java operators, Execution control, true and false
- Initialization & Cleanup:Method overloading, Member initialization
- Hiding the Implementation:the library unit, Java access specifiers, Interface and implementation
- Reusing Classes:Composition syntax, Combining composition and inheritance
- Polymorphism:Upcasting revisited, The twist, Designing with inheritance
- Interfaces & Inner Classes:Extending an interface with inheritance, Inner class identifiers
- Holding Your Objects:Container disadvantage, List functionality, Map functionality
- Error Handling with Exceptions:Basic exceptions, Catching an exception
- The Java I/O System:The File class, Compression, Object serialization, Tokenizing input
- Run-time Type Identification:The need for RTTI, A class method extractor
- Creating Windows & Applets:Applet restrictions, Running applets from the command line
- Multiple Threads:Responsive user interfaces, Sharing limited resources, Runnable revisited
- Distributed Computing:Network programming, Servlets, CORBA, Enterprise JavaBeans
- A: Passing & Returning Objects:Aliasing, Making local copies, Cloning objects
- B: The Java Native Interface (JNI):Calling a native method, the JNIEnv argument
- Java Programming Guidelines:Design, Implementation
- Resources:Software, Books, My own list of books
- Index