 |
Lecture-39
Web
Warehousing: An introduction
Through
the billions of Web pages
created with HTML and
XML, or generated dynamically by
underlying
Web database service
engines, the Web captures
almost all aspects of human
endeavor
and
provides a fertile ground for
data mining. However,
searching, comprehending, and
using the
semi
structured information stored on
the Web poses a significant
challenge because this data
is
more
sophisticated and dynamic
than the information that
commercial database systems store.
To
supplement
keyword -based indexing, which forms
the cornerstone for Web
search engines,
researchers have
applied data mining to Web
-page ranking. In this context,
data mining helps
Web
search engines find high
-quality Web pages and
enhances Web clickstream
analysis. For the
Web to
reach its full potential,
believe this technology will play an
increasingly important role in
meeting
the challenges of developing
the intelligent Web.
Putting
the pieces
together
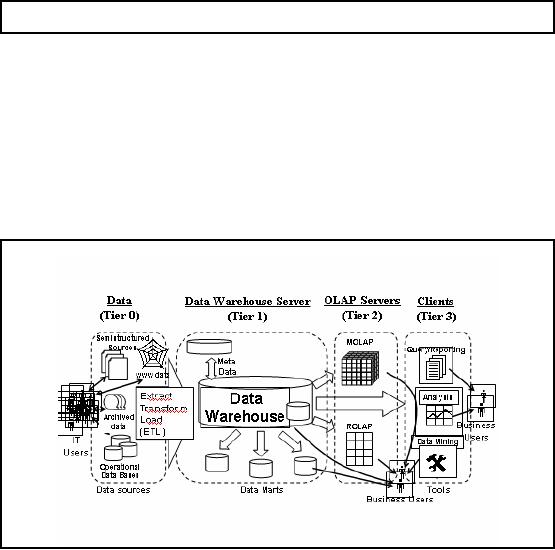
Figure-39.1:
Putting pieces
together
Figure 39.1
shows the same multi-tier
architecture for data
warehousing, as was shown in
a
previous
lecture. The figure shows
different components of an overall
decision support
system
and their
interaction.
326
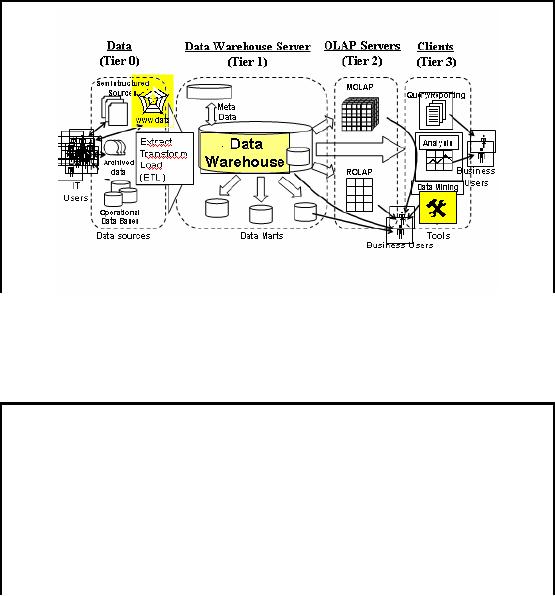
Web
Dat
Figure-39.2:
Putting pieces together
Web warehousing
In case of
Web warehousing, Figure 39.1
has been slightly modified
to highlight components
the
major components
needed, as shown in Figure 39.2. Here
the main source i.e. data
source is the
World
Wide Web. The central
repository Data Warehouse has
changed to a Web data
warehouse
and
data mining tools are
customized to cater for the
semi structured and dynamic
web data.
Background
Internet population
stands at around a billion
users.
Exponential
growth rate of web and size.
Indexable web is more than 11.5
billion pages (Jan
2005).
Adoption
rate of intranet & extranet
warehouse having similar growth
rate
Web
enabled versions of tools are available,
but adoption differ.
Media is div
erse and other than only
data i.e. text, image, audio
etc.
We are
all familiar with the
growth rate of the public
Web. Regardless of the
metric used to
measure
its growth attached
networks, servers, users or
pages the growth rate
continues to
exhibit a n
exponential pattern. In the same
vein, the adoption rate of intranet
and extranet data
warehouses
(i.e., Web warehouses) has
exhibited a similar pattern, although the
pattern has
lagged
public adoption. While data
warehouse and business intelligence
vend ors have offered
Web-enabled
versions of their tools for
the past few years,
and the sales of their Web
offerings
began to
substantially exceed the
sales of their traditional client/server
versions. However, the
patterns of
adoption differ by more than
a simple lag.
The
media delivered by a Web
warehouse include not only data, but
text, graphics, image,
sound,
video,
and other forms as
well.
327

Reasons
for web
warehousing
1. Searching
the web (web mining).
2. Analyzing
web traffic.
3. Archiving
the web.
The
three reasons for warehousing
web data are as listed in
the slide. First, web
warehousing can
be used to mine
the huge web content
for searching information of
interest. Its like searching
the
golden needle
from the haystack. Second
reason of Web warehousing is to analyze
the huge web
traffic.
This can be of interest to
Web Site owners, for
e-commerce, for e-advertisement
and so
on.
Last but not least reason of
Web warehousing is to archive the
huge web content because
of
its dynamic
nature. As we proceed we will
discuss all theses concepts
in further detail.
Web
searching
Web is
large, actually very
large.
To make it
useful must be able to find
the page(s) of
interest/relevance.
How
can the search be
successful?
Three major
types of searches, as
follows:
1. Keyword-based
search
2.
Querying deep Web
sources
3. Random
surfing
The
success of google
The
Web--an immense and dynamic
collection of pages that includes
countless hyperlinks and
huge volumes of
access and usage
information--provides a rich and
unprecedented data
mining
source.
How can a search identify
that portion of the Web
that is truly relevant to
one user's
interests?
How can a search find
high-quality Web pages on a
specified topic?
Currently,
users can choose from
three major approaches when
ac cessing information stored
on
the
Web:
(i)
Keyword -based search or topic -directory
browsing with search engines
such as Google or
Yahoo, which
use keyword indices or manually
built directories to find
documents with specified
keywords or
topics;
(ii)
Querying deep Web
sources--where
information, such as amazon.com's book
data and
realtor.com's
real-estate data, hides behind
searchable database query forms
--that, unlike the
surface
Web, cannot be accessed through
static URL links; and
(iii)Random
surfing that
follows Web linkage
pointers.
The
success of these techniques,
especially with the more
recent page ranking in Google
and
other
search engines shows the
Web's great promise to become
the ultimate information
system.
328

Drawbacks
of traditional web sear
ches
1. Limited to
keyword based
matching.
2. Can
not distinguish between the
contexts in which a link is
used.
3. Coupling of
files has to be done
manually.
Data warehousing
concepts are being applied over
the Web today.
Traditionally, simple
search
engines have
been used to retrieve
information from the Web.
These serve the basic
purpose of
data recovery,
but have several drawbacks. Most of these
engines are based on keyword
searches
limited to
string matching only. That narrows
down our retrieval options.
Als o we have links, at
times several
levels of them in a particular context.
But simple search engines do
not do much
justice to
obtaining information present in these
links. They provide direct information
recovery,
but not enough
indirect link information. Also if we
have files related to
certain subjects and
need
to couple
these, the coupling has to
be done manually. Web search
engines do not provide
mechanisms to
incorporate the above features. These
and other reasons have led to
further
research in
the area of Web knowledge discovery
and have opened the window
to the world of
Web
Warehousing..
Why
web warehousing-Reason no.
1?
Web
data is unstructured and
dynamic, keyword search is
insufficient.
To increase
usage of web, must make it
more comprehensible.
Data
Mining is required for understanding
the web.
Data
mining used to rank and find
high quality pages, thus making
most of search time.
The
Web with billions of Web
pages provides a fertile
ground for data mining.
However,
searching,
comprehend ing, and using
the semi structured
information stored on the
Web poses a
significant
challenge because this data
is more sophisticated and dynamic
than the information
that
commercial database systems
store.
To supplement
keyword -based indexing, which forms
the cornerstone for Web
search engines,
researchers have
applied data mining to Web
-page ranking. In this context,
data mining helps
Web
search engines find high
-quality Web pages and
enhances Web clickstream
analysis. For the
Web to
reach its full potential,
however, we must improve its
services, make it
more
comprehensible,
and increase its usability.
As researchers continue to develop
data mining
techniques, we
believe this technology will
play an increasingly important role in
meeting the
challenges of
developing the intelligent
Web.
329

Why
web warehousing-Reason no.
2?
Web
log contains wealth of information, as it
is a key touch point.
Every
customer interaction is
recorded.
Success of email
or other marketing campaign can be
measured by integrating with
other
operational
systems.
Common
measurements are:
·
Number of
visitors
· Number
of sessions
·
Most
requested pages
·
Robot
activity
·
Etc.
The
Web log contains a wealth of
information about the
company Web site, a touch
point for e -
business.
The Web log, or clickstream,
gathers this information by recording
every interaction a
customer or
potential customer has with
the business over the
Internet. The success of a
specific
e-mail,
marketing or ad campaign can be directly
measured and quantified by integrating
the Web
log
with other operational systems such as
sales force automation (SFA),
customer relationship
management
(CRM) and enterprise
resource planning (ERP)
applications.
Common
measurements include number of visitors, number of
sessions, most requested
page,
most
requested download, most accessed
directories, leading referrer sites,
leading browser and
operating
system, visits by geographic breakdown,
and many others. This
information can be
used to
modify the design of the
Web site, change ad
campaigns or develop partnering
relationships
with other sites. While
these metrics are insightful
and important for managing
the
corporate
e-business on a short term or tactical
basis, the real value of
this knowledge comes
through integration of
this e-resource with other
customer touch-point
information.
Why
web warehousing-Reason no.
3?
Shift
from distribution platform to a general
communication platform.
New
uses from e-government to e
-commerce and new forms of
art etc. between different levels
of
society.
Thus web is
worthy to be archived to be used
for several other
projects.
Such as
snapshots of preserving
time.
In recent
years, we have seen not only
an incredible growth of the
amount of information
available on
the Web, but also a sh ift
of the Web from a platform
for distributing
information
among
IT-related persons to a general
platform for communication
and data exchange at all
levels
of society.
The Web is being used as a
source of information and
entertainment; forms the
basis
for e-government
and e-commerce; has inspired
new forms of art; and serves
as a general
platform
for meeting and
communicating with others
via various discussion forums. It
attracts
and
involves a broad range of groups in
our society, from school
children to professionals of
various
disciplines to seniors, all forming
their own unique communities on
the Web. This
situation
gave rise to the recognition of
the Web's worthiness of being archived,
and the
330
subsequent
creation of numerous projects
aiming at the creation of
World Wide Web
archives.
Snapshot
-like copies of the Web
preserve an impression of what hyperspace looked
like at a
given
point in time, what kind of
information, issues, and
problems people from all
kinds of
cultural and
sociological backgrounds were interested
in, the means they
used to communicate
their
interests over the Web,
characteristic styles of how
Web sites were designed to
attract
visitors, and
many other facets of this
medium.
How Client
Server interactions take
place?
§
Understanding
the interactions essential
for understanding the source
and meaning of the
data in
the clickstream
§
Sequence of
actions for the browser and
Web site interaction using
HTTP
Understanding
the interactions between a
Web client (browser) and a
Web server (W eb site) is
essential
for understanding the source
and meaning of the data in
the clickstream. In Figure
in
next
slide, we show a browser, designated
"Visitor Browser." We'll
look at what happens in
a
typical
interaction from the
perspective of a browser user. The
browser and Web site
interact with
each
other across the Internet
using the Web's
communication protocol -the Hypertext
Transfer
Protocol
(HTTP).
How Client
Server interactions take
place?
Illustration
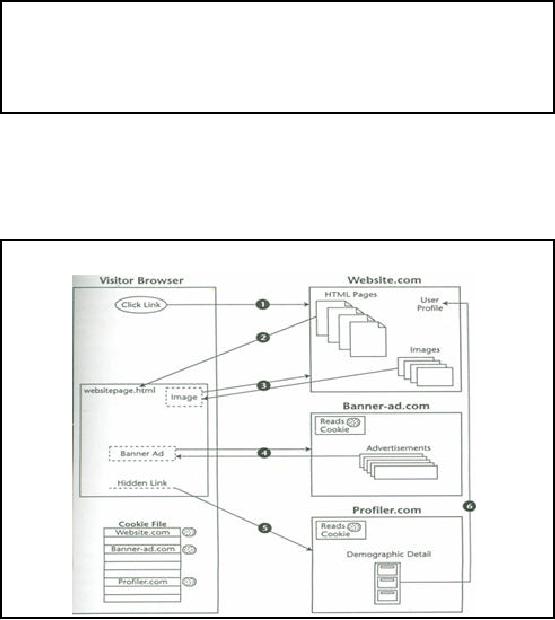
Figure-39.3:
Il lustration of how Client
Server interactions
Figure 39.3
illustrates the steps during a client
server interaction on the WWW.
Each of the
activity or
action has been shown
with a sequence . Lets
briefly look at these
sequence of actions.
331

Action
1
User tries to
access the site using
its URL.
Action
2
The server
returns the requested page,
websitepage.html. Once the
document is entirely retrieved,
the
visitor's browser scans for
references to other Web documents
that it must fulfill before
its
work is
completed. In order to speed up the
response time, most browsers
will execute these
consequential
actions in parallel, typically with up to
4 or more HTTP requests being
serviced
concurrently.
Action
3
The
visitor's browser finds a reference to a
logo imag e that is located at
Website. Com. The
browser issues a
second request to the
server, and the server
responds by returning the
specified
image.
Action
4
The browser
continues to the next
reference for another image
from Banner-ad.com. The
browser
makes
this request, and the server
at Banner -ad.com interprets a
request for the image in a
special
way. Rather
than immediately sending back an
image, the banner-ad server first
issues a cookie
request to
the visitor's browser requesting
the contents of any cookie
that might have been
placed
previously in
the visitor's PC by Banner-ad.com.
There are two options based
on the response of
the
cookie request;
Option
I: Cookie
Request Fulfilled: The
banner-ad Web site retrieves
this cookie and uses
the
contents as a ke
y to determine which banner ad
the visitor should receive.
This decision is
based
on the visitor's
interests or on previous ads.
Once the banner-ad server
makes a determination of
the
optimal ad, it returns the
selected image to the
visitor. The banner-ad
server then logs
which
ad it has
placed along with the date
and the clickstream data
from the visitor's
request.
Option
II:
No
Cookie Found: If thebanner
-ad server had not found its
own cookie, it would
have
sent a
new persistent cookie to the
visitor's browser for future
reference, sent a random
banner ad,
and
started a history in its database of
interactions with the
visitor's browser.
Referrer:
The
HTTP
request
from the visitor's browser to
the banner-ad server carried with it
a
key
piece of informat ion known
as the referrer.
The
referrer is the URL of the
agent responsible
for placing
the link on the page. In
the example the referrer is
Website.com/websitepage.html.
Because
Banner-ad.com now knows who
the referrer was, it can
credit Website. com for
having
placed an
advertisement on a browser window.
Action
5
In the
original HTML document,
websitepage.html had a hidden field
that contained a request
to
retrieve a
specific document from Profiler.com.
When this request reached
the profiler server,
Profiler.com immediately
tried to find its cookie in
the visitor's browser. This
cookie would
contain a
user ID placed previously by
the profiler that is used to
identify the visitor and
serves as
a key to
personal information contained in
the profiler's
database.
Action
6
The
profiler might either return its
profile data to the
visitor's browser to be sent back to
the initial
Web
site or send a real-time notification to
the referrer, Website.com,
via an alternative path
alerting
Website.com that the visitor
is currently logged onto Website. com and
viewing a
specific
page. This information also
could be returned to the HTML
document to be returned to
the
referrer as part of a query string the
next time an HTTP request is
sent to Website.com.
Although
Figu re 39.3 shows three
different sites involved in
serving the contents of
one
document, it is
possible, indeed likely,
that these functions will be
combined into fewer servers.
It
332

is likely
that advertising and profiling
will be done within the
same enterp rise, so a
single request
(and cookie)
would suffice to retrieve
personal information that
would more precisely target
the
ads
that are returned. However, it is equally
possible that a Web page
could contain references to
different
ad/profile services, providing revenue to
the referrer from multiple
sources.
Low
level web traffic
Analysis
Is anyone
coming?
If people
are coming, identify which
pages they are
viewing.
Once you rank
your content, you can tailor
it to satisfy your
visitors.
Detailed
analysis helps increase
traffic, such which sites
are referring visitors.
There
are many reasons why you
might want to analyze your
Web site's traffic. At the
lowest
level, you
want to determine if anyone is coming to
your Web site in order to
justify the site's
existence.
Once you
have determined that people
are indeed visiting your
Web site, the next
step is to
identify
which pages they are
viewing. After determining what content
is popular and what
content is
ignored, you can tailor your
content to sat isfy your
visitors.
High level
web traffic analysis
Combining
your Web site traffic
data with other data sources
to find which banner ad
campaigns
generated
the most revenue vs. just
the most visitors.
Help
calculate ROI on specific
online marketing ca
mpaigns.
Help
get detailed information
about your online customers
and prospects.
A more
detailed analysis of your
Web site traffic will
assist you in increasing the
traffic to your
Web
site. For example, by determining
which sites are referring
visitors to your site, you
can
determine
which online marketing activities are
most successful at driving
traffic to your site.
Or,
by combining
your Web site traffic
data with other data
sources, such as your
customer databases,
you can
determine which banner ad
campaigns, for example,
generated the most revenue
versus
just
the most visitors. This allows you to
calculate the return on investment
(ROI) on specific
online marketing
campaigns as well as get
detailed information about
your online customers
and
prospects.
333

What
information can be
extracted?
Identify
the person by the
originating URL if filled a
form.
Came through
search engine, or referral, if search
engine using which
keyword.
Viewing
which pages, using which
path and how long a
view.
W hich
visitors spent the most
money...
Thus a lot to
discover.
First, you
can determine who is
visiting your Web site.
Minimally, you can determine
what
company
the person is from (the host
computer that they are using to
surf the Web--
ford.com
would be
the Ford Motor Company, for
example). Additionally, if a visitor
filled out an online
form
during a visit to your Web
site, you can link the
form data with his or her
Web site traffic
data
and identify each visitor by
name, address, and phone
number (and any other data that
your
online forms
gather).
You
can also learn where your
visitors are coming from.
For example, did they
find your site by
using a search
engine such as Google or did
they click on a link at another
site? If they did use
a
search engine,
which keywords did they use
to locate your site?
Furthermore, you
can identify which pages
your Web site visitors
are viewing, what paths
they
are taking
within your site, and
how long they are
spending on each page and on
the site. You
can
also
determine w hen they are
visiting your site and
how often they
return.
At the
highest level, you can determine
which of your Web site
visitors spent the most
money
purchasing
your products and services
and what the most common
paths and referring pages
were
for
these visitors.
As you can
see, you can discover a great
deal about your Web
site visitors --and we only
touched
upon a few
introductory topics.
Where
does traffic info. come
from?
1. Log
files.
2.
Cookies.
3. Network
traffic.
4. Page
tagging.
5. ISP (Internet
Service Provider)
6.
Others
To track
traffic on a web
site
http://www.alexa.com/data/details/traffic_details?q=&url=http://www.domain.com
The
principal sources of web
traffic are as
follows:
1. Log
files.
2.
Cookies.
3. Network
traffic.
334

4. Page
tagging.
5.
ISP
Others
We will not
discuss all of them.
ISPs
Besides
log files, we may get
clickstream data from
referring partners or from Internet
service
providers
(ISPs). If we are an ISP
providing Web access to directly
connected customers, we
have a unique
perspective because we see every
click of our familiar
captive visitors that
may
allow
much more powerful and
invasive analysis of the end
visitor's sessions
Others
We also
may get clickstream data
from Web-watcher services that we
have hired to place a
special
control on certain Web pages
that alert them to a visitor opening
the page. Another
important form
of clickstream data is the
search specification given to a search
engine that then
directs
the visitor to the Web
site.
Web
traffic record: Log
files
Connecting to a
web site c onnects to web
sever that serves
files.
Web server
records each action in a
text file.
In raw
log file is useless, as
unstructured and very
large.
Many
formats and types of log
files, can make your own
too.
Analyzers
can be configured to read most
log files.
Web traffic
record: Log file
format
This is
just a portion of the first
12 lines of a 250,000 line
log file (the file
scrolls to the left
for
several more
pages).
This is a 10
megabyte log file and it
represents one day's worth of
traffic to a low volume
Web
site.
Figure-
39.4: A sample Log file
format
Figure
39.4 shows a sample web
log file, indeed a very
small portion of the actual
log file. Here,
12 lines have
been shown and the file
can be scrolled to left to see more
columns. The
335

complexity of dealing
with Web log data
can well be understood , and
mostly Web can be
even
more complex
and huge than this
sample file.
Web
log file formats
Format of web
log dependent on many
factors, such as:
· Web
server
·
Application
·
Configuration options
Several
servers support CLF ECLF
format.
Web
log file formats vary
depending on the Web server application
and configuration
options
selected
during installation. Most Web
server applications (including those
from Apache,
Microsoft
and Nets cape) support
Common Log file Format (CLF,
sometimes pronounced
"clog")
or Extended
Common Log file Format
(ECLF). CLF and ECLF
formats share the same
initial
seven fields,
but ECLF adds referrer
and agent elements.
Web
Log File Formats
Table-39.1:
Web Log File
Formats
Our
example proxy log data file
contained following fields
i. Timestamp
(date in Table 39.1)
ii.
Elapsed Time
This is
the time that transaction
busied the cache. This time
is given in milliseconds. For
the
request where
there was a cache-miss this
time is minimal, where the request
engaged the cache,
this
time is considerable.
iii.
Client Address (host in
Table 39.1)
336

iv.
Log Tag
This
field tells the result of
the cache operation.
v. HTTP
Code (status in Table
39.1)
vi.
Size (bytes in Table
39.1)
vii.
Request Method (request in Table
39.1)
This is
the method which client used
to initiate the request and be
dealt with the proper
treatment
on the
server side.
viii.
URL
This is
the URL which was
request by the client. Therecan be many
variations in the
representation,
start and termination of the
URL.
ix. User Ident
(ident in Table 39.1)
This
field is used to identify
the requesting user on the
network.
x. Hierarchy
Data
This
field provides the hierarchy
data of the request from
the same client in the
current request.
xi.
Content Type
This
field contains the type of
data which was requested.
The values in this field
are the standard
MIME
types which describe the
data contents.
Web
traffic record:
Cookies
Web
log contains one-way traffic
record i.e. server to
client.
No information
about the visitor.
Thus complex
heuristics employed that
analyze links, time etc. to
identify the user.
Cookie is a
small text file generated by
the web server and stored on
the client machine.
This
file is read by the web
server on a repeat visit.
One of
the fundamental flaws of analyzing server
log files is that log
files contain
information
about
files transferred from the server to
the client--not information
about people visiting
the
Web
site. For this reason,
most log analyzers employ
complex heuristics that
analyze the raw
log
data
and make educated guesses
based on the client's hostname or IP
address, the time
between
page
views, the browser type, and
the referring page to
estimate the number of visits that a
site
has received.
While these estimates are
typically good enough, and
often better than metrics
you
can obtain
with traditional media,
sometimes you simply need
more.
A cookie is a small
piece of information generated by
the Web server and stored on
the client
machine.
Advanced Web site analysis
solutions offer the option
to use cookies to get much
more
accurate
visitor counts, while also
allowing analysis of repeat
visitors.
337
Table of Contents:
- Need of Data Warehousing
- Why a DWH, Warehousing
- The Basic Concept of Data Warehousing
- Classical SDLC and DWH SDLC, CLDS, Online Transaction Processing
- Types of Data Warehouses: Financial, Telecommunication, Insurance, Human Resource
- Normalization: Anomalies, 1NF, 2NF, INSERT, UPDATE, DELETE
- De-Normalization: Balance between Normalization and De-Normalization
- DeNormalization Techniques: Splitting Tables, Horizontal splitting, Vertical Splitting, Pre-Joining Tables, Adding Redundant Columns, Derived Attributes
- Issues of De-Normalization: Storage, Performance, Maintenance, Ease-of-use
- Online Analytical Processing OLAP: DWH and OLAP, OLTP
- OLAP Implementations: MOLAP, ROLAP, HOLAP, DOLAP
- ROLAP: Relational Database, ROLAP cube, Issues
- Dimensional Modeling DM: ER modeling, The Paradox, ER vs. DM,
- Process of Dimensional Modeling: Four Step: Choose Business Process, Grain, Facts, Dimensions
- Issues of Dimensional Modeling: Additive vs Non-Additive facts, Classification of Aggregation Functions
- Extract Transform Load ETL: ETL Cycle, Processing, Data Extraction, Data Transformation
- Issues of ETL: Diversity in source systems and platforms
- Issues of ETL: legacy data, Web scrapping, data quality, ETL vs ELT
- ETL Detail: Data Cleansing: data scrubbing, Dirty Data, Lexical Errors, Irregularities, Integrity Constraint Violation, Duplication
- Data Duplication Elimination and BSN Method: Record linkage, Merge, purge, Entity reconciliation, List washing and data cleansing
- Introduction to Data Quality Management: Intrinsic, Realistic, Orrs Laws of Data Quality, TQM
- DQM: Quantifying Data Quality: Free-of-error, Completeness, Consistency, Ratios
- Total DQM: TDQM in a DWH, Data Quality Management Process
- Need for Speed: Parallelism: Scalability, Terminology, Parallelization OLTP Vs DSS
- Need for Speed: Hardware Techniques: Data Parallelism Concept
- Conventional Indexing Techniques: Concept, Goals, Dense Index, Sparse Index
- Special Indexing Techniques: Inverted, Bit map, Cluster, Join indexes
- Join Techniques: Nested loop, Sort Merge, Hash based join
- Data mining (DM): Knowledge Discovery in Databases KDD
- Data Mining: CLASSIFICATION, ESTIMATION, PREDICTION, CLUSTERING,
- Data Structures, types of Data Mining, Min-Max Distance, One-way, K-Means Clustering
- DWH Lifecycle: Data-Driven, Goal-Driven, User-Driven Methodologies
- DWH Implementation: Goal Driven Approach
- DWH Implementation: Goal Driven Approach
- DWH Life Cycle: Pitfalls, Mistakes, Tips
- Course Project
- Contents of Project Reports
- Case Study: Agri-Data Warehouse
- Web Warehousing: Drawbacks of traditional web sear ches, web search, Web traffic record: Log files
- Web Warehousing: Issues, Time-contiguous Log Entries, Transient Cookies, SSL, session ID Ping-pong, Persistent Cookies
- Data Transfer Service (DTS)
- Lab Data Set: Multi -Campus University
- Extracting Data Using Wizard
- Data Profiling