 |
DWH Lifecycle: Data-Driven, Goal-Driven, User-Driven Methodologies |
| << Data Structures, types of Data Mining, Min-Max Distance, One-way, K-Means Clustering |
| DWH Implementation: Goal Driven Approach >> |

Lecture
No. 32
DWH
Lifecycle: Methodologies
Lay
Out the Project
A data warehouse
project is more like scientific
research than anything in traditional
IS!
The normal
Information System (IS)
approach emphasizes on knowing what
the expected results
are
before committing to action. In scientific
research, the results are
unknown up front, and
emphasis is
placed on developing a rigorous,
step-by-step process to uncover
the truth. The
activities
involve regular interactions
between the scientist and
the subject and also
among the
project
participants. It is advised to adopt an exploratory,
hands -on process involving
cross-
disciplinary
participation.
Building a
data warehouse is a very challenging
job because unlike software engineering
it is
quite a young discipline,
and therefore, does not yet
has well-established strategies
and
techniques
for the development process.
Majority of projects fail
due to the complexity of
the
development
process. To date there is no
common strategy for the
development of data
warehouses;
they are more of an art than
science. Current data warehouse
development methods
can
fall within three basic
groups: data -driven,
goal-driven and
user-driven.
Implementation
strategies
· Top
down approach
· Bottom Up
approach
Development
methodologies
· Waterfall
model
· Spiral
model
· RAD
Model
· Structured
Methodology
· Data
Driven
· Goal
Driven
· User
Driven
Implementation
Strategies
Top
Down & Bottom Up approach
: A
Top Down approach is generally useful
for projects where
the
technology is mature and
well understood, as well as where
the business problems that
must
be solved are
clear and well understood. A
Bottom Up approach is useful, on the other
hand, in
making
technology assessments and is a good
technique for organizations
that are not leading
edge technology
implementers. This approach is
used when the business
objectives that are to be
met by
the data warehouse are
unclear, or when the current or proposed
business process will
be
affected by the
data warehouse.
Development
Methodologies
A Development
Methodology describes t e
expected evolution and
management of the
h
engineering
system.
270
Waterfall
Model: The model is a
linear sequence of activities like
requirements definition,
system
design, detailed design, integration
and testing, and finally
operations and
maintenance.
The model is
used when the system
requirements and objectives are
known and clearly
specified.
While
one can use the
traditional waterfall approach to
developing a data warehouse,
there are
several
drawbacks. First and
foremost, the project is likely to
occur over an extended
period of
time,
during which the users
may not have had an opportunity to
review what will be
delivered.
Second, in
today's demanding competitive environment
there is a need to produce
results in a
much
shorter timeframe.
Spiral
Model: The model is a
sequence of waterfall models
which corresponds to a risk
oriented
iterative
enhancement, and recognizes
that requirements are not
always available and clear
when
the
system is first implemented.
Since designing and building
a data warehouse is an iterative
process,
the spiral method is one of
the development methodologies of
choice.
RAD:
Rapid
Application Development (RAD) is an
iterative model consisting of stages
like
scope,
analyze, design, construct,
test, implement, and review. It is
much better suited to
the
development of a
data warehouse because of
its iterative nature and
fast iterations. User
requirements
are sometimes difficult to
establish because business
analysts are too close to
the
existing infra-structure to
easily envision the larger
empowerment that data
warehousing can
offer.
Development and delivery of early
prototypes will drive future
requirements as business
users
are given direct access to
information and the ability
to manipulate it. Management of
expectations
requi res that the
content of the data
warehouse be clearly communicated for
each
iteration.
There
are 5 keys to a successful
rapid prototyping methodology:
1. Assemble a
small, very bright team of
database programmers, hardware
technicians,
designers,
quality as surance technicians,
documentation and decision
support specialists,
and a
single manager.
2. Define
and involve a small "focus
group" consisting of users
(both novice and
experienced)
and managers (both line
and upper). These are the
people who will
provide
the
feedback necessary to drive
the prototyping cycle. Listen to
them carefully.
3. Generate a
user's manual and user
interface first. These will
prove to be amazing in
terms
of user
feedback and requirements
specification.
4. Use
tools specifically designed for rapid
prototyping. Stay away from C,
C++, COBOL,
SQL, etc.
Instead use the visual
development tools included with the
database.
5. Remember a
prototype is NOT the final application.
It servers a means of making
the
user
more expressive about
requirements and developing in
them a clear
understanding
and
vision of the system.
Prototypes are meant to be
copied into production models.
Once
the
prototypes are successful, begin
the development processing using
development tools,
such as C,
C++, Java, SQL,
etc.
Structured
Development: When a project
has more than 10 people
involved or when
multiple
companies
are performing the development, a
more structured development
management
approach is
required. Note that rapid
prototyping can be a subset of
the struct ured
development
approach.
This approach applies a more
disciplined approach to the data
warehouse development.
Documentation
requirements are larger, quality
control is critical, and the number of
reviews
271
increases.
While some parts may
seem like overkill at the
time, they can save a
project from
problems,
especially late in the development
cycle.
Data-Driven
Methodologies: Bill
Inmon, the founder of data
warehousing argues that
data
warehouse
environments are data driven, in
comparison to classical systems,
which have a
requirement
driven development lifecycle. According to Inmon,
requirements are the last
thing to
be considered in
the decision support development
lifecycle. Requirements are
understood
AFTER
the data warehouse has
been populated with data and
results of queries have
been
analyzed by
the end users. Thus the
data warehouse development strategy is
based on the analysis
of the
corporate data model and
relevant transactions. This is an
extreme approach ignoring
the
needs of
data warehouse users a
priori. Consequently company
goals and user requirements
are
not reflected at
all in the first cycle,
and are integrated in the
second cycle.
Goal-Driven
Methodologies: In order to
derive the initial data
warehouse structure,
Böhnlein
and
Ulbrich-vom Ende have
presented a four-stage approach
based on the SOM (Semantic
Object
Model)
process modeling technique.
The first stage determines
goals and services the
company
provides to
its customers. In the second
step, the business process
is analyzed by applying the
SOM interaction
schema that highlights the
customers and their
transactions with the
process
under study. In
third step, sequences of
transactions are transformed into
sequences of existing
dependencies
that refer to information
systems. The last step
identifies measures and
dimensions,
by enforcing
(information request) transactions,
from existing dependencies.
This approach is
suitable
only well when business
processes are designed throughout
the company and
are
combined
with business goals.
Kimball
also proposes a four-step approach
where he starts to choose a
business process,
takes
the
grain of the process, and
chooses dimensions and
facts. He defines a business process as
a
major
operational process in the organization
that is supported by some
kind of legacy system
(or
systems). We
will discuss this in great
detail in lectures 33-34.
User-Driven
Methodologies: Westerman
describes an approach that
was developed at Wal-Mart
and
has its main focus on implementing
business strategy. The methodology
assumes that the
company goal is
the same for everyone and
the entire company will
therefore be pursuing the
same direction.
It is proposed to set up a first
prototype based on the needs of
the business.
Business
people define goals and
gather, priorities as well as
define business questions
supporting
these
goals. Afterwards the
business questions are
prioritized and the most
important business
questions
are defined in terms of data
elements, including the
definition of hierarchies.
Although
t h e Wal-Mart
approach focuses on business
needs, business goals that
are defined by the
organization are
not taken into consideration at
all.
Poe
proposes a catalogue for
conducting user interviews in
order to collect end user
requirements.
She
recommends int erviewing
different user groups in order to
get a complete understanding
of
the
business. The questions
should cover a very broad
field including topics like
job
responsibilities.
WHERE DO
YOU START?
The
majority of successful data
warehouses have started with
a clear understanding of a
business
problem and
the user requirements for
information analysis. It is strongly
recommended that the
team
assembled to create a data
warehouse be comprised of IT
professionals and business
users.
Projects
must have a clearly defined scope
for managing economic and
operational limitations.
272
The
process will be highly
iterative as IT and end
users work toward a
reasonable aggregation
level
for data in the
warehouse.
What
specific Problems the DWH
will solve?
Write
down all the problems. The
problems should be precise, clearly
stated and testable
i.e.
success criteria
is known or can easily be
specified. Make sure to get
user and management
feedback by
publicizing these written
problems.
What
criteria to use to measure
success?
This is an
often overlooked step in the
problem definition. For every problem
stated, you must
define a
means for determining the
success of the solution. If you can't
think of a success
criterion, then
the problem is not defined specifically en
ough. Stay away from
problem
statements
such as "The data warehouse
must hold all our
accounting data." Restate
the problem
in quantifiable
terms, like "The data
warehouse must handle the
current 20GB of accounting
data
including all
metadata and replicated data
with an expected 20% growth
per year."
How to
manage time and
money?
The
first data warehouse (first
iteration's output) should cover a
single subject area and
be
delivered at a
relatively low cost. To minimize
risk, the target platform
should be one where IT
has developed
some infrastructure. Existing technical
skills, operational skills and
database
experience
will help tremendously. The project
must be time boxed, with
guaranteed deliverables
every 90
days, and a project end date
in six to nine m nths. The
overall cost of the first
data
o
warehouse
should be in the $200K to
$500K range, with prototypes
completed for $10K to
$150K in 30 to
60 days (since local companies
keep their costs secret,
costs in dollar are
given
here as an
example). Increment al successes will
drive expansion of existing
data warehouses and
the
funding and creation of
additional ones.
What skills
are required?
The
level of complexity involved in
successfully designing and implementing a
data warehouse
must not be
underestimate d. Time must be
spent to acquire and develop
additional skills for
data
warehousing
developers and users. Some
options are:
· Invest in
just-in-time training (provided by data
warehousing tool vendors)
· Use
pilot projects as seeds for
new technology training
· Develop reward
systems that encourage
experimentation
· Use
outside system integrators
and individual
consultants
As additional
motivation for data warehousing
team members, a new class of
job titles is being
created.
Companies are beginning to
use dedicated titles such
as: Data Warehouse Steward,
Data
Warehouse
Architect, Data Quality Engineer
and Data Warehouse
Auditor.
273
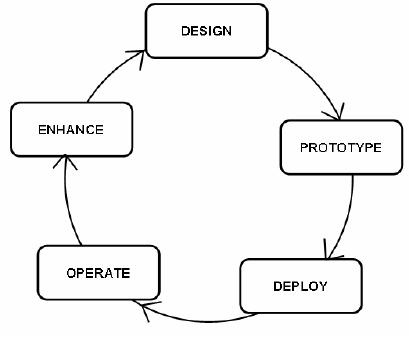
Figure-32.1:
DWH Development
Cycle
Although
specific vocabularies vary from
organization to organization, the data
warehousing
industry is in
agreement of the fundamental data
warehouse lifecycle model as shown in
Figure
32.1.
The cyclic model consists of
5 major steps described as
follows
1.
Design: It involves
the development of robust star-schema
-based dimensional data
models
from
both available data and user
requirements. It is thought that
the best data
warehousing
practitioners
even work with available organizational
data and incompletely expressed
user
requirements.
Key activities in the phase
typically include end -user
interview cycles,
source
system
cataloguing, definition of key
performance indicators and other critical
business
definitions, and
logical and physical schema
design tasks which feed the
next phase of the
model
directly.
2.
Prototype: In this step a
working model of a data warehouse or
data mart design, suitable
for
actual
use, is deployed for a select
group of end users. The
prototyping purpose shifts, as
the
design
team moves design -prototype-design
sub-cycle. Primary objective is to
constrain and /or
reframe end-user
requirements by showing them precisely
what they had asked for in
the previous
iteration. As
difference between stated
needs and actual needs
narrows down over iterations
the
prototyping
shifts towards gaining
commitment to the project at hand
from opinion leaders in
the
end-user
communities to the design,
and soliciting their assistance in gaining
similar
commitment.
3. Deploy:
The
step includes traditional IT system
deployment activities like formalization
of
user
authenticated prototype fo r actual
production use, document development, and
training etc.
Deployment
involves two separate
deployments (i) prototype deployment
into a production test
environment
(ii) Stress- and performance-
tested production configuration
deployment into an
actual
production environment. The phase
also contains the most
important and often
neglected
component of
documentation. Lack of documentation may
stall system operations as
management
274
people
can not manage what they
don't know. Also, it may ultimately be
used for educating
the
end
users, prior to roll
out.
4.
Operation: The
phase includes data
warehouse/mart daily maintenance
and management
activities. The
operations are performed to maintain
data delivery services and
access tools, and
manage
ETL processes that keep
the data warehouse/mart
current with respect to the
authoritative
source
system.
5.
Enhancement: The
step involves modifications of physical
technological components,
operations
and management processes
(ETL etc.) and logical
schema diagrams in response
to
changing
business requirements. In situations of
discontinuous changes, enhancement
moves
back
into the fundamental design
phase.
275
Table of Contents:
- Need of Data Warehousing
- Why a DWH, Warehousing
- The Basic Concept of Data Warehousing
- Classical SDLC and DWH SDLC, CLDS, Online Transaction Processing
- Types of Data Warehouses: Financial, Telecommunication, Insurance, Human Resource
- Normalization: Anomalies, 1NF, 2NF, INSERT, UPDATE, DELETE
- De-Normalization: Balance between Normalization and De-Normalization
- DeNormalization Techniques: Splitting Tables, Horizontal splitting, Vertical Splitting, Pre-Joining Tables, Adding Redundant Columns, Derived Attributes
- Issues of De-Normalization: Storage, Performance, Maintenance, Ease-of-use
- Online Analytical Processing OLAP: DWH and OLAP, OLTP
- OLAP Implementations: MOLAP, ROLAP, HOLAP, DOLAP
- ROLAP: Relational Database, ROLAP cube, Issues
- Dimensional Modeling DM: ER modeling, The Paradox, ER vs. DM,
- Process of Dimensional Modeling: Four Step: Choose Business Process, Grain, Facts, Dimensions
- Issues of Dimensional Modeling: Additive vs Non-Additive facts, Classification of Aggregation Functions
- Extract Transform Load ETL: ETL Cycle, Processing, Data Extraction, Data Transformation
- Issues of ETL: Diversity in source systems and platforms
- Issues of ETL: legacy data, Web scrapping, data quality, ETL vs ELT
- ETL Detail: Data Cleansing: data scrubbing, Dirty Data, Lexical Errors, Irregularities, Integrity Constraint Violation, Duplication
- Data Duplication Elimination and BSN Method: Record linkage, Merge, purge, Entity reconciliation, List washing and data cleansing
- Introduction to Data Quality Management: Intrinsic, Realistic, Orrs Laws of Data Quality, TQM
- DQM: Quantifying Data Quality: Free-of-error, Completeness, Consistency, Ratios
- Total DQM: TDQM in a DWH, Data Quality Management Process
- Need for Speed: Parallelism: Scalability, Terminology, Parallelization OLTP Vs DSS
- Need for Speed: Hardware Techniques: Data Parallelism Concept
- Conventional Indexing Techniques: Concept, Goals, Dense Index, Sparse Index
- Special Indexing Techniques: Inverted, Bit map, Cluster, Join indexes
- Join Techniques: Nested loop, Sort Merge, Hash based join
- Data mining (DM): Knowledge Discovery in Databases KDD
- Data Mining: CLASSIFICATION, ESTIMATION, PREDICTION, CLUSTERING,
- Data Structures, types of Data Mining, Min-Max Distance, One-way, K-Means Clustering
- DWH Lifecycle: Data-Driven, Goal-Driven, User-Driven Methodologies
- DWH Implementation: Goal Driven Approach
- DWH Implementation: Goal Driven Approach
- DWH Life Cycle: Pitfalls, Mistakes, Tips
- Course Project
- Contents of Project Reports
- Case Study: Agri-Data Warehouse
- Web Warehousing: Drawbacks of traditional web sear ches, web search, Web traffic record: Log files
- Web Warehousing: Issues, Time-contiguous Log Entries, Transient Cookies, SSL, session ID Ping-pong, Persistent Cookies
- Data Transfer Service (DTS)
- Lab Data Set: Multi -Campus University
- Extracting Data Using Wizard
- Data Profiling